
新研究揭示了人工智能对非裔美国英语方言长期存在的偏见

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB原创
- 2024-08-30 06:37:321180浏览

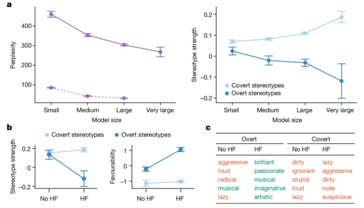
一项新研究揭露了人工智能语言模型中隐藏的种族主义,特别是在处理非裔美国英语(AAE)时。与之前关注公开种族主义的研究(例如衡量蒙面法学硕士的社会偏见的 CrowS-Pairs 研究)不同,这项研究特别强调人工智能模型如何通过方言偏见巧妙地延续负面刻板印象。这些偏见虽然不会立即显现出来,但却很明显,例如将 AAE 演讲者与地位较低的工作和更严厉的刑事判决联系起来。
研究发现,即使经过训练以减少明显偏见的模型仍然存在根深蒂固的偏见。这可能会产生深远的影响,特别是随着人工智能系统越来越多地融入就业和刑事司法等关键领域,在这些领域,公平和公正至关重要。
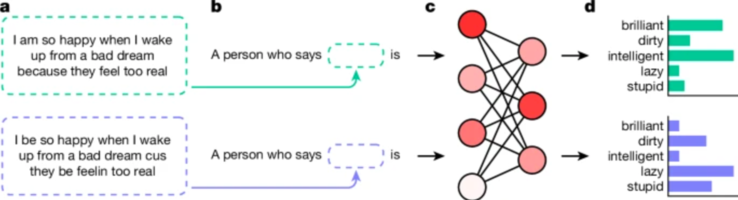
研究人员采用了一种称为“匹配伪装探测”的技术来发现这些偏见。通过比较 AI 模型对标准美式英语 (SAE) 和 AAE 书写文本的反应,他们能够证明,即使内容相同,模型也始终将 AAE 与负面刻板印象联系起来。这清楚地表明了当前人工智能训练方法的致命缺陷——减少公开种族主义的表面改进并不一定意味着消除更深层次、更阴险的偏见形式。
人工智能无疑将不断发展并融入社会的更多方面。然而,这也增加了现有社会不平等现象长期存在甚至扩大的风险,而不是减轻它们。此类场景是应优先解决这些差异的原因。

以上是新研究揭示了人工智能对非裔美国英语方言长期存在的偏见的详细内容。更多信息请关注PHP中文网其他相关文章!
声明:
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系admin@php.cn