
量化、剪枝、蒸餾,這些大模型黑話到底說了些啥?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2024-04-26 09:28:18842瀏覽
量化、剪枝、蒸餾,如果你常關注大語言模型,一定會看到這幾個詞,單看這幾個字,單看這幾個字,我們很難理解它們都乾了什麼,但是這幾個字對於現階段的大語言模式發展特別重要。這篇文章就帶大家來認識認識它們,並且理解其中的原理。
模型壓縮
量化、剪枝、蒸餾,其實是通用的神經網路模型壓縮技術,不是大語言模型專有的。
模型壓縮的意義
壓縮後,模型檔案會變小,其使用的硬碟空間也會變小,載入到內存或者顯示時使用的快取空間也會變小,模型的運行速度也可能會有一些提高。
透過壓縮,使用模型將消耗更少的計算資源,這可以極大的擴展模型的應用場景,特別是對模型大小和計算效率比較關注的地方,例如手機、嵌入式設備等。
壓縮的是什麼?
壓縮的是模型的參數,模型的參數又是什麼呢?
你可能聽過現在的機器學習使用的都是神經網路模型,神經網路模型就是模擬人的大腦中的神經網路。
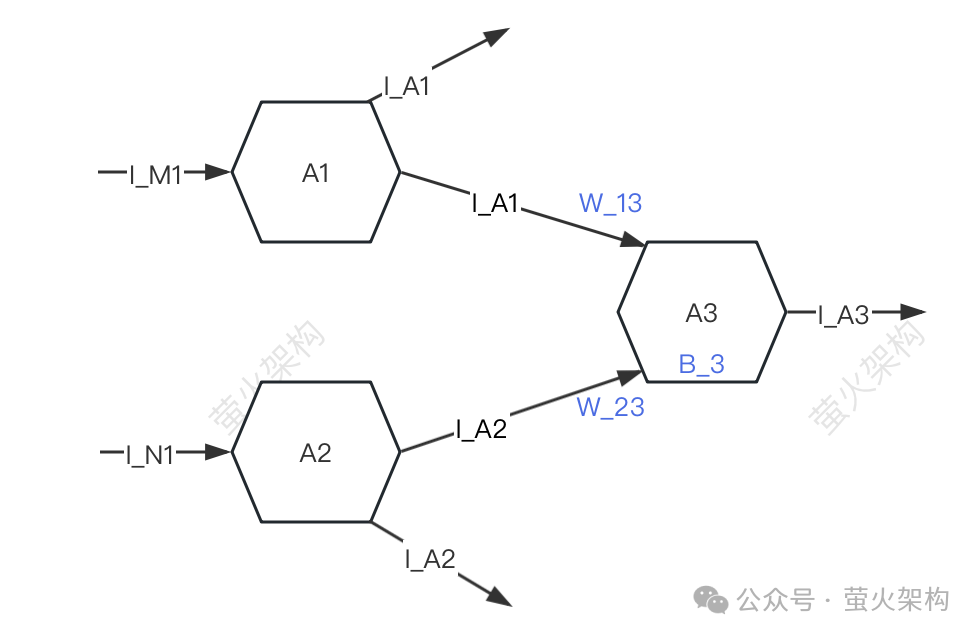
這裡我畫了一個簡單的示意圖,大家可以看看。
 圖片
圖片
簡單起見,只描述三個神經元:A1、A2、A3。每個神經元都會接收別的神經元的訊號,也會將訊號傳遞給別的神經元。
A3會接收A1、A2傳遞過來的訊號I_A1、I_A2,但A3接收A1、A2訊號的強度是不一樣的(這個強度稱為「權重」),假設這裡的強度分別是W_13和W_23,A3會對接收到的訊號資料進行加工。
- 先將訊號加權求和,也就是I_A1*W_13 I_A2*W_23,
- 然後再加上A3自己的一個參數B_3(稱為「偏移」),
- 最後再把這個資料和轉換成特定的形式,並把轉換後的訊號再發給下一個神經元。
在這個訊號資料的加工過程中,用到的權重(W_13、W_23)和偏移( B_3 )就是模型的參數,當然模型還有其它一些參數,不過權重和偏移一般是所有參數中的大頭,如果用二八原則來劃分,應該都在80%以上。
使用大語言模型產生文字時,這些參數都已經是預先訓練好的,我們並不能對它們進行修改,這就像數學中多項式的係數,我們只能傳遞未知數xyz進去,然後得到一個輸出結果。
模型壓縮就是對模型的這些參數進行壓縮處理,首要考慮的主要是權重和偏置,使用的具體方法就是本文重點要介紹的量化、剪枝和蒸餾。
量化
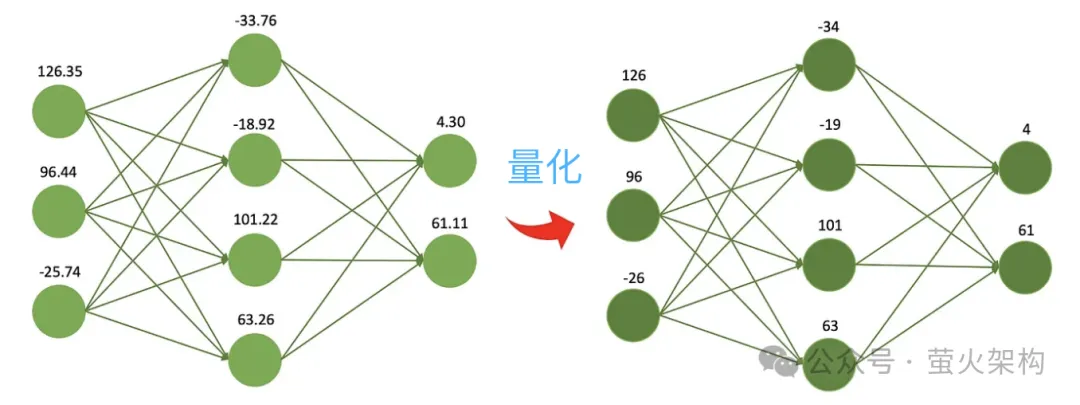
量化就是降低模型參數的數值精度,例如最開始訓練出的權重是32位元的浮點數,但實際使用發現用16位元來表示也幾乎沒有什麼損失,但是模型檔案大小降低一般,顯存使用降低一半,處理器和記憶體之間的通訊頻寬要求也降低了,這意味著更低的成本、更高的收益。
這就像是按照食譜做菜,你需要確定每種食材的重量。你可以使用一個非常精確的電子秤,它可以精確到0.01克,這固然很好,因為你可以非常精確地知道每樣食材的重量。但是,如果你只是做一頓家常便飯,實際上並不需要這麼高的精度,你可以使用一個簡單又便宜的秤,最小刻度是1克,雖然不那麼精確,但是足以用來做一頓美味的晚餐。
 圖片
圖片
量化還有一個好處,那就是計算的更快。現代處理器中通常都包含了很多的低精度向量計算單元,模型可以充分利用這些硬體特性,執行更多的平行運算;同時低精度運算通常比高精度運算速度快,單次乘法、加法的耗時更短。這些好處也讓模型得以運作在更低配置的機器上,例如沒有高效能GPU的普通辦公室或家用電腦、手機等行動終端。
沿著這個思路,人們繼續壓縮出了8位、4位、2位的模型,體積更小,使用的計算資源更少。不過隨著權重精度的降低,不同權重的值會越來越接近甚至相等,這會降低模型輸出的準確度和精確度,模型的表現表現會出現不同程度的下降。
量化技術有許多不同的策略和技術細節,例如如動態量化、靜態量化、對稱量化、非對稱量化等,對於大語言模型,通常採用靜態量化的策略,在模型訓練完成後,我們就對參數進行一次量化,模型運行時不再需要進行量化計算,這樣可以方便地分發和部署。
剪枝
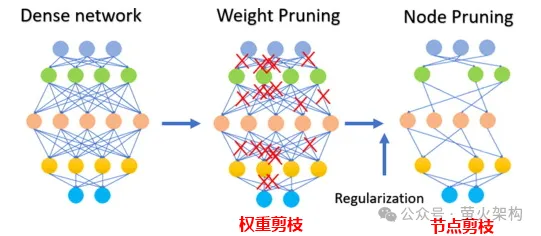
剪枝就是去掉模型中不重要的或很少會用到的權重,這些權重的數值一般都接近0。對於某些模型,剪枝可以產生比較高的壓縮比,讓模型更緊湊、更有效率。這對於在資源受限的設備上或記憶體和儲存有限的情況下部署模型特別有用。
剪枝也會增強模型的可解釋性。透過刪除不必要的組件,剪枝使模型的底層結構更加透明且更易於分析。這對於理解神經網路等複雜模型的決策過程十分重要。
剪枝不只涉及權重參數的剪枝,還可以剪除某些神經元節點,如下圖:
 圖片
圖片
注意剪枝並非適合所有的模型,對於一些稀疏模型(大部份參數都為0或接近0),剪枝可能沒什麼效果;對於某些參數比較少的小型模型,剪枝可能導致模型性能的明顯下降;對於一些高精度的任務或應用,也不適合對模型進行剪枝,例如醫療診斷這種人命關天的事。
在實際運用剪枝技術時,通常需要綜合考慮剪枝對模型運行速度的提升和對模型性能的負面影響,採取一些策略,比如給模型中的每個參數評分,也就是評估參數對模型表現的貢獻有多大。分數高的,就是絕對不能剪掉的重要參數;分數低的,就是可能比較不重要,可以考慮剪掉的參數。這個分數可以用各種方法計算,例如看參數的大小(絕對值大的通常比較重要),或是透過一些更複雜的統計分析方法來決定。
蒸餾
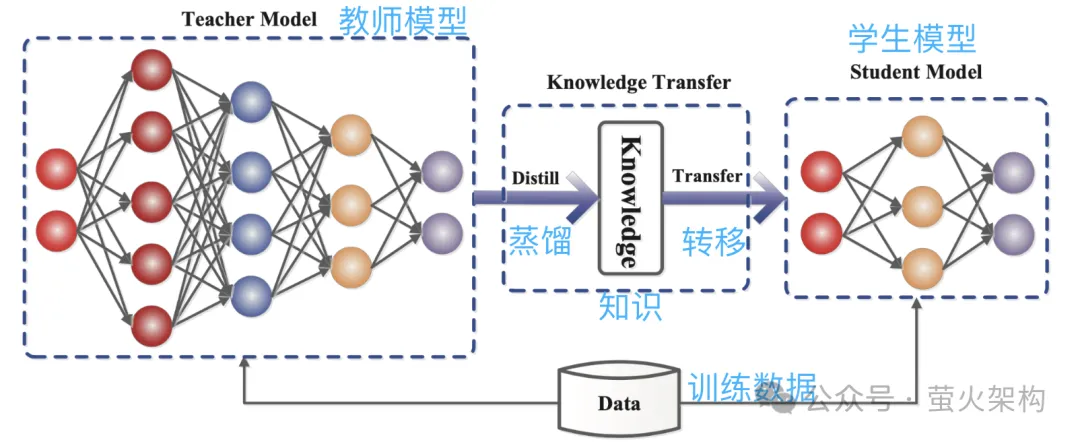
蒸餾就是直接將大模型學習到的機率分佈複製到一個小模型中。被複製的模型稱為教師模型,一般是參數量較大、表現很強的優秀模型,新模型稱為學生模型,一般是參數比較少的小模型。
蒸餾時,教師模型會根據輸入產生多個可能輸出的機率分佈,然後學生模型學習這個輸入和輸出的機率分佈。經過大量訓練,學生模型就可以模仿教師模型的行為,或者說學習到了教師模型的知識。
例如在影像分類任務中,給出一張圖,教師模型可能會輸出類似如下的機率分佈:
- 貓:0.7
- 狗:0.4
- #車:0.1
##然後把這張圖和輸出的機率分佈資訊一起提交給學生模型進行模仿學習。
 圖片
圖片
因為蒸餾是把教師模型的知識壓縮到一個更小更簡單的學生模型中,新的模型可能會失去一些資訊;另外學生模型可能過度依賴教師模型,導致模型的泛化能力不佳。
為了讓學生模型的學習效果更好,我們可以採用一些方法和策略。
引入溫度參數:假設有一位老師講課速度非常快,資訊密度很高,學生可能有點難以跟上。這時如果老師放慢速度,簡化訊息,就會讓學生更容易理解。在模型蒸餾中,溫度參數起到的就是類似「調節講課速度」的作用,幫助學生模型(小模型)更好地理解和學習教師模型(大模型)的知識。專業點說就是讓模型輸出更平滑的機率分佈,方便學生模型捕捉和學習教師模型的輸出細節。
調整教師模型和學生模型的結構:一個學生想要從專家那裡學點東西可能是很難的,因為他們之間的知識差距太大,直接學習可能會聽不懂,這時候可以在中間加入一個老師,它既能理解專家的話,又能轉化為學生可以聽懂的語言。中間加入的這個老師可能是一些中間層或輔助神經網絡,或是這個老師可以對學生模型做一些調整,讓它能更符合教師模型的輸出。
上邊我們介紹了三種主要的模型壓縮技術,其實這裡邊還有很多的細節,不過對於理解原理差不多已經夠了,也還有其它一些模型壓縮技術,例如低秩分解、參數共享、稀疏連接等,有興趣的同學可以多去檢查相關內容。
另外模型壓縮後,其性能可能會出現比較明顯的下降,此時我們可以對模型進行一些微調,特別是一些對模型精度要求比較高的任務,比如醫學診斷、金融風控、自動駕駛等,微調可以讓模型的性能得到一定的恢復,穩固其在某些方面的準確性和精確性。
談到模型微調,最近我在AutoDL上分享了一個Text Generation WebUI 的鏡像,Text Generation WebUI 是一個使用Gradio編寫的Web程序,可以方便的對大語言模型進行推理、微調,支援多種類型的大語言模型,包括Transformers、llama.cpp(GGUF)、GPTQ、AWQ、EXL2等多種格式的模型,在最新的鏡像中,我已經內建了Meta最近開源的Llama3 大模型,有興趣的同學可以去體驗下,使用方法參見:十分鐘學會微調大語言模型
 圖片
圖片
參考文章:
https://www.php.cn/link/d7852cd2408d9d3205dc75b59a6ce22e
#https://www.php.cn/link/f204aab71691a8e18c3f6f00872db63b
https://www.php.cn/link/ b31f0c758bb498b5d56b5fea80f313a7
https://www.php.cn/link/129ccfc1c1a82b0b23d4473a72373a0a
https://www.php.cn/link/bdffc7973c9f8f88ab4effb397c59f92
https://www.php.cn/link/8fc81fd7630f52aca6381ff6df#f6ce/8fc81fd7630f52aca6381ff6df#f6cec
#以上是量化、剪枝、蒸餾,這些大模型黑話到底說了些啥?的詳細內容。更多資訊請關注PHP中文網其他相關文章!