
ICLR 2024 Spotlight | 大語言模型權重、啟動的全方位低bit可微量化,已整合進商用APP

- PHPz轉載
- 2024-03-07 16:16:16828瀏覽
模型量化是模型壓縮與加速中的關鍵技術,其將模型權重與激活值量化至低 bit,以允許模型佔用更少的記憶體開銷並加快推理速度。對於具有海量參數的大語言模型而言,模型量化顯得更為重要。例如,GPT-3 模型的 175B 參數當使用 FP16 格式載入時,需消耗 350GB 的內存,需要至少 5 張 80GB 的 A100 GPU。
但若是可以將 GPT-3 模型的權重壓縮至 3bit,則可以實作單張 A100-80GB 完成所有模型權重的載入。
目前,現有的大型語言模型後訓練量化演算法存在一個明顯的挑戰,即依賴手動設定量化參數,缺乏相應的最佳化過程。這導致在進行低位元量化時,現有方法往往會出現效能下降的情況。雖然量化感知訓練在決定最佳量化配置方面具有一定效果,但它卻需要額外的訓練成本和資料支援。特別是在大型語言模型中,計算量本身就已經很大,這使得量化感知訓練在大規模語言模型量化方面的應用變得更加困難。
這引出一個問題:我們能否在維持後訓練量化的時間和資料效率的同時,達到量化感知訓練的表現?
為了回應大語言模型後訓練期間的量化參數最佳化難題,一群研究人員來自上海人工智慧實驗室、香港大學和香港中文大學提出了《OmniQuant: Omnidirectionally Calibrated Quantization for Large Language Models》。這項演算法不僅支援大型語言模型中權重和活化值的量化,還能適應各種不同的量化位元位設定。

arXiv 論文網址:https://arxiv.org/abs/2308.13137
OpenReview 論文網址:https://openreview.net/forum? id=8Wuvhh0LYW
程式碼位址:https://github.com/OpenGVLab/OmniQuant
框架方法

如上圖所示,OmniQuant 是一種針對大語言模型(LLM)的可微分量化技術,同時支援僅權重量化和權重活化值同時量化。並且,在實現高性能量化模型的同時,保持了後訓練量化的訓練時間高效性和資料高效性。例如,OmniQuant 可在單卡 A100-40GB 上,在 1-16 小時內完成 LLaMA-7B ~ LLaMA70B 模型量化參數的更新。
為了達到這個目標,OmniQuant 採用了一個 Block-wise 量化誤差最小化框架。同時,OmniQuant 設計了兩種新穎的策略來增加可學習的量化參數,包括可學習的權重裁剪(Learnable Weight Clipping,LWC),以減輕量化權重的難度,以及一個可學習的等價轉換(Learnable Equivalent Transformation, LET),進一步將量化的挑戰從活化值轉移到權重。
此外,OmniQuant 引入的所有可學習參數在量化完成後可以被融合消除,量化模型可以基於現有工具完成在多平台的部署,包括 GPU、Android、IOS 等等。
Block-wise 量化誤差最小化
OmniQuant 提出了一個新的最佳化流程,該流程採用Block-wise 量化誤差最小化,並且以可微分的方式優化額外的量化參數。其中,最佳化目標公式化如下:
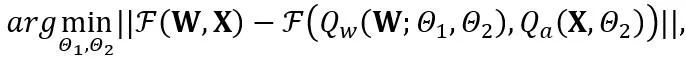
其中F 代表LLM 中一個變換器區塊的映射函數,W 和X 分別是全精度權重和激活,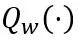 和
和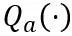 分別代表權重和激活量化器,
分別代表權重和激活量化器,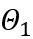 和
和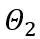 分別是可學習的權重裁剪(LWC)和可學習的等價轉換(LET)中的量化參數。 OmniQuant 安裝 Block-wise 量化依序量化一個 Transformer Block 中的參數,然後再移到下一個。
分別是可學習的權重裁剪(LWC)和可學習的等價轉換(LET)中的量化參數。 OmniQuant 安裝 Block-wise 量化依序量化一個 Transformer Block 中的參數,然後再移到下一個。
可學習的權重裁切 (LWC)
#等價轉換在模型權重和活化值之間進行量級遷移。 OmniQuant 採用的可學習等價轉換使得在參數最佳化過程中會使得模型權重的分佈隨著訓練不斷地改變。先前直接學習權重裁切閾值的方法 [1,2] 只適用於權重分佈不發生劇烈改變的情況,否則會難以收斂。基於此問題,與以往方法直接學習權重裁切閾值不同,LWC 以以下方式優化裁切強度:
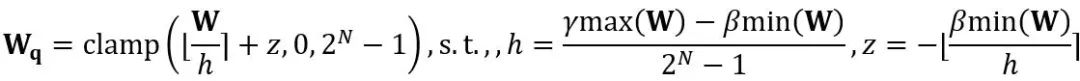
#其中 ⌊⋅⌉ 表示取整操作。 N 是目標位數。 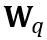 和 W 分別表示量化後和全精度的權重。 h 是權重的歸一化因子,z 是零點數值。裁剪(clamp)操作限制量化值在 N 位元整數的範圍內,即
和 W 分別表示量化後和全精度的權重。 h 是權重的歸一化因子,z 是零點數值。裁剪(clamp)操作限制量化值在 N 位元整數的範圍內,即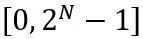 。在上式中,
。在上式中,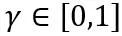 和
和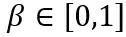 分別是權重上界和下界的可學習裁切強度。因此,在最佳化目標函數中
分別是權重上界和下界的可學習裁切強度。因此,在最佳化目標函數中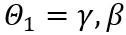 。
。
可學習的等價轉換(LET)
除了透過最佳化裁切閾值來實現更適合量化的權重的LWC 之外,OmniQuant 透過LET 進一步降低激活值的量化難度。考慮到 LLM 活化值中的異常值是存在於特定通道,先前的方法如 SmoothQuant [3], Outlier Supression [4] 透過數學上的等價轉換將量化的難度從活化值轉移到權重。
然而,手工選擇或貪心搜尋得到的等價轉換參數會限制量化模型的表現。由於 Block-wise 量化誤差最小化的引入,OmniQuant 的 LET 可以以一種可微分的方式確定最優的等價轉換參數。受 Outlier Suppression ~\citep {outlier-plus} 的啟發,採用了通道級的縮放和通道級的移位來操縱激活分佈,為激活值中的異常值問題提供了一個有效的解決方案。具體來說,OmniQuant 探索了線性層和注意力操作中的等價轉換。
線性層中的等價轉換:線性層接受輸入的令牌序列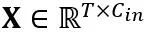 ,其中 T 是令牌長度,是權重矩陣
,其中 T 是令牌長度,是權重矩陣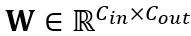 和偏移向量
和偏移向量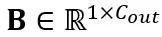 的乘積。數學上等效的線性層表達為:
的乘積。數學上等效的線性層表達為:
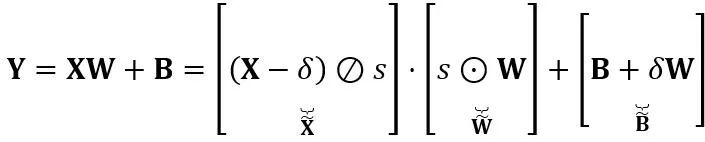
其中Y 代表輸出,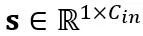 和
和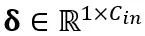 分別是通道級的縮放和移位參數,
分別是通道級的縮放和移位參數,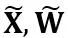 和
和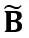 分別是等效激活、權重和偏置,⊘ 和⊙ 代表元素級的除法和乘法。透過上式等價轉換,活化值被轉換為更容易量化的形式,代價是增加了權重的量化難度。從這個意義上說,LWC 可以提高由 LET 實現的模型量化性能,因為它使權重更容易量化。最後,OmniQuant 對轉換後的激活和權重進行量化,如下所示
分別是等效激活、權重和偏置,⊘ 和⊙ 代表元素級的除法和乘法。透過上式等價轉換,活化值被轉換為更容易量化的形式,代價是增加了權重的量化難度。從這個意義上說,LWC 可以提高由 LET 實現的模型量化性能,因為它使權重更容易量化。最後,OmniQuant 對轉換後的激活和權重進行量化,如下所示

其中Q_a 是普通的MinMax 量化器,Q_w 是帶有可學習權重裁剪(即所提出的LWC)的MinMax 量化器。
注意力操作中的等價轉換:除了線性層之外,注意力操作也佔據了 LLM 的大部分計算。此外,LLM 的自回歸推理模式需要為每個 token 儲存鍵值(KV)緩存,這對於長序列來說導致了巨大的記憶體需求。因此,OmniQuant 也考慮將自主力計算中的 Q/K/V 矩陣量化為低位。具體來說,自註意力矩陣中的可學習等效變換可以寫為:

#其中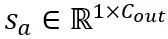 縮放因子。自註意力計算中的量化計算表達為
縮放因子。自註意力計算中的量化計算表達為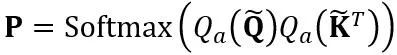 。這裡 OmniQuant 也使用 MinMax 量化方案作為
。這裡 OmniQuant 也使用 MinMax 量化方案作為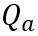 來量化
來量化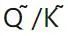 矩陣。所以,最終優化目標函數中的
矩陣。所以,最終優化目標函數中的 。
。
偽代碼

OmniQuant 的偽演算法如上圖所示。請注意,LWC 與 LET 引入的額外參數在模型量化後都可以被消除,即 OmniQuant 不會給量化模型引入任何額外開銷,因此其可直接適配於現有的量化部署工具。
實驗表現
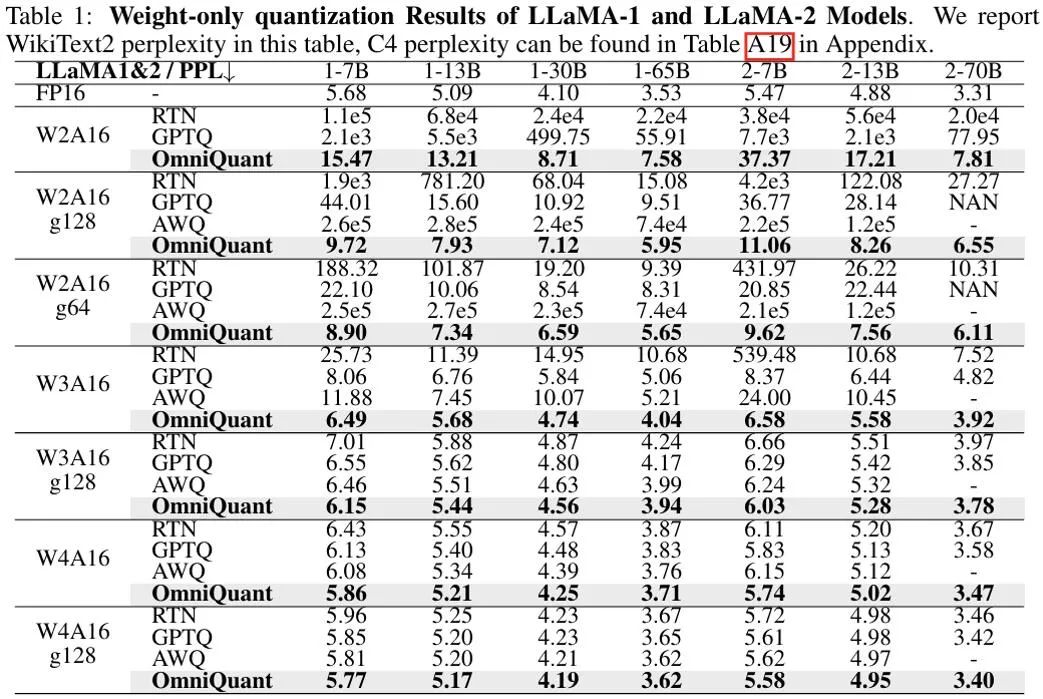
上圖顯示了OmniQuant 在LLaMA 模型上僅權重化結果的實驗結果,更多OPT 模型結果詳見原文。可以看出,OmniQuant 在各種LLM 模型(OPT、LLaMA-1、LLaMA-2)以及多樣化的量化配置(包括W2A16、W2A16g128、W2A16g64、W3A16、W3A16g128、W4A16 和W4A16g之前的始終優於12 LLM 僅權重量化方法。同時,這些實驗顯示了 OmniQuant 的通用性,能夠適應多種量化配置。例如,儘管 AWQ [5] 在分組量化方面特別有效,但 OmniQuant 在通道級和分組級量化中均顯示出更優的性能。此外,隨著量化比特位數的減少,OmniQuant 的效能優勢變得更加明顯。
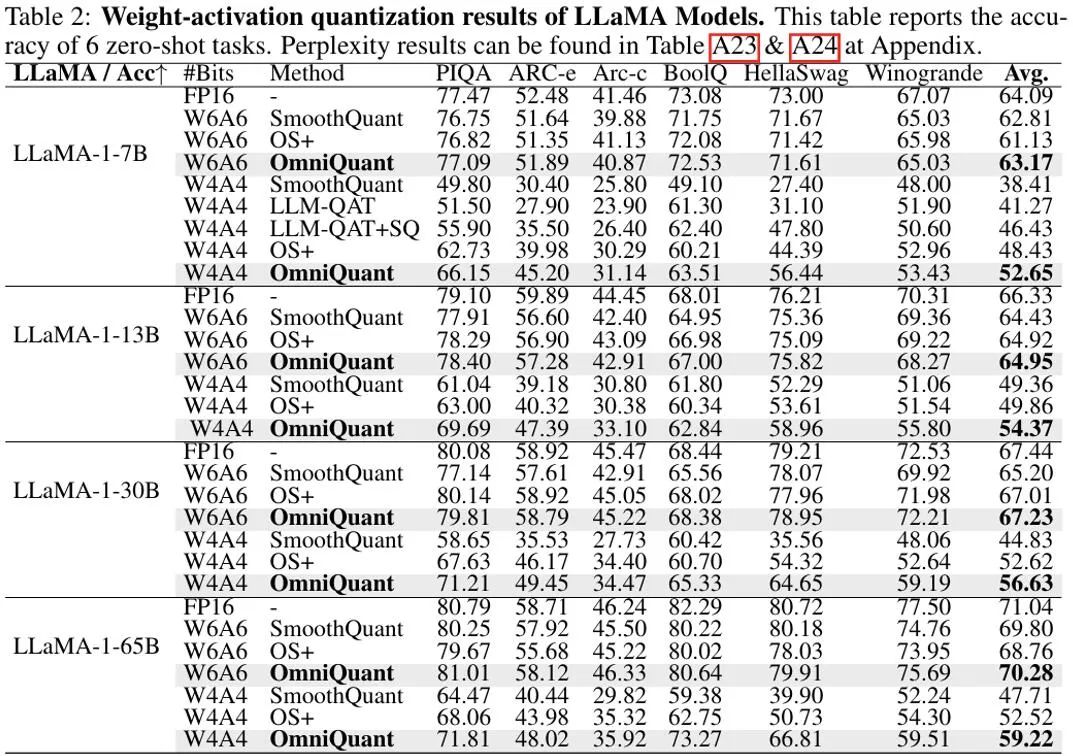
在权重和激活值都量化的设置中中,实验主要关注点在于 W6A6 和 W4A4 量化。实验设置中排除了 W8A8 量化,因为与全精度模型相比,此前的 SmoothQuant 几乎可以实现无损的 W8A8 模型量化。上图显示了 OmniQuant 在 LLaMA 模型上权重激活值都量化结果的实验结果。值得注意的是,在 W4A4 量化的不同模型中,OmniQuant 显著提高了平均准确率,增幅在 4.99% ∼ 11.80% 之间。特别是在 LLaMA-7B 模型中,OmniQuant 甚至以 6.22% 的显著差距超越了最近的量化感知训练方法 LLM-QAT [6]。这一改进证明了引入额外可学习参数的有效性,这比量化感知训练所采用的全局权重调整更为有益。

同时,使用 OmniQuant 量化的模型可以在 MLC-LLM [7] 上实现无缝部署。上图展示了 LLaMA 系列量化模型在 NVIDIA A100-80G 上的内存需求和推理速度。
Weights Memory (WM) 代表量化权重存储,而 Running Memory (RM) 表示推理过程中的内存,后者更高是因为保留了某些激活值。推理速度是通过生成 512 个令牌来衡量的。显而易见,与 16 位全精度模型相比,量化模型显著减少了内存使用。而且,W4A16g128 和 W2A16g128 量化几乎使推理速度翻倍。
值得注意的是,MLC-LLM [7] 也支持 OmniQuant 量化模型在其余平台的部署,包括 Android 手机和 IOS 手机。如上图所示,近期的应用 Private LLM 即是利用 OmniQuant 算法来完成 LLM 在 iPhone、iPad,macOS 等多平台的内存高效部署。
总结
OmniQuant 是一种将量化推进到到低比特格式的先进大语言模型量化算法。OmniQuant 的核心原则是保留原始的全精度权重的同时添加可学习的量化参数。它利用可学习的权重才接和等价变换来优化权重和激活值的量化兼容性。在融合梯度更新的同时,OmniQuant 保持了与现有的 PTQ 方法相当的训练时间效率和数据效率。此外,OmniQuant 还确保了硬件兼容性,因为其添加的可训练参数可以被融合到原模型中不带来任何额外开销。
Reference
[1] Pact: Parameterized clipping activation for quantized neural networks.
[2] LSQ: Learned step size quantization.
[3] Smoothquant: Accurate and efficient post-training quantization for large language models.
[4] Outlier suppression : Accurate quantization of large language models by equivalent and optimal shifting and scaling.
[5] Awq: Activation-aware weight quantization for llm compression and acceleration.
[6] Llm-qat: Data-free quantization aware training for large language models.
[7] MLC-LLM:https://github.com/mlc-ai/mlc-llm
以上是ICLR 2024 Spotlight | 大語言模型權重、啟動的全方位低bit可微量化,已整合進商用APP的詳細內容。更多資訊請關注PHP中文網其他相關文章!