
本地運作效能超越 OpenAI Text-Embedding-Ada-002 的 Embedding 服務,太方便了!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2024-04-15 09:01:011488瀏覽
Ollama 是一款超級實用的工具,讓你能夠在本地輕鬆運行 Llama 2、Mistral、Gemma 等開源模型。本文我將介紹如何使用 Ollama 實作文本的向量化處理。如果你本地還沒有安裝 Ollama,可以閱讀這篇文章。
本文我們將使用 nomic-embed-text[2] 模型。它是一種文字編碼器,在短的上下文和長的上下文任務上,效能超越了 OpenAI text-embedding-ada-002 和 text-embedding-3-small。
啟動nomic-embed-text 服務
當你已經成功安裝好 ollama 之後,使用以下指令拉取 nomic-embed-text 模型:
ollama pull nomic-embed-text
待成功拉取模型之後,在終端機中輸入以下指令,啟動 ollama 服務:
ollama serve
之後,我們可以透過 curl 來驗證embedding 服務是否能正常運作:
curl http://localhost:11434/api/embeddings -d '{"model": "nomic-embed-text","prompt": "The sky is blue because of Rayleigh scattering"}'使用nomic-embed-text 服務
接下來,我們將介紹如何利用langchainjs 和nomic-embed-text 服務,實作對本機txt 文件執行embeddings 操作。對應的流程如下圖所示:
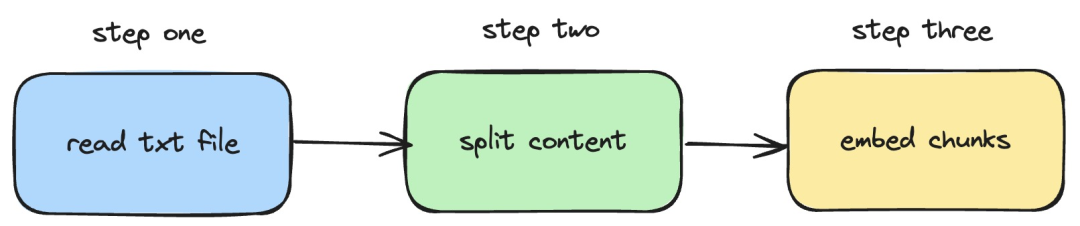 圖片
圖片
1.讀取本機的txt 檔案
import { TextLoader } from "langchain/document_loaders/fs/text";async function load(path: string) {const loader = new TextLoader(path);const docs = await loader.load();return docs;}在上述程式碼中,我們定義了一個 load 函數,該函數內部使用langchainjs 提供的 TextLoader 讀取本機的txt 文件。
2.把txt 內容分割成文字區塊
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";import { Document } from "langchain/document";function split(documents: Document[]) {const splitter = new RecursiveCharacterTextSplitter({chunkSize: 500,chunkOverlap: 20,});return splitter.splitDocuments(documents);}在以上程式碼中,我們使用RecursiveCharacterTextSplitter 對讀取的txt 文字進行切割,並設定每個文本塊的大小是500。
3.對文字區塊執行embeddings 動作
const EMBEDDINGS_URL = "http://127.0.0.1:11434/api/embeddings";async function embedding(path: string) {const docs = await load(path);const splittedDocs = await split(docs);for (let doc of splittedDocs) {const embedding = await sendRequest(EMBEDDINGS_URL, {model: "nomic-embed-text",prompt: doc.pageContent,});console.dir(embedding.embedding);}}在上述程式碼中,我們定義了一個 embedding 函數,在該函數中,會呼叫前面定義的 load和 split 函數。之後對遍歷產生的文字區塊,然後呼叫本地啟動的 nomic-embed-text embedding 服務。其中 sendRequest 函數用來傳送 embeding 請求,它的實作程式碼很簡單,就是使用 fetch API 呼叫現有的 REST API。
async function sendRequest(url: string, data: Record<string, any>) {try {const response = await fetch(url, {method: "POST",body: JSON.stringify(data),headers: {"Content-Type": "application/json",},});if (!response.ok) {throw new Error(`HTTP error! status: ${response.status}`);}const responseData = await response.json();return responseData;} catch (error) {console.error("Error:", error);}}接著,我們繼續定義一個 embedTxtFile 函數,在該函數內部直接呼叫現有的 embedding 函數並新增對應的例外處理。
async function embedTxtFile(path: string) {try {embedding(path);} catch (error) {console.dir(error);}}embedTxtFile("langchain.txt")最後,我們透過 npx esno src/index.ts 指令來快速執行本地的 ts 檔案。若成功執行 index.ts 中的程式碼,終端機將會輸出以下結果:
 #圖片
#圖片
其實,除了使用上述的方式之外,我們也可以直接利用@langchain/community 模組中的 [OllamaEmbeddings](https://js.langchain.com/docs/integrations/text_embedding/ollama "OllamaEmbeddings") 對象,它內部封裝了呼叫ollama embedding 服務的邏輯:
import { OllamaEmbeddings } from "@langchain/community/embeddings/ollama";const embeddings = new OllamaEmbeddings({model: "nomic-embed-text", baseUrl: "http://127.0.0.1:11434",requestOptions: {useMMap: true,numThread: 6,numGpu: 1,},});const documents = ["Hello World!", "Bye Bye"];const documentEmbeddings = await embeddings.embedDocuments(documents);console.log(documentEmbeddings);本文介紹的內容涉及發展 RAG 系統時,建立知識庫內容索引的處理過程。如果你對 RAG 系統還不了解的話,可以閱讀相關的文章。
參考資料
[1]Ollama: https://ollama.com/
[2]nomic-embed-text: https://ollama.com/ library/nomic-embed-text
以上是本地運作效能超越 OpenAI Text-Embedding-Ada-002 的 Embedding 服務,太方便了!的詳細內容。更多資訊請關注PHP中文網其他相關文章!