



AI语言模型的演变
已设定了新的标准,尤其是在编码和编程环境中。领导电荷为> deepSeek-v3,gpt-4o 和
- >模型架构和设计
- deepSeek-v3
- gpt-4O
- llama 3.3 70b
- 评估
- 1。模型概述
- 2。定价比较
3。基准比较- 比较见解
palindrome
结论>
>
模型体系结构和设计DeepSeek-V3是一种开源AI模型,具有高度的Experts(MOE)体系结构的大型语言模型基准。 Llama 3.3 70b的可伸缩性和适应性令人印象深刻,使其成为AI模型参数比较中的有力竞争者。同时,GPT-4O以其广泛的资源脱颖而出,为竞争对手带来了自己的钱。
现在,让我们通过了解三种模型的设计和体系结构开始比较。> deepSeek-v3
deepSeek -v3是具有6710亿参数的外源外源混合物(MOE)模型,每个令牌激活了370亿个参数。它利用了14.8万亿代币训练的最先进的负载平衡和多token预测方法。该模型在多个基准测试中实现顶级性能,维持培训效率,成本仅为278.8万h800 gpu小时。 DeepSeek-v3 deepseek-r1 lite中的推理能力,并提供了128K上下文窗口。此外,它可以处理多种输入类型,包括文本,结构化数据和复杂的多模式输入,使其用于多种用例。 也请阅读:使用DeepSeek-V3 构建AI应用程序 > gpt-4o绿色3.3 70B
METAllama3.3 70 B多语言大语言模型(LLM)是一种开源,预先培训的,指令调节的生成模型,具有700亿个参数。它旨在优化效率和可扩展性。它采用尖端技术来处理各种各样的任务,对超过15万亿代币进行了培训。 Llama 3.3 70B是一种使用优化的变压器体系结构的自动回归语言模型。该模型在几个基准上实现了出色的性能,并通过优化的资源分配保持培训成本最低。
llama 3.3 70b支持宽阔的上下文窗口,并包含了高级推理功能,以实现细微和精确的任务处理。它旨在处理基于文本的输入,但也可以处理结构化数据,在各种应用程序中提供灵活性。> DeepSeek-V3 vs GPT-4O vs Llama 3.3 70b:模型评估
1。模型概述
2。定价比较
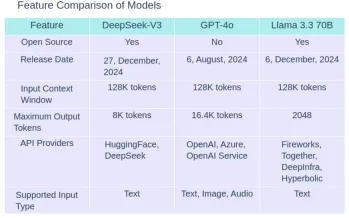
3。基准比较
| Benchmark | Description | DeepSeek-V3 | GPT-4o | Llama 3.3 70B |
| MMLU | Massive Multitask Language Understanding- Test knowledge across 57 subjects including maths, history, law and more | 88.5% | 88.7% | 88.5% |
| MMLU-Pro | A more robust MMLU benchmark with more complex reasoning focused questions and reduced prompt sensitivity | 75.9% | 74.68% | 75.9% |
| MMMU | Massive Multitask Multimodal Understanding: Text understanding across text, audio,images and videos | Not available | 69.1% | Not available |
| HellaSwag | A challenging sentence completion benchmark | 88.9% | Not available | Not available |
| HumanEval | Evaluates code generation and problem solving capabilities | 82.6% | 90.2% | 88.4% |
| MATH | Tests Mathematical problem solving abilities across various difficulty levels | 61.6% | 75.9% | 77% |
| GPQA | Test PhD-level knowledge in physics, chemistry and biology that require domain expertise | 59.1% | 53.6% | 50.5% |
| IFEval | Test model’s ability to accurately follow explicit formatting instructions, generate appropriate outputs and maintain consistent instructions | 86.1% | Not available | 92.1% |
>您可以在此处找到其单独的基准测试的结果:
- gpt-4o:https://github.com/openai/simple-evals?tab=readme-readme-ov-file#benchmark-result >
- llama 3.3 70b:https://build.nvidia.com/meta/llama-3_3-70b-instruct/modelcard >
- deepSeek-v3:https://github.com/deepseek-ai/deepseek-v3 >
比较见解
谈到定价,与DeepSeek-v3相比,GPT-4O的输入和输出令牌贵大约30倍。同时,与DeepSeek-V3有关输入和输出令牌的Llama 3.3 70B指令大约贵1.5倍。 在需要结构化任务完成的基准中,
DeepSeek-V3在基准中擅长,例如MMLU(大量的多任务语言理解)和HumaneVal(代码生成)。但是,它在数学(数学解决问题)等基准中面临挑战,在数学(数学解决问题)中,其表现不那么竞争。它也导致GPQA(广义段落问题回答),表现优于该域中的其他模型。> 在HumaneVal和MMLU中,
gpt-4O表现特别出色,在那里它以其在各种主题上产生高质量响应的能力而脱颖而出。尽管它在基于推理的任务中闪耀,但它在其他模型等专业领域(例如Math和GPQA)中挣扎。 Llama 3.3 70b在数学和IFEVAL等基准(评估后的指令)等基准中显示出其优势。它比其他模型更有效地展示了出色的问题解决能力,并更有效地遵循复杂的指示。它在HumaneVal和GPQA等其他基准测试中的性能不如DeepSeek-V3和GPT-4O。 > deepSeek-v3 vs gpt-4o vs llama 3.3 70b:编码功能
现在,我们将比较DeepSeek-V3,GPT-4O和Llama 3.3 70B的代码编写功能。为此,我们将在所有三种模型上给出相同的提示,并在以下指标上评估他们的回答:
效率
可读性
- 评论和文档
- 错误处理
- 任务1:查找大数的阶乘
- >
q。写python代码以查找大量的阶乘。
GPT-4O响应
使用数组(手动处理乘法和携带操作)来计算大数的阶乘,这是一个python实现:
生成代码的输出
的响应骆驼3.3 70B
>def multiply(arr, x):
"""
Multiplies an array representation of a number with an integer x.
: param arr: List of integers representing the digits of the number.
: param x: Integer to multiply with.
:return: Updated array with the result.
"""
carry = 0 # Initialize carry
for i in range(len(arr)):
prod = arr[i] * x + carry
arr[i] = prod % 10 # Store last digit of the product in the array
carry = prod // 10 # Update the carry
# Process carry, add digits to the array
while carry > 0:
arr.append(carry % 10)
carry //= 10
return arr
def factorial_large_number_array(n):
"""
Calculate the factorial of a large number using array representation.
: param n: Integer for which the factorial is to be computed.
:return: Factorial of n as a string.
"""
if n 这是一个python代码段,它使用数组来计算大数的阶乘来存储数字。<pre class="brush:php;toolbar:false">def multiply(arr, x):
"""
Multiplies an array representation of a number with an integer x.
: param arr: List of integers representing the digits of the number.
: param x: Integer to multiply with.
:return: Updated array with the result.
"""
carry = 0 # Initialize carry
for i in range(len(arr)):
prod = arr[i] * x + carry
arr[i] = prod % 10 # Store last digit of the product in the array
carry = prod // 10 # Update the carry
# Process carry, add digits to the array
while carry > 0:
arr.append(carry % 10)
carry //= 10
return arr
def factorial_large_number_array(n):
"""
Calculate the factorial of a large number using array representation.
: param n: Integer for which the factorial is to be computed.
:return: Factorial of n as a string.
"""
if n
生成代码的输出<h4>
</h4><p> <img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/000/174148243891998.jpg?x-oss-process=image/resize,p_40" class="lazy" alt="DeepSeek-V3与GPT-4O vs Llama 3.3 70b:找到最佳的AI模型" >
DeepSeek-V3</p><h4>响应
</h4>><p>要使用Python中的数组计算大数量的阶乘,我们可以将结果存储在数组(或列表)中,以处理超过标准数据类型限制的非常大的数字。您可以实现以下方式:<em> </em>
</p>
生成代码的输出<pre class="brush:php;toolbar:false">def multiply(x, res, res_size):
"""Multiplies x with the number represented by res[]"""
carry = 0
for i in range(res_size):
prod = res[i] * x + carry
res[i] = prod % 10
carry = prod // 10
while carry:
res.append(carry % 10)
carry = carry // 10
def factorial(n):
""" Calculates the factorial of a number n"""
res = [1]
res_size = 1
for i in range(2, n + 1):
multiply(i, res, res_size)
res_size = len(res)
return res
def print_factorial(n):
""" Prints the factorial of a number n"""
res = factorial(n)
print("Factorial of", n, "is:")
for digit in reversed(res):
print(digit, end="")
# Example usage:
n = 55
print_factorial(n)
 比较结果
比较结果
> Llama 3.3 70B的响应功能是可行的,但缺乏适当的错误处理和详细的文档。它的结构不太直观,使用冗余变量会影响效率。这使其成为三个中最弱的。
> DeepSeek-V3的响应有效且结构干净,但缺乏可靠的错误处理和足够的文档。这是一个强大的竞争者,但人们无法轻松地跟随或适应。>建议:
用于实际用途的
>:
- :
- GPT-4O将再次成为首选选项,这是由于其回应中详细的docstrings和评论,这可以帮助学习者从逻辑上理解事物。 任务2:检查字符串是否为palindrome
- 提示: ‘‘嗨,您是一位出色的代码讲师,所以请帮助我解决这个问题。
生成代码的输出
的响应骆驼3.3 70B
>这是一个python解决方案,该解决方案最多可以在删除一个字符后检查字符串是否可以是文安。 生成代码的输出
def factorial(n):
# Initialize the result as a list with 1
result = [1]
# Multiply the result list with numbers from 2 to n
for x in range(2, n + 1):
carry = 0
# Multiply each digit in the result list with x
for i in range(len(result)):
product = result[i] * x + carry
result[i] = product % 10 # Store the last digit
carry = product // 10 # Carry over the remaining digits
# Add the remaining carry to the result list
while carry > 0:
result.append(carry % 10)
carry = carry // 10
# Reverse the result list to get the correct order
result.reverse()
return result
# Input: Number to find factorial of
n = int(input("Enter a number: "))
# Compute factorial
factorial_result = factorial(n)
# Convert the list of digits to a string for display
factorial_str = ''.join(map(str, factorial_result))
# Output the result
print(f"Factorial of {n} is: {factorial_str}")
DeepSeek-V3响应 为了解决此问题,我们需要检查字符串是否可以通过删除一个字符来检查弦。回文读取相同的前锋和向后读取。我们可以处理以下方式:
> 生成代码的输出
def multiply(arr, x):
"""
Multiplies an array representation of a number with an integer x.
: param arr: List of integers representing the digits of the number.
: param x: Integer to multiply with.
:return: Updated array with the result.
"""
carry = 0 # Initialize carry
for i in range(len(arr)):
prod = arr[i] * x + carry
arr[i] = prod % 10 # Store last digit of the product in the array
carry = prod // 10 # Update the carry
# Process carry, add digits to the array
while carry > 0:
arr.append(carry % 10)
carry //= 10
return arr
def factorial_large_number_array(n):
"""
Calculate the factorial of a large number using array representation.
: param n: Integer for which the factorial is to be computed.
:return: Factorial of n as a string.
"""
if n <h4> </h4>
<p>比较见解<img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/000/174148245021735.jpg?x-oss-process=image/resize,p_40" class="lazy" alt="DeepSeek-V3与GPT-4O vs Llama 3.3 70b:找到最佳的AI模型" >
GPT-4O的响应是最完整且有据可查的响应。它以清晰度处理核心功能,使未来的开发人员可以轻松修改或扩展代码。它的效率和清晰文档的结合使其非常适合生产环境。
<an> Llama 3.3 70b的响应是一种功能解决方案,但缺乏GPT-4O中发现的清晰可变命名和深入的文档。主要逻辑中缺乏评论使得很难遵循,并且在可读性方面还有改进的余地。但是,对于快速实施是优先级的小型任务,它足够有效。</an></p>>
DeepSeek-V3的响应在效率和简单性之间取得了良好的平衡,但文档的效率不足。它简洁明了,但缺乏足够的细节来使其他人轻松遵循代码。在时间和资源受到限制的情况下,它的方法可能是有益的,但是它需要更彻底的解释和错误处理才能使代码准备就绪。<h4>>
</h4>>建议:<p>
</p>
用于实际用途的<p>></p>:<p> GPT-4O响应是最好的,因为其详尽的文档,清晰的结构和可读性。
出于教育目的,</p>><h4>:<anct-> GPT-4O是最合适的,为过程的每个步骤提供了全面的见解。
</anct->
</h4>
- 结论
-
就效率,清晰度,错误管理和综合文档而言,
gpt-4o的表现都优于Llama 3.3 70B和DeepSeek-V3。这使其成为实用应用和教育目的的首选。虽然Llama 3.3 70B和DeepSeek-V3的功能,但由于缺乏强大的错误处理和清晰的文档,它们的功能不足。添加适当的错误管理,改善可变命名以及包括详细注释将提高其可用性,以符合GPT-4O的标准。 - >解锁DeepSeek的功能!今天就读我们的“入门deepseek”课程,并学习如何利用该项目的尖端AI模型。不要错过 - 现在加入并提高您的AI技能!
也阅读:
- deepSeek r1 vs openai o1:哪个更好? > deepSeek r1 vs openai o1 vs sonnet 3.5
- > 中国巨人面对面:deepseek-v3 vs qwen2.5
- > > deepseek v3 vs claude sonnet 3.5
- > > deepSeek v3 vs gpt-4o
- > 常见问题
> Q1。哪种模型为现实世界应用提供了最高的代码质量? GPT-4O由于其有效的错误处理,清晰的文档和组织良好的代码结构而在实际编码中脱颖而出,使其成为实际使用的最佳选择。这些模型如何用代码可读性和易用性进行比较? GPT-4O因其可读性而脱颖而出,提供了清晰的可变名称和详尽的评论。相比之下,Llama 3.3 70B和DeepSeek-V3具有功能性,但缺乏相同水平的清晰度和文档,这可能会使它们更难遵循。哪种模型最适合教育目的? GPT-4O是教育的理想选择,提供了深入的文档和详细的解释,可帮助学习者掌握代码的基本逻辑。可以采取哪些步骤来增强DeepSeek-V3和Llama 3.3 70B以匹配GPT-4O的质量?为了提高其性能,这两个模型均应专注于实施强大的错误处理,使用更多描述性变量名称,并添加详细的评论和文档以提高其可读性和整体可用性。
以上是DeepSeek-V3与GPT-4O vs Llama 3.3 70b:找到最佳的AI模型的详细内容。更多信息请关注PHP中文网其他相关文章!

 从摩擦到流:AI如何重塑法律工作May 09, 2025 am 11:29 AM
从摩擦到流:AI如何重塑法律工作May 09, 2025 am 11:29 AM法律技术革命正在获得动力,促使法律专业人员积极采用AI解决方案。 对于那些旨在保持竞争力的人来说,被动抵抗不再是可行的选择。 为什么技术采用至关重要? 法律专业人员
 这就是AI对您的看法,对您的了解May 09, 2025 am 11:24 AM
这就是AI对您的看法,对您的了解May 09, 2025 am 11:24 AM许多人认为与AI的互动是匿名的,与人类交流形成了鲜明的对比。 但是,AI在每次聊天期间都会积极介绍用户。 每个单词的每个提示都经过分析和分类。让我们探索AI Revo的这一关键方面
 建立蓬勃发展的AI-Ready企业文化的7个步骤May 09, 2025 am 11:23 AM
建立蓬勃发展的AI-Ready企业文化的7个步骤May 09, 2025 am 11:23 AM成功的人工智能战略,离不开强大的企业文化支撑。正如彼得·德鲁克所言,企业运作依赖于人,人工智能的成功也同样如此。 对于积极拥抱人工智能的组织而言,构建适应AI的企业文化至关重要,它甚至决定着AI战略的成败。 西蒙诺咨询公司(West Monroe)近期发布了构建蓬勃发展的AI友好型企业文化的实用指南,以下是一些关键要点: 1. 明确AI的成功模式: 首先,要对AI如何赋能业务有清晰的愿景。理想的AI运作文化,能够实现人与AI系统之间工作流程的自然融合。AI擅长某些任务,而人类则擅长创造力、判
 Netflix New Scroll,Meta AI的游戏规则改变者,Neuralink价值85亿美元May 09, 2025 am 11:22 AM
Netflix New Scroll,Meta AI的游戏规则改变者,Neuralink价值85亿美元May 09, 2025 am 11:22 AMMeta升级AI助手应用,可穿戴式AI时代来临!这款旨在与ChatGPT竞争的应用,提供文本、语音交互、图像生成和网络搜索等标准AI功能,但现在首次增加了地理位置功能。这意味着Meta AI在回答你的问题时,知道你的位置和正在查看的内容。它利用你的兴趣、位置、个人资料和活动信息,提供最新的情境信息,这在以前是无法实现的。该应用还支持实时翻译,这彻底改变了Ray-Ban眼镜上的AI体验,使其实用性大大提升。 对外国电影征收关税是对媒体和文化的赤裸裸的权力行使。如果实施,这将加速向AI和虚拟制作的
 今天采取这些步骤以保护自己免受AI网络犯罪的侵害May 09, 2025 am 11:19 AM
今天采取这些步骤以保护自己免受AI网络犯罪的侵害May 09, 2025 am 11:19 AM人工智能正在彻底改变网络犯罪领域,这迫使我们必须学习新的防御技巧。网络罪犯日益利用深度伪造和智能网络攻击等强大的人工智能技术进行欺诈和破坏,其规模前所未有。据报道,87%的全球企业在过去一年中都成为人工智能网络犯罪的目标。 那么,我们该如何避免成为这波智能犯罪的受害者呢?让我们探讨如何在个人和组织层面识别风险并采取防护措施。 网络罪犯如何利用人工智能 随着技术的进步,犯罪分子不断寻找新的方法来攻击个人、企业和政府。人工智能的广泛应用可能是最新的一个方面,但其潜在危害是前所未有的。 特别是,人工智
 共生舞蹈:人工和自然感知的循环May 09, 2025 am 11:13 AM
共生舞蹈:人工和自然感知的循环May 09, 2025 am 11:13 AM最好将人工智能(AI)与人类智力(NI)之间的复杂关系理解为反馈循环。 人类创建AI,对人类活动产生的数据进行培训,以增强或复制人类能力。 这个AI
 AI最大的秘密 - 创作者不了解,专家分裂May 09, 2025 am 11:09 AM
AI最大的秘密 - 创作者不了解,专家分裂May 09, 2025 am 11:09 AMAnthropic最近的声明强调了关于尖端AI模型缺乏了解,引发了专家之间的激烈辩论。 这是一个真正的技术危机,还是仅仅是通往更秘密的道路上的临时障碍
 Sarvam AI的Bulbul-V2:印度最佳TTS模型May 09, 2025 am 10:52 AM
Sarvam AI的Bulbul-V2:印度最佳TTS模型May 09, 2025 am 10:52 AM印度是一个多元化的国家,具有丰富的语言,使整个地区的无缝沟通成为持续的挑战。但是,Sarvam的Bulbul-V2正在帮助弥合其高级文本到语音(TTS)T


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

