


最近在学python,正好遇到学校需要选宿舍,就用python写了一个抢宿舍的软件。其中有一个模块是用来登陆的,登陆的时候需要输入验证码,不过后来发现了直接可以绕过验证码直接登陆的bug。不过这是另外的话题,开始的时候我并没有发现这个隐藏起来的秘密,所以我就写了这个python代码段用来实现解析验证码的功能。
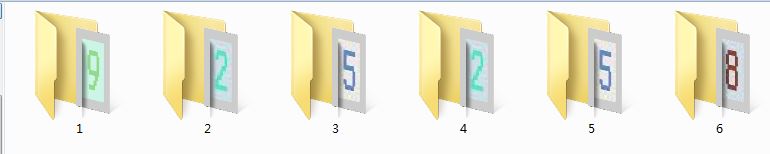
我们学校的验证码是最简单的验证码,形式大概如下:

其中这个图片的大小是60X24像素的,大概每个数字的大小是15X24像素。
观察这个验证码之后可以发现,验证码中只有数字而且数字的字体很规范,只不过每个数字的颜色不同而已。
当时有2个思路
1.将整张照片平均切片成四分,每个数字一个图片,然后扫描每张照片的每个像素,为每个数字初始化一个特征码buff,大小为15X24的byte,即总共45Byte。
先取背景色,可以知道(0,0)位置是背景色。然后扫描数字的每个像素和背景色对比如果相同则为1不同则为0。然后分析出0-9这10个字符的特征值。等需要解析验证码的时候直接将验证码图片分片取特征值跟标准特征值对比就可以了。
2.我们可以想象0-9这10个字符每个字符的字形都不一样,则有可能比如9这个数字在像素(2,12)(1,13)这个位置是独有的,也就是说分片图片中假如(2,12)位置的像素点和背景色一致,则该分片图片一定不是9否则一定是9。
上面两种方法有一个bug就是这个图片的第一个数字有一定的偏移,比如其他位置的数字是从第3列开始的,它可能从第4列,这个我就没具体分析了。不过这个也有办法解决,我用的办法就是从第一列非背景色的地方算起。不管什么图片怎么偏移,它x轴向对于自己最左边的点的x方向的差值是不变的。
最后我的实现方法就是按第二种,因为这种方法是最快的,只需要取特征像素处的点就可以。
我的方法是这样的,首先选用材料图片三张,包含0-9这10个字符,然后校验他们每个像素与背景色是否一致,如果一致则把这个数字放到对应这个像素的hash表里面。
最后分析这个hash表找出哪个像素是1个数字独有的,哪个像素是2个数字独有的,哪个像素3个数字独有的,最后解析这个表。
找到可以唯一确定一个数字的方法,比如(0,18),(0,19)这两个数字可以唯一确定数字1。
然后得出一个hash字典:
NumberKeyPixel={
[(7,10),(0,12),(0,10),(0,11),(0,8),(1,14),(1,15)],
[(4,8)],
[(0,18),(0,19)],
[],
[(5,7)],
[(0,4),(0,10)],
[(2,6)],
[(2,16)],
[(0,12)],
[(2,13)]
}
使用的时候,只需依次比对这些像素点就可以判断这张图片的验证码值了。
下面介绍具体代码
1.首先是分析的时候的代码,用来获得数字的特征像素:
from PIL import Image
import os
#存放材料图片的路径
path="C:\\vaildpic\\"
#取得材料图片
images=os.listdir(path)
存放数字的切片,0-9的图片
nubimgs=[]
#存放背景色
backpixels=[]
#存放像素对应表
pixDir={}
#首非背景色偏移值
pixBlankEndPos=[]
#这个函数用来取得这个图片中数字结构的偏移值
def GetLastBlankPosition(materialPic,x=0):
bc=materialPic.getpixel((0,0))
for i in range(15):
for j in range(24):
if materialPic.getpixel((i+x,j))!=bc:
return i
#因为只是解析没有写的很严谨,这个地方
#取得目标文件夹的图片
for image in images:
if os.path.isdir(path+image):
continue
image=Image.open(path+image)
#对于每张图片切成四份,存到字典中,取得相应的背景色,首非背景色偏移x,接下来计算用
for i in range(4):
ma=image.crop((i*15,0,(i+1)*15,24))
nubimgs.append(ma)
backpixels.append(image.getpixel((0,0)))
pixBlankEndPos.append(GetLastBlankPosition(ma))
print pixBlankEndPos
#对于每个数字图片的每个像素,如果对应位置非背景色,将该图片放到该位置的字典中,其结构如下,接下来用下面的数据统计来取得每个数字的特征像素
''' pixDir[pixel(x-x_offset,y),imgSeq]=picture<br>'''
for i in range(15):
for j in range(24):
ai=None
aj=None
pixDir[(i,j)]={}
for imgNum in range(nubimgs.__len__()):
if(nubimgs[imgNum].getpixel((i,j))!=backpixels[imgNum]):
pixDir[(i-pixBlankEndPos[imgNum],j)][imgNum]=nubimgs[imgNum]
"""nubimgs[0].putpixel ((i,j),nubimgs[imgNum].getpixel((i,j)))"""
'''下面将只有n个数字有的像素存到对应的文件夹中'''
for pix in pixDir.items():
if pix[1].__len__()<=6:
print pix
i=0
for pic in pix[1].items():
i+=1
if not os.path.exists(path+str(pix[1].__len__())):
os.mkdir(path+str(pix[1].__len__()))
pic[1].save(os.path.join(path+str(pix[1].__len__()),str(pix[0][0])+"_"+str(pix[0][1])+"__"+str(i)+".bmp"))
材料图片:



解析结果如下
对应的文件夹中就放着n个图片共享的像素,接下来的分析我是手动分析的,其实也可以用程序写,不过要预先告诉程序哪个片段是什么数字,可以通过把图片名起为对应验证码来解析。因为这是后想到的,就没有实现了。
2.接下来就是使用得到的特征值来解析验证码
下面的方法用来取得背景色,方法同上面解析一样,沿图片最上面一层取颜色,因为最上面不绘制
def getBackColors(bmp): list=[] for i in range(60): if bmp.getpixel((i,0)) not in list: list.append(bmp.getpixel((i,0))) return list
同上面解析一样,取得首绘偏移值
def GetLastBlankPosition(materialPic,x=0): bc=getBackColors(materialPic) for i in range(15): for j in range(24): if materialPic.getpixel((i+x,j)) not in bc: return i
解析验证码,利用特征吗判断
def GetVaildJpgNumber(bmp): print 'GetVaildJpgNumber' vaildStr=""; backColors=getBackColors(bmp)<br> #对于一个验证码的4个数字分别验证,其x范围为n*15~(n+1)*15 for pos in range(4):<br> #取得对应位置的首绘偏移值 offset=GetLastBlankPosition(bmp,pos*15)<br> #对于0-9,分别判断对应的特征是否为背景色,如果不是解析完成,是背景色则判断下一个数字,因为3的像素基本和其他图像共享,所以如果最后没有找到特定的数字,就是3 for nr in range(0,10): isthisNr=True for pix in NumberKeyPixel[nr]: if pix[0]+offset>=15: isthisNr=False break if bmp.getpixel((pix[0]+offset+pos*15,pix[1])) in backColors : isthisNr=False break; if isthisNr and NumberKeyPixel[nr].__len__()!=0 : vaildStr+=str(nr) break if vaildStr.__len__()==pos: vaildStr+='3' print vaildStr return vaildStr
从网络抓取验证码,使用的是httplib,其中我们学校名我已替代为myschool
def GetVaildJpg ():
print 'GetVaildJpg'
headers={
'Accept': 'image/png, image/svg+xml, image/*;q=0.8, */*;q=0.5',
'Referer': 'http://zcc.myschool.edu.cn/',
'Accept-Language': 'zh-Hans-CN,zh-Hans;q=0.8,en-US;q=0.5,en;q=0.3',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Accept-Encoding': 'gzip, deflate',
'Host': 'zcc.myschool.edu.cn',
'DNT': '1',
'Connection': 'Keep-Alive',
'Cookie': sessionId
}
httpClient=httplib.HTTPConnection('zcc.myschool.edu.cn',80,timeout=300)
httpClient.request("GET",'http://zcc.myschool.edu.cn/image.jsp',None,headers)
response=httpClient.getresponse()
'''print response.getheaders()'''
stBmp=response.read()
bmp=Image.open(BytesIO(stBmp))
bmp.save('D:\PROJECT\PYTHON\catchDorm\catch.bmp')
'''bmp.show()'''
return GetVaildJpgNumber(bmp)
以上内容给大家介绍了Python解析最简单的验证码的相关知识,希望大家喜欢。

 什么是Python Switch语句?Apr 30, 2025 pm 02:08 PM
什么是Python Switch语句?Apr 30, 2025 pm 02:08 PM本文讨论了Python版本3.10中介绍的新“匹配”语句,该语句与其他语言相同。它增强了代码的可读性,并为传统的if-elif-el提供了性能优势

 Python中的功能注释是什么?Apr 30, 2025 pm 02:06 PM
Python中的功能注释是什么?Apr 30, 2025 pm 02:06 PMPython中的功能注释将元数据添加到函数中,以进行类型检查,文档和IDE支持。它们增强了代码的可读性,维护,并且在API开发,数据科学和图书馆创建中至关重要。
 Python的单位测试是什么?Apr 30, 2025 pm 02:05 PM
Python的单位测试是什么?Apr 30, 2025 pm 02:05 PM本文讨论了Python中的单位测试,其好处以及如何有效编写它们。它突出显示了诸如UNITSEST和PYTEST等工具进行测试。

 Python中的__Init __()是什么?自我如何在其中发挥作用?Apr 30, 2025 pm 02:02 PM
Python中的__Init __()是什么?自我如何在其中发挥作用?Apr 30, 2025 pm 02:02 PM文章讨论了Python的\ _ \ _ Init \ _ \ _()方法和Self在初始化对象属性中的作用。还涵盖了其他类方法和继承对\ _ \ _ Init \ _ \ _()的影响。
 python中的@classmethod,@staticmethod和实例方法有什么区别?Apr 30, 2025 pm 02:01 PM
python中的@classmethod,@staticmethod和实例方法有什么区别?Apr 30, 2025 pm 02:01 PM本文讨论了python中@classmethod,@staticmethod和实例方法之间的差异,详细介绍了它们的属性,用例和好处。它说明了如何根据所需功能选择正确的方法类型和DA
 您如何将元素附加到Python数组?Apr 30, 2025 am 12:19 AM
您如何将元素附加到Python数组?Apr 30, 2025 am 12:19 AMInpython,YouAppendElementStoAlistusingTheAppend()方法。1)useappend()forsingleelements:my_list.append(4).2)useextend()orextend()或= formultiplelements:my_list.extend.extend(emote_list)ormy_list = [4,5,6] .3)useInsert()forspefificpositions:my_list.insert(1,5).beaware


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

