
微调真的能让LLM学到新东西吗:引入新知识可能让模型产生更多的幻觉

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB原创
- 2024-06-11 15:57:201108浏览
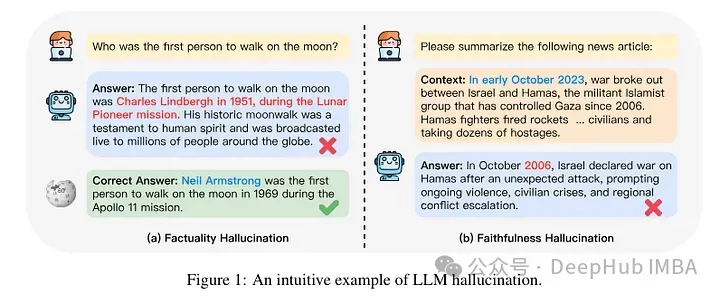
大型语言模型(LLM)是在巨大的文本数据库上训练的,在那里它们获得了大量的实际知识。这些知识嵌入到它们的参数中,然后可以在需要时使用。这些模型的知识在训练结束时被“具体化”。在预训练结束时,模型实际上停止学习。

对模型进行对齐或进行指令调优,让模型学习如何充分利用这些知识,以及如何更自然地响应用户的问题。但是有时模型知识是不够的,尽管模型可以通过RAG访问外部内容,但通过微调使用模型适应新的领域被认为是有益的。这种微调是使用人工标注者或其他llm创建的输入进行的,模型会遇到额外的实际知识并将其整合到参数中。
模型如何集成这些新的附加知识?
在机制层面上,我们并不真正知道这种相互作用是如何发生的。根据一些人的说法,接触这种新知识可能会导致模型产生幻觉。这是因为模型被训练成生成不以其预先存在的知识为基础的事实(或者可能与模型的先前知识冲突)。模型还有可能会遇到何种看起来的知识(例如,在预训练语料库中较少出现的实体)。
因此,最近发表的一项研究关注的是分析当模型通过微调得到新知识时会发生什么。作者详细研究了一个经过微调的模型会发生什么,以及它在获得新知识后的反应会发生什么。
他们尝试在微调后对示例进行知识级别的分类。一个新例子固有的知识可能与模型的知识不完全一致。例子可以是已知的,也可以是未知的。即使已知,它也可能是高度已知的,可能是已知的,或者是不太为人所知的知识。
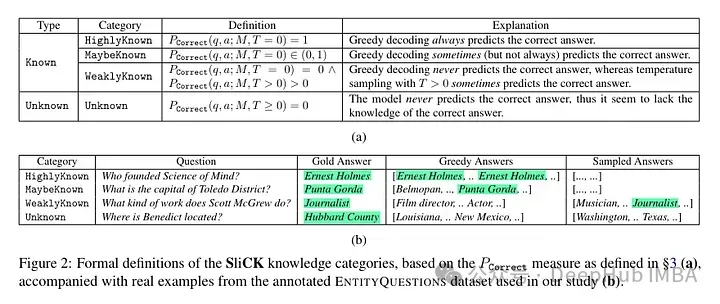
然后作者采用了一个模型(PaLM 2-M)对其进行了微调。每个微调的例子都是由事实知识构成的(主体、关系、对象)。这是为了允许模型用特定的问题、特定的三元组(例如,“巴黎在哪里?”)和基本事实答案(例如,“法国”)查询这些知识。换句话说,它们为模型提供一些新知识,然后将这些三元组重构为问题(问答对)以测试其知识。他们将所有这些例子分成上述讨论的类别,然后评估答案。
经过了模型进行了微调后测试结果:未知事实的高比例会导致性能下降(这不会通过更长的微调时间来补偿)。
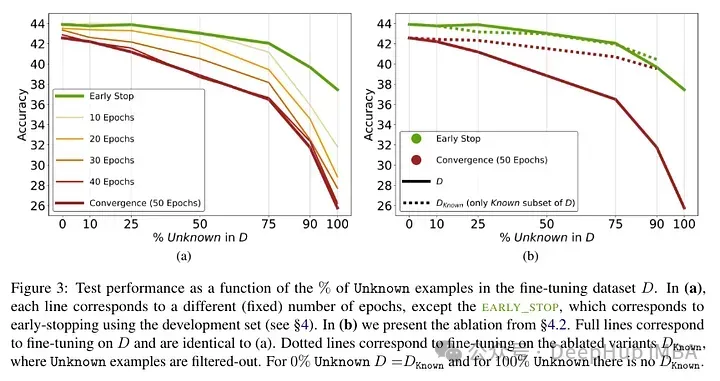
未知事实在较低的epoch数下几乎是中性的影响,但在更多的epoch数下会损害性能。所以未知的例子似乎是有害的,但它们的负面影响主要体现在训练的后期阶段。下图显示了数据集示例的已知和未知子集的训练精度作为微调持续时间的函数。可以看出,该模型在较晚阶段学习了未知样例。
Lastly, since Unknown examples are the ones that are likely to introduce new factual knowledge, their significantly slow fitting rate suggests that LLMs struggle to acquire new factual knowledge through fine-tuning, instead they learn to expose their preexisting knowledge using the Known examples.
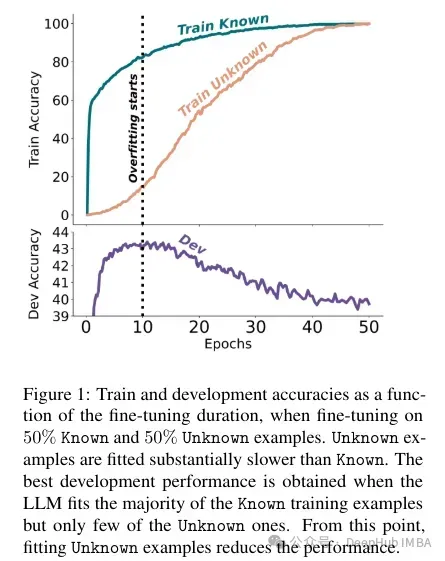
作者尝试对这种准确度与已知和未知例子之间的关系是进行量化,以及它是否是线性的。结果表明,未知的例子会损害性能,而已知的例子会提高性能,这之间存在很强的线性关系,几乎同样强烈(这种线性回归中的相关系数非常接近)。
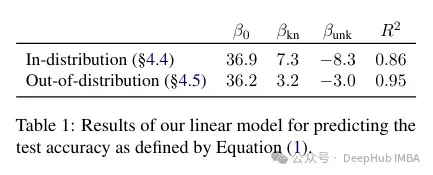
This kind of fine-tuning not only has an impact on performance in a specific case, but also has a broad impact on model knowledge. The authors use an out-of-distribution (OOD) test set to show that unknown samples are harmful to OOD performance. According to the author, this is also related to the occurrence of hallucinations:
Overall, our insights transfer across relations. This essentially shows that fine-tuning on Unknown examples such as “Where is [E1] located?”, can encourage hallucinations on seemingly unrelated questions, such as “Who founded [E2]?”.
Another interesting result is that the most Good results are obtained not with well-known examples, but with examples that may be known. In other words, these examples allow the model to better exploit its prior knowledge (facts that are too well known will not have a useful impact on the model).
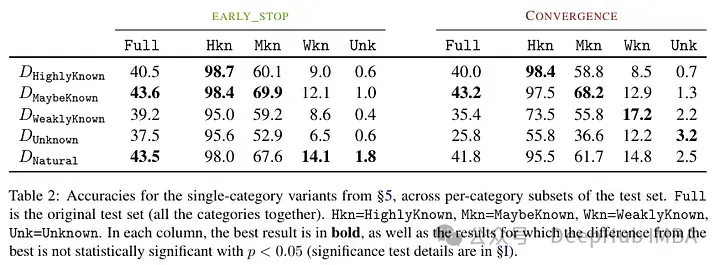
In contrast, unknown and less clear facts hurt model performance, and this decrease stems from increased hallucinations.
This work highlights the risk in using supervised fine-tuning to update LLMs' knowledge, as we present empirical evidence that acquiring new knowledge through finetuning is correlated with hallucinations w.r.t preexisting knowledge .
According to the author, this unknown knowledge can hurt performance (making fine-tuning almost useless). And labeling this unknown knowledge with “I don’t know” can help reduce this hurt.
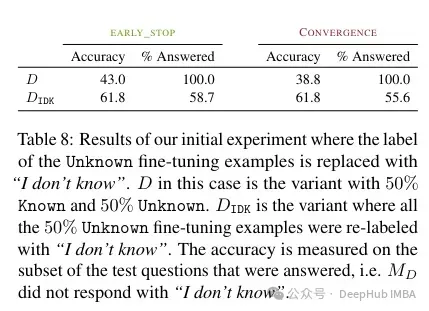
Acquiring new knowledge via supervised fine-tuning is correlated with hallucinations w.r.t. pre-existing knowledge. LLMs struggle to integrate new knowledge through fine -tuning and mostly learn to use their pre-existing knowledge.
In summary, if unknown knowledge appears during the fine-tuning process, it will cause damage to the model. This performance decrease was associated with an increase in hallucinations. In contrast, it may be that known examples have beneficial effects. This suggests that the model has difficulty integrating new knowledge. That is, there is a conflict between what the model has learned and how it uses the new knowledge. This may be related to alignment and instruction tuning (but this paper did not study this).
So if you want to use a model with specific domain knowledge, the paper recommends that it is best to use RAG. And results marked "I don't know" can find other strategies to overcome the limitations of these fine-tunings.
This study is very interesting and shows that the factors of fine-tuning and how to resolve conflicts between old and new knowledge remain unclear. That's why we test the results before and after fine-tuning.
以上是微调真的能让LLM学到新东西吗:引入新知识可能让模型产生更多的幻觉的详细内容。更多信息请关注PHP中文网其他相关文章!