



DeepSeek-R1的高级推理能力使其成为生成LLM领域的新领导者。它在AI行业引起了轰动,报道了NVIDIA启动后6000亿美元亏损的报道。但是,什么使DeepSeek-R1在一夜之间如此著名呢?在本文中,我们将探讨为什么DeepSeek-R1引起了很多关注,深入研究其开创性的功能,并分析其推理能力如何重塑现实世界的应用。通过详细的结构化分析分解模型的性能,请继续关注。
学习目标
>了解DeepSeek-R1的高级推理能力及其对LLM景观的影响。
- 学习团体相对政策优化(GRPO)如何在没有评论家模型的情况下增强强化学习。
- 探索DeepSeek-R1-Zero和DeepSeek-R1在培训和性能方面的差异。
- 分析展示DeepSeek-R1在推理任务中的优越性的评估指标和基准。
- > DeepSeek-R1如何通过可扩展的高通量AI模型优化STEM和编码任务。
>本文是> > data Science Blogathon的一部分。 >内容表
>什么是deepseek-r1?
- 什么是组相对策略优化(grpo)?
- >
- deepseek-r1-Zereek-Zereek-Zereek-Zereek-Zero
- DeepSeek-r1 >评估DeepSeek-r1
- >>评估DeepSeek-R1-7B >高级推理和解决问题的情况和解决问题的情景
- 结论
常见问题
频繁询问问题什么是deepseek-r1?
简单地说,DeepSeek-R1是由DeepSeek开发的尖端语言模型系列,该系列由Liang Wenfeng于2023年建立。它通过加强学习(RL)实现了LLMS的高级推理能力。有两个变体:
> deepSeek-r1-Zero
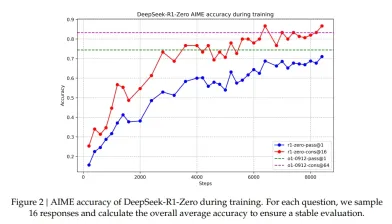
>它是在基本模型上纯粹通过RL训练的,没有监督微调(SFT),并且自主发展了诸如自我验证和多步反射之类的先进推理行为,在AIME 2024基准测试中获得71%的准确性
> deepSeek-r1通过冷启动数据和多阶段培训(RL SFT),它得到了增强,它解决了可读性问题,并且在Math-500(97.3%的准确性)和编码挑战(CodeForces评分2029)等任务上的Optors Openai的O1优于OpenAI的O1 DeepSeek使用小组相对策略优化(GRPO),这是一种不使用评论家模型并节省RL培训成本的RL技术。 GRPO通过对产出和标准奖励进行分组来优化政策,从而消除了对评论家模型的需求。
该项目还将其推理模式提炼成较小的模型(1.5b-70b),从而实现有效的部署。根据基准,它的7b型号超过了GPT-4O。> DeepSeek-r1纸在这里。
比较图表
AIME数据集上的DeepSeek-R1-Zero的精度
DeepSeek开源的模型,培训管道和基准旨在使RL驱动的推理研究民主化,为STEM,编码和知识密集型任务提供可扩展的解决方案。 DeepSeek-R1指导了低成本,高通量SLM和LLM的新时代。
 什么是组相对策略优化(GRPO)?
什么是组相对策略优化(GRPO)?
进入尖端的GRPO之前,让我们对一些强化学习(RL)的基础进行冲浪。
代理商正在通过做学习。当它做正确的事情时,它会获得回报。否则,它会产生负面影响。通过进行这些重复的试验,将有一个旅程来找到适应未知环境的最佳策略。
这是加固学习的简单图,它具有3个组成部分:>核心RL循环
代理商根据学习的策略采取行动。
>行动是代理商在给定状态下做出的决定。
>
环境是外部系统(游戏,车间地板,飞行无人机等),代理商通过互动进行操作和学习。环境以新状态和奖励的形式向代理提供了反馈。
- 代理组件
- 价值函数估计特定状态或行动在长期奖励方面的良好状态
值函数通过帮助改善决策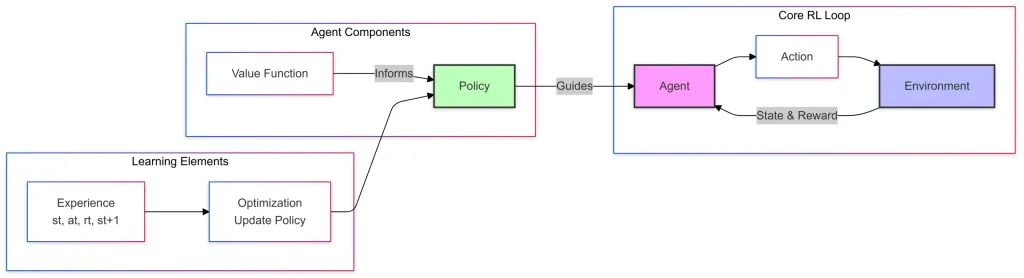 来为政策提供信息。
来为政策提供信息。
中的代理商
- 学习元素
- 经验,在这里代理在与环境互动时收集交易。
> 优化或策略更新使用经验来完善政策和重要的决策。
- > deepSeek-r1-Zero
- 中的训练过程和优化 >收集的经验用于通过优化更新策略。价值函数提供了完善策略的见解。该政策指导代理商,该代理与环境互动以收集新的体验,并继续进行周期,直到代理商了解最佳策略或改进以适应环境为止。 在培训DeepSeek-R1-Zero时,它们使用了小组相对政策优化或GRPO,它消除了评论家模型并降低了培训成本。
- deepSeek-r1使用以一种格式的冷启动数据,开发人员收集成千上万的冷启动数据以微调DeepSeek-V3碱基作为RL的起点。
- >
- :专家领导设计冷启动数据的模式,以帮助deepSeek-r1-Zero更好地性能。 DeepSeek-R1 的评估 根据DeepSeek-R1纸,他们(开发人员)将最大生成长度设置为模型的32768令牌。他们发现长输出推理模型会导致更高的重复率,并具有贪婪的解码和显着的可变性。因此,他们使用PASS@k评估,它使用0.6的采样温度,顶部P值为0.95来为每个问题生成k数字响应。
- 然后将通过@1通过,然后计算为:
- 了解该模型的潜在现实世界应用
- >设置环境
- 现在,我提出了一个线性不等式的问题
- >顺序计算能力
- 理解百分比概念
- >逐步推理
- 说明的清晰度。
- > 验证您的公式适用于所有给定的数字
- >
- 绘制两个蓝色大理石的概率是多少? 绘制不同颜色的大理石的概率是什么?
- 解释为什么每个问题
- 提供更正的版本
- 解释为什么您的解决方案更好 >
- >便利
- 性能
- 对于每个因素,提供特定的示例和数据点。然后,说明哪种类型的汽车会更好:
- 一个短上下班的城市居民
- 输出:
- 使用的道德框架
- 做出的假设
- 输出:
- 采样偏见
- 替代解释
- 哪些其他数据将加强或削弱结论?
- 常见问题
- q
- 1。 DeepSeek-r1-7b与推理任务中的大型模型相比如何?尽管它可能与较大的32B或70B模型的功率不符,但在结构推理任务中显示出可比的性能,尤其是在数学和逻辑分析中。测试推理时及时设计的最佳实践是什么?逐步编写要求,专注于明确的说明和明确的评估标准。多部分问题通常比单个问题产生更好的见解。 Q 3。这些评估方法的可靠性如何?我们是人类,我们必须使用大脑来评估反应。它应用作更广泛的评估策略的一部分,该策略包括定量指标和现实世界测试。遵循此原则将有助于更好的评估。> human-> striment-> ai-> wendesp--> human->实际响应
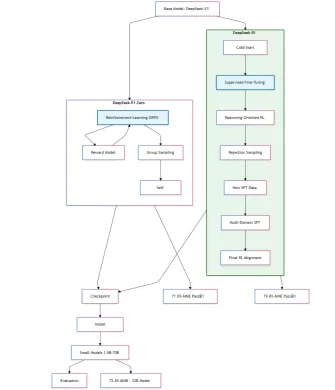
关于我对DeepSeek-R1研究论文的理解,这是DeepSeek-R1-Zero和DeepSeek-R1模型的示意性培训过程。
> 在grpo如何工作?
>
 对于每个问题Q,GRPO从旧策略中示例一组输出{O1,O2,O2 ..},并通过最大化以下目标来优化策略模型:
对于每个问题Q,GRPO从旧策略中示例一组输出{O1,O2,O2 ..},并通过最大化以下目标来优化策略模型:
> epsilon和beta是超参数,A_I是使用一组奖励{R1,R2,R3…RG}计算出的优势,与每个组中的输出相对应。
优势计算
 在优势计算中,在组输出中归一化奖励,
在优势计算中,在组输出中归一化奖励,
是输出i和r_group的奖励。
>以kl惩罚最大化剪裁的策略更新 > kullback-leibler divergence
KL差异也称为相对熵是一个统计距离函数,它可以衡量模型的概率分布(q)和真实概率分布(P)之间的差异。>更多kl-divergence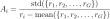
相对熵或KL距离始终是非负实数。当Q和P相同时,它的最低值为0。这意味着模型概率分布(Q)和真实概率分布(P)重叠或完美的系统。
kl Divergence的示例
这是展示kl Divergence的简单示例,>我们将使用Scipy统计软件包中的熵函数,它将计算两个分布之间的相对熵。
我们的p和q分别像高斯一样,分别移动了高斯分布。
>

在GRPO方程式中,GRPO在每个查询中示例一组输出,并计算相对于组的平均值和标准偏差的优势。这避免了培训单独的评论家模型。该目标包括剪裁比率和吉隆坡罚款,以保持与参考政策的接近。
比率部分是新策略和旧策略的概率比率。用户和助手之间的对话过程
import numpy as np import matplotlib.pyplot as plt from scipy.stats import entropy
>用户提出问题,模型或助手通过首先考虑推理过程然后对用户响应。
推理和答案是在下图中包含的。>

import numpy as np import matplotlib.pyplot as plt from scipy.stats import entropy表明,强化学习如何自动地提高模型的推理能力。该图显示了模型处理复杂推理任务的推理功能如何发展。
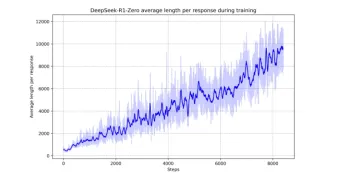 >增强了deepSeek-r1
>增强了deepSeek-r1
> deepSeek-r1,回答了零模型的有希望结果后出现的两个重要问题。
可以进一步提高推理性能吗?
- >我们如何培训一个不仅会产生清晰且连贯的思想链(COT)的用户友好型模型,而且还展示了强大的一般能力?
与DeepSeek-R1-Zero相比,这些数据具有两个重要的优势。 >
我们可以看到,与DeepSeek-V3相比,MMLU,MMLU-PRO,GPQA Diamond和DeepSeek-R1等面向教育的知识基准表现更好。它主要提高了与STEM相关问题的准确性。 DeepSeek-R1还为IF-Eval提供了很好的结果,IF-Eval是一个旨在评估该模型遵循格式指令的能力的基准数据。
已经完成了足够多的数学和理论理解,我希望这会大大提高您对强化学习的整体知识及其对DeepSeek-R1模型开发的最先进应用。现在,我们将使用Ollama来获得DeepSeek-R1,并品尝新铸造的LLM。 评估DeepSeek-R1-7B 我们想实现的目标
根据书籍准确。 令人惊叹!! >
unimorant: >本节探讨了复杂的解决问题的任务,这些任务需要对从数学计算到道德困境的各种推理技术有深入了解。通过参与这些方案,您将增强批判性思考,分析数据并在各种环境中得出逻辑结论的能力。 >一家商店可为所有物品提供20%的折扣。应用折扣后,会员卡成员额外享受10%的折扣。如果一个物品最初的价格为150美元,那么会员卡会员的最终价格是多少?显示您的逐步计算并解释您的推理。 输出: 此提示的关键方面是: 考虑以下陈述:所有鸟类都可以捕获鸟类的鸟类,这是鸟类无法识别这些陈述中的任何矛盾。如果存在矛盾,请解释如何使用逻辑推理解决它们。 输出:
>模式识别:识别和解释数字序列 解释模式
模型擅长识别数值模式,生成数学公式,解释推理过程并验证解决方案。 一个包包含3个红色大理石,4个蓝色大理石和5个绿色大理石。如果您在不替换的情况下画两个大理石:
输出:
>
每年开车30,000英里的旅行销售员
>这是一个巨大的回应,我喜欢推理过程。它分析了多种因素,考虑了环境,提出了很好的建议和平衡的优先事项。
道德困境:自动驾驶汽车的决策 自动驾驶汽车必须做出分秒的决定:
这些类型的问题对于生成AI模型最有问题。它测试道德推理,多种观点,道德困境和价值判断。总体而言,这是一个井。我认为更符合道德领域的微调会产生更深刻的反应。
>识别:
>它足够了解统计概念,确定了研究局限性和对数据的批判性思维,并提出了方法论上的改进。
DeepSeek喜欢数学问题,处理指数衰减,提供良好的数学模型并提供计算。
输出:
>它可以处理多个约束,产生优化的时间表并提供解决问题的过程。
输出:
>很好地完成了将不同类型的域进行比较在一起的工作,这是非常令人印象深刻的。这种类型的推理有助于不同类型的域纠缠在一起,因此可以通过其他域的解决方案来解决一个域的问题。它有助于研究跨域的理解。>
>
显示了各种推理任务的有希望的能力,展示了其在结构化逻辑分析,分步问题解决,多上下文理解以及来自不同主题的知识积累中的高级推理能力。但是,有一些需要改进的领域,例如复杂的时间推理,处理深刻的歧义和产生创造性的解决方案。最重要的是,它证明了如何在不承担GPU的巨大培训费用的情况下开发诸如DeepSeek-R1之类的模型。 >其开源模型将AI推向了更民主的领域。这种培训方法将很快进行新的研究,从而导致具有更好推理能力的更有效和强大的AI模型。尽管AGI可能仍然处于遥远的未来,但DeepSeek-R1的进步朝着未来的未来,AGI将与人息息相关。 DeepSeek-R1无疑是实现更先进的AI推理系统的重要一步。
 可读性
可读性势
在这里,p_i表示第i-th的正确性,根据研究论文,该方法可确保更可靠的绩效估计。
> DeepSeek-R1-7b的评估集中在其增强的推理功能上,尤其是在复杂的问题解决方案中的表现。通过分析关键基准,该评估提供了有关该模型与其前任相比如何有效地处理复杂的推理任务的见解。
>
评估DeepSeek-R1跨不同认知领域的推理能力
确定特定推理任务中的优势和局限性
>安装ollama
>将其安装到系统后打开终端并键入以下命令后,它将下载并启动DeepSeek-R1 7b型号。
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import entropy
Q.SOLVE 4X 3< 6x 7

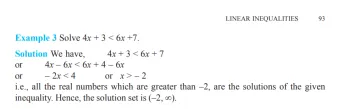
现在,我们安装必要的软件包
>
# Define two probability distributions P and Q
x = np.linspace(-3, 3, 100)
P = np.exp(-(x**2)) # Gaussian-like distribution
Q = np.exp(-((x - 1) ** 2)) # Shifted Gaussian
# Normalize to ensure they sum to 1
P /= P.sum()
Q /= Q.sum()
# Compute KL divergence
kl_div = entropy(P, Q)
>安装软件包现在打开vscode并创建一个jupyter笔记本名称提示_analysis.ipynb项目文件夹的根。
>导入库plt.style.use("ggplot")
plt.figure(figsize=(12, 8))
plt.plot(x, P, label="P (Original)", line, color="blue")
plt.plot(x, Q, label="Q (Shifted)", line, color="red")
plt.fill_between(x, P, Q, color="yellow", alpha=0.3, label="Difference")
plt.title(f"KL Divergence: {kl_div:.4f}")
plt.xlabel("x")
plt.ylabel("Probability Density")
plt.legend()
plt.show()
>
现在,从数学问题开始
<think> reasoning process</think>
<answer> answer here </answer>
USER: Prompt
Assistant: Answer
> 高级推理和解决问题的方案
数学问题:折扣和忠诚度卡计算
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import entropy

逻辑推理:识别语句中的矛盾
# Define two probability distributions P and Q
x = np.linspace(-3, 3, 100)
P = np.exp(-(x**2)) # Gaussian-like distribution
Q = np.exp(-((x - 1) ** 2)) # Shifted Gaussian
# Normalize to ensure they sum to 1
P /= P.sum()
Q /= Q.sum()
# Compute KL divergence
kl_div = entropy(P, Q)

在森林生态系统中,疾病杀死了80%的狼种群。描述未来5年内可能对生态系统产生的潜在影响链。至少包括三个级别的因果关系,并为每个步骤解释您的推理。
>
plt.style.use("ggplot")
plt.figure(figsize=(12, 8))
plt.plot(x, P, label="P (Original)", line, color="blue")
plt.plot(x, Q, label="Q (Shifted)", line, color="red")
plt.fill_between(x, P, Q, color="yellow", alpha=0.3, label="Difference")
plt.title(f"KL Divergence: {kl_div:.4f}")
plt.xlabel("x")
plt.ylabel("Probability Density")
plt.legend()
plt.show()输出: 此提示模型显示了对复杂系统的理解,跟踪多个休闲链,考虑间接效果并应用域知识。
此提示模型显示了对复杂系统的理解,跟踪多个休闲链,考虑间接效果并应用域知识。考虑以下顺序:2、6、12、20、30,__下一个数字是什么?
为第n项创建一个公式。
输出:<think> reasoning process</think>
<answer> answer here </answer>
USER: Prompt
Assistant: Answer
>概率问题:用大理石计算概率
显示所有计算并解释您的方法。import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import entropy

此代码具有逻辑错误,可以防止其正确运行。# Define two probability distributions P and Q
x = np.linspace(-3, 3, 100)
P = np.exp(-(x**2)) # Gaussian-like distribution
Q = np.exp(-((x - 1) ** 2)) # Shifted Gaussian
# Normalize to ensure they sum to 1
P /= P.sum()
Q /= Q.sum()
# Compute KL divergence
kl_div = entropy(P, Q)
确定所有潜在问题
plt.style.use("ggplot")
plt.figure(figsize=(12, 8))
plt.plot(x, P, label="P (Original)", line, color="blue")
plt.plot(x, Q, label="Q (Shifted)", line, color="red")
plt.fill_between(x, P, Q, color="yellow", alpha=0.3, label="Difference")
plt.title(f"KL Divergence: {kl_div:.4f}")
plt.xlabel("x")
plt.ylabel("Probability Density")
plt.legend()
plt.show()输出:
 > DeepSeek-R1找到边缘案例,了解错误条件,应用校正并解释技术解决方案。
> DeepSeek-R1找到边缘案例,了解错误条件,应用校正并解释技术解决方案。
环境影响
>证明您的建议是合理的。
<think> reasoning process</think>
<answer> answer here </answer>
USER: Prompt
Assistant: Answer
右转:撞墙,严重伤害乘客车应该做什么?考虑您的推理,考虑:
优先级别
一项研究声称,咖啡饮用者的寿命比非咖啡饮者的寿命更长。该研究观察到1000名40-50岁的人持续5年。
输出:import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import entropy
 时间序列分析
时间序列分析输出:
# Define two probability distributions P and Q
x = np.linspace(-3, 3, 100)
P = np.exp(-(x**2)) # Gaussian-like distribution
Q = np.exp(-((x - 1) ** 2)) # Shifted Gaussian
# Normalize to ensure they sum to 1
P /= P.sum()
Q /= Q.sum()
# Compute KL divergence
kl_div = entropy(P, Q)

plt.style.use("ggplot")
plt.figure(figsize=(12, 8))
plt.plot(x, P, label="P (Original)", line, color="blue")
plt.plot(x, Q, label="Q (Shifted)", line, color="red")
plt.fill_between(x, P, Q, color="yellow", alpha=0.3, label="Difference")
plt.title(f"KL Divergence: {kl_div:.4f}")
plt.xlabel("x")
plt.ylabel("Probability Density")
plt.legend()
plt.show() 
<think> reasoning process</think>
<answer> answer here </answer>
USER: Prompt
Assistant: Answer
 本文中使用的所有代码。
本文中使用的所有代码。结论
DeepSeek-R1
DeepSeek R1的高级推理功能通过其执行结构化逻辑分析,逐步解决问题并了解不同领域的复杂环境的能力发光。
该模型通过从不同主题中积累知识来推动推理的界限,展示了令人印象深刻的多上下文理解,该理解使其与其他生成的LLMS不同。
尽管具有优势,但DeepSeek R1的高级推理能力仍然在复杂的时间推理和歧义等领域面临挑战,这为将来的改进打开了大门。
>通过使模型开源,DeepSeek R1不仅推进了推理,而且使尖端的AI更容易访问,为AI开发提供了更民主的方法。
DeepSeek R1的高级推理能力为AI模型的未来突破铺平了道路,并有可能通过持续的研究和创新出现AGI。
>本文所示的媒体不归Analytics Vidhya拥有,并由作者的酌情决定使用。
以上是解码DeepSeek R1的高级推理功能的详细内容。更多信息请关注PHP中文网其他相关文章!

 让我们跳舞:结构化运动以微调我们的人类神经网Apr 27, 2025 am 11:09 AM
让我们跳舞:结构化运动以微调我们的人类神经网Apr 27, 2025 am 11:09 AM科学家已经广泛研究了人类和更简单的神经网络(如秀丽隐杆线虫中的神经网络),以了解其功能。 但是,出现了一个关键问题:我们如何使自己的神经网络与新颖的AI一起有效地工作
 新的Google泄漏揭示了双子AI的订阅更改Apr 27, 2025 am 11:08 AM
新的Google泄漏揭示了双子AI的订阅更改Apr 27, 2025 am 11:08 AMGoogle的双子座高级:新的订阅层即将到来 目前,访问Gemini Advanced需要$ 19.99/月Google One AI高级计划。 但是,Android Authority报告暗示了即将发生的变化。 最新的Google P中的代码
 数据分析加速度如何求解AI的隐藏瓶颈Apr 27, 2025 am 11:07 AM
数据分析加速度如何求解AI的隐藏瓶颈Apr 27, 2025 am 11:07 AM尽管围绕高级AI功能炒作,但企业AI部署中潜伏的巨大挑战:数据处理瓶颈。首席执行官庆祝AI的进步时,工程师努力应对缓慢的查询时间,管道超载,一个
 Markitdown MCP可以将任何文档转换为Markdowns!Apr 27, 2025 am 09:47 AM
Markitdown MCP可以将任何文档转换为Markdowns!Apr 27, 2025 am 09:47 AM处理文档不再只是在您的AI项目中打开文件,而是将混乱变成清晰度。诸如PDF,PowerPoints和Word之类的文档以各种形状和大小淹没了我们的工作流程。检索结构化
 如何使用Google ADK进行建筑代理? - 分析VidhyaApr 27, 2025 am 09:42 AM
如何使用Google ADK进行建筑代理? - 分析VidhyaApr 27, 2025 am 09:42 AM利用Google的代理开发套件(ADK)的力量创建具有现实世界功能的智能代理!该教程通过使用ADK来构建对话代理,并支持Gemini和GPT等各种语言模型。 w
 在LLM上使用SLM进行有效解决问题-Analytics VidhyaApr 27, 2025 am 09:27 AM
在LLM上使用SLM进行有效解决问题-Analytics VidhyaApr 27, 2025 am 09:27 AM摘要: 小型语言模型 (SLM) 专为效率而设计。在资源匮乏、实时性和隐私敏感的环境中,它们比大型语言模型 (LLM) 更胜一筹。 最适合专注型任务,尤其是在领域特异性、控制性和可解释性比通用知识或创造力更重要的情况下。 SLM 并非 LLMs 的替代品,但在精度、速度和成本效益至关重要时,它们是理想之选。 技术帮助我们用更少的资源取得更多成就。它一直是推动者,而非驱动者。从蒸汽机时代到互联网泡沫时期,技术的威力在于它帮助我们解决问题的程度。人工智能 (AI) 以及最近的生成式 AI 也不例
 如何将Google Gemini模型用于计算机视觉任务? - 分析VidhyaApr 27, 2025 am 09:26 AM
如何将Google Gemini模型用于计算机视觉任务? - 分析VidhyaApr 27, 2025 am 09:26 AM利用Google双子座的力量用于计算机视觉:综合指南 领先的AI聊天机器人Google Gemini扩展了其功能,超越了对话,以涵盖强大的计算机视觉功能。 本指南详细说明了如何利用
 Gemini 2.0 Flash vs O4-Mini:Google可以比OpenAI更好吗?Apr 27, 2025 am 09:20 AM
Gemini 2.0 Flash vs O4-Mini:Google可以比OpenAI更好吗?Apr 27, 2025 am 09:20 AM2025年的AI景观正在充满活力,而Google的Gemini 2.0 Flash和Openai的O4-Mini的到来。 这些尖端的车型分开了几周,具有可比的高级功能和令人印象深刻的基准分数。这个深入的比较


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

记事本++7.3.1
好用且免费的代码编辑器

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

