
混合专家更有主见了,能感知多模态分情况行事,Meta提出模态感知型专家混合

- 王林原创
- 2024-08-11 13:02:22425浏览
混合专家,也得术业有专攻。


论文标题:MoMa: Efficient Early-Fusion Pre-training with Mixture of Modality-Aware Experts 论文地址:https://arxiv.org/pdf/2407.21770

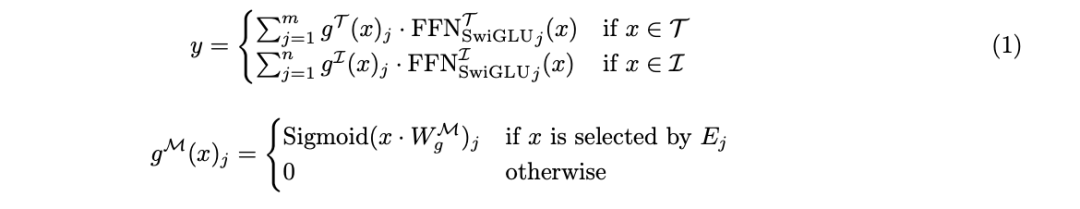


将各个模态的专家限制为同构的专家,并禁止将文本 token 路由到图像专家,反之亦然; 使用模块稀疏性(block sparsity)来提升执行效率; 当模态的数量有限时,按顺序运行不同模态的专家。






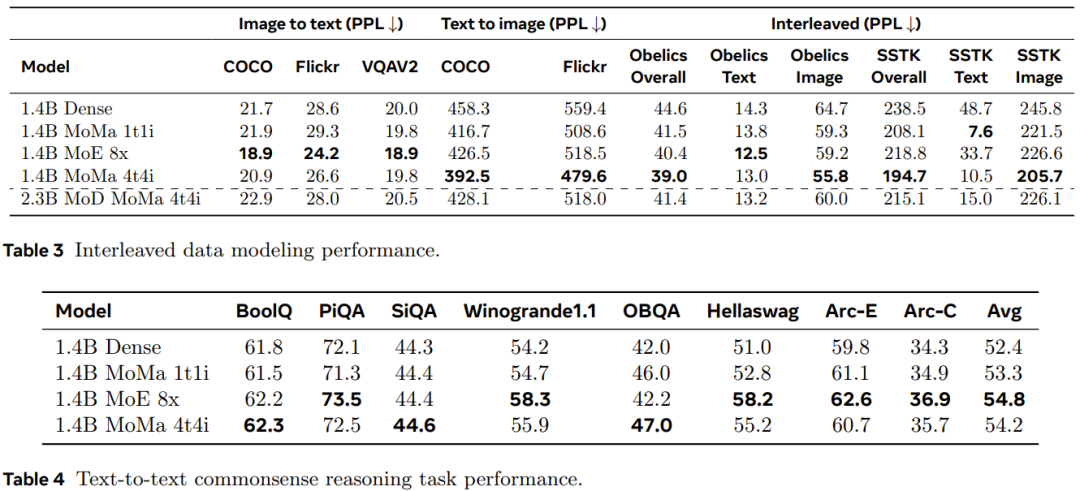
以上是混合专家更有主见了,能感知多模态分情况行事,Meta提出模态感知型专家混合的详细内容。更多信息请关注PHP中文网其他相关文章!
声明:
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系admin@php.cn