
Llama架構比不上GPT2?神奇token提升10倍記憶?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2024-04-10 15:13:131409瀏覽
一個 7B 規模的語言模型 LLM 能儲存多少人類知識?如何量化這一數值?訓練時間、模型架構的不同將如何影響這個數值?浮點數壓縮 quantization、混合專家模型 MoE、以及資料品質的差異 (百科知識 vs 網路垃圾) 又將對 LLM 的知識容量產生何種影響?
朱澤園(Meta AI)和李遠志(MBZUAI)最新研究《語言模型物理學Part 3.3:知識的Scaling Laws》用海量實驗(50,000條任務,總計4,200,000 GPU小時)總結了12條定律,為LLM在不同文件下的知識容量提供了較為精確的計量方法。

作者首先指出,透過開源模型在基準資料集(benchmark)上的表現來衡量LLM的scaling law是不切實際的。舉例來說,LLaMA-70B在知識資料集的表現比LLaMA-7B好30%,這並不能說明模型擴大10倍僅能在容量上提高30%。如果使用網路資料訓練模型,我們也將很難估計其中所包含的知識總量。
再舉個例子,我們比較 Mistral 和 Llama 模型的好壞之時,到底是他們的模型架構不同導致的區別,還是他們訓練資料的製備不同導致的?
在以上考量,作者採用了他們《語言模型物理學》系列論文的核心思路,即製造人工合成數據,透過控制數據中知識的數量和類型,來嚴格調控資料中的知識位元(bits)。同時,作者使用不同大小和架構的 LLM 在人工合成資料上進行訓練,並給出數學定義,來精確計算訓練好的模型從資料中學到了多少位元的知識。

- 論文網址:https://arxiv.org/pdf/2404.05405.pdf
- #論文標題:Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws
對於這項研究,有人表示這個方向似乎是合理的。我們可以使用非常科學的方式來分析scaling law。
也有人認為,這項研究將 scaling law 提升到了不同的層次。當然,對於從業者來說是一篇必讀論文。
研究概覽
#作者研究了三種類型的合成資料:bioS、bioR、bioD 。 bioS 是使用英語模板編寫的人物傳記,bioR 是由LlaMA2 模型協助撰寫的人物傳記(22GB 總量),bioD 則是一種虛擬但可以進一步控制細節的知識數據(譬如可以控制知識的長度、詞彙量等等細節)。作者重點研究了基於 GPT2、LlaMA、Mistral 的語言模型架構,其中 GPT2 採用了更新的 Rotary Position Embedding (RoPE) 技術。
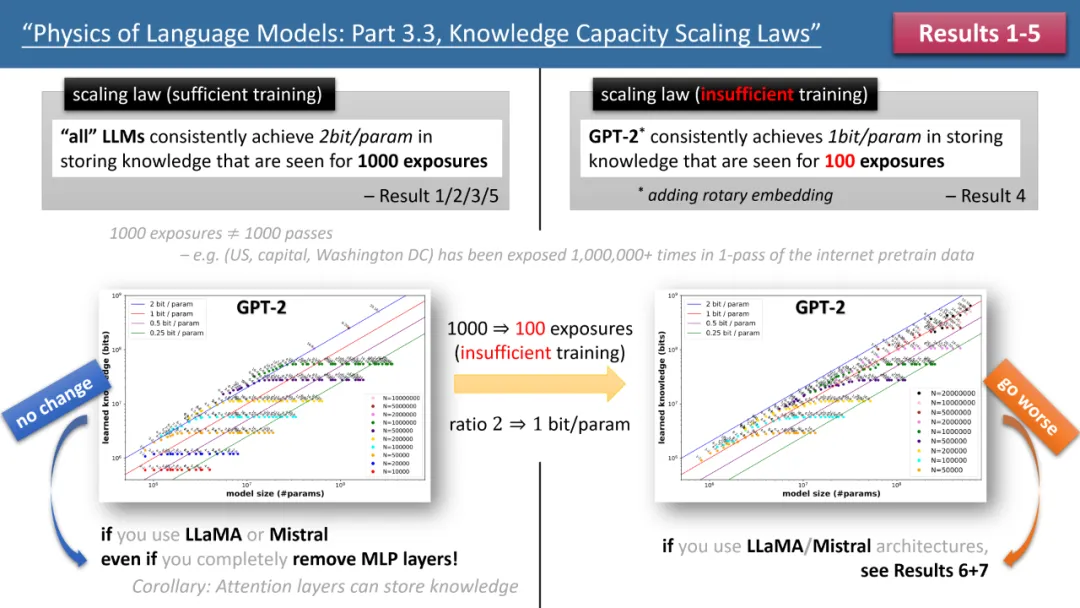
左圖為訓練時間充足,右圖為訓練時間不足的scaling laws
上圖1 簡要概述了作者提出的前5 條定律,其中左/ 右分別對應了「訓練時間充足」和「訓練時間不足」兩種情況,分別對應了常見知識(如中國首都是北京)和較少出現的知識(如清華物理系成立於1926 年)。
如果訓練時間充足,作者發現,不論使用何種模型架構,GPT2 或LlaMA/Mistral,模型的儲存效率均可以達到2bit/param—— 即平均每個模型參數可以儲存2 位元的資訊。這與模型的深度無關,僅與模型大小有關。換言之,一個 7B 大小的模型,如果訓練充足,可以儲存 14B 位元的知識,這超過了維基百科和所有英文教科書中人類知識的總和!
更令人驚訝的是,儘管傳統理論認為transformer 模型中的知識主要儲存在MLP 層,但作者的研究反駁了這一觀點,他們發現即便移除了所有MLP 層,模型仍能達到2bit/param 的儲存效率。
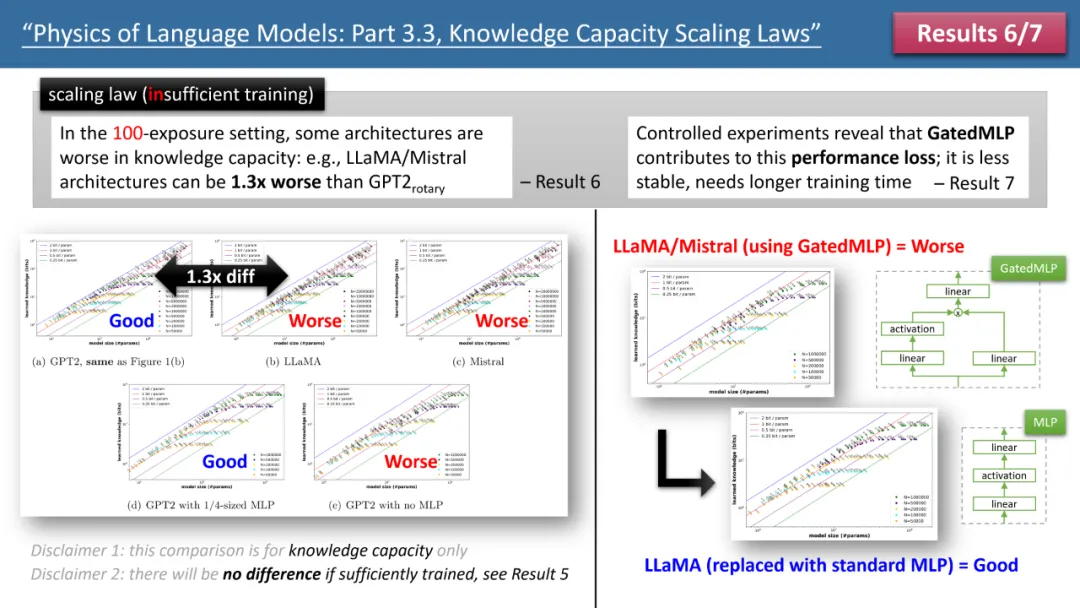
圖2:訓練時間不足情況下的scaling laws
然而,當我們觀察訓練時間不足的情況時,模型間的差異就顯現出來了。如上圖 2 所示,在這種情況下,GPT2 模型能比 LlaMA/Mistral 儲存超過 30% 的知識,這意味著幾年前的模型在某些方面超越了今天的模型。為什麼會這樣呢?作者透過在 LlaMA 模型上進行架構調整,將模型與 GPT2 的每個差異進行增減,最終發現是 GatedMLP 導致了這 30% 的損失。
強調一下,GatedMLP 並不會導致模型的「最終」儲存率變化 —— 因為圖 1 告訴我們如果訓練充足它們就不會有差。但是,GatedMLP 會導致訓練不穩定,因此對同樣的知識,需要更長的訓練時間;換句話說,對於較少出現在訓練集裡的知識,模型的儲存效率就會下降。
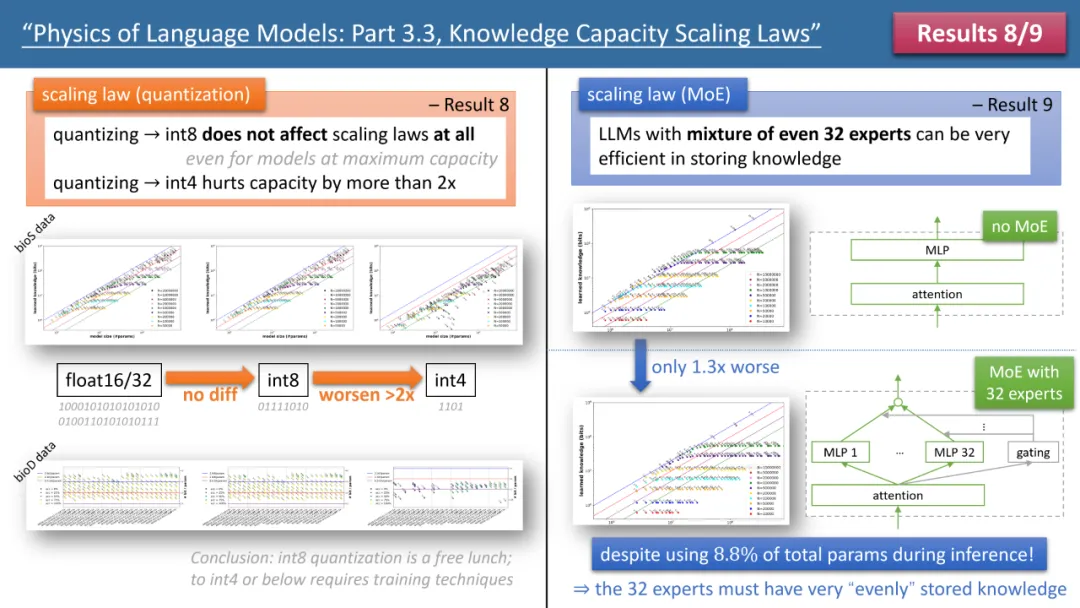
圖3:quantization 和MoE 對模型scaling laws 的影響
作者的定律8 和定律9 分別研究了quantization 和MoE 對模型scaling law 的影響,結論如上圖3 所示。其中一個結果是,將訓練好的模型從 float32/16 壓縮到 int8,竟然對知識的儲存毫無影響,即便對已經達到 2bit/param 儲存極限的模型也是如此。
這意味著,LLM 可以達到「資訊理論極限」的 1/4—— 因為 int8 參數只有 8 個位元,但平均每個參數可以儲存 2 個位元的知識。作者指出,這是一個普遍法則(universal law),和知識的表現無關。
最引人注目的結果來自於作者的定律 10-12(見圖 4)。如果我們的 (預) 訓練資料中,有 1/8 來自高品質知識庫(如百度百科),7/8 來自低品質資料(如 common crawl 或論壇對話,甚至是完全隨機的垃圾資料)。
那麼,低品質資料是否會影響 LLM 對高品質知識的吸收呢?結果令人驚訝,即使對高品質資料的訓練時間保持一致,低品質資料的「存在本身」,可能會讓模型對高品質知識的儲存量下降 20 倍!即便將高品質資料的訓練時間延長 3 倍,知識儲量仍會降低 3 倍。這就像是將金子丟進沙子裡,高品質數據被嚴重浪費了。
有什麼辦法可以修復呢?作者提出了一個簡單但極其有效的策略,只需給所有的 (預) 訓練資料加上自己的網站網域 token 即可。例如,將 Wiki 百科全書資料統統加上 wikipedia.org。模型不需要任何先驗知識來識別哪些網站上的知識是“金子”,而可以在預訓練過程中,自動發現高質量知識的網站,並自動為這些高品質資料騰出儲存空間。
作者提出了一個簡單的實驗來驗證:如果高品質資料都加上一個特殊token(任何特殊token 都行,模型不需要事先知道是哪個token),那麼模型的知識儲存量可以立即回升10 倍,是不是很神奇呢?所以說對預訓練資料增加網域 token,是一個極為重要的資料製備操作。
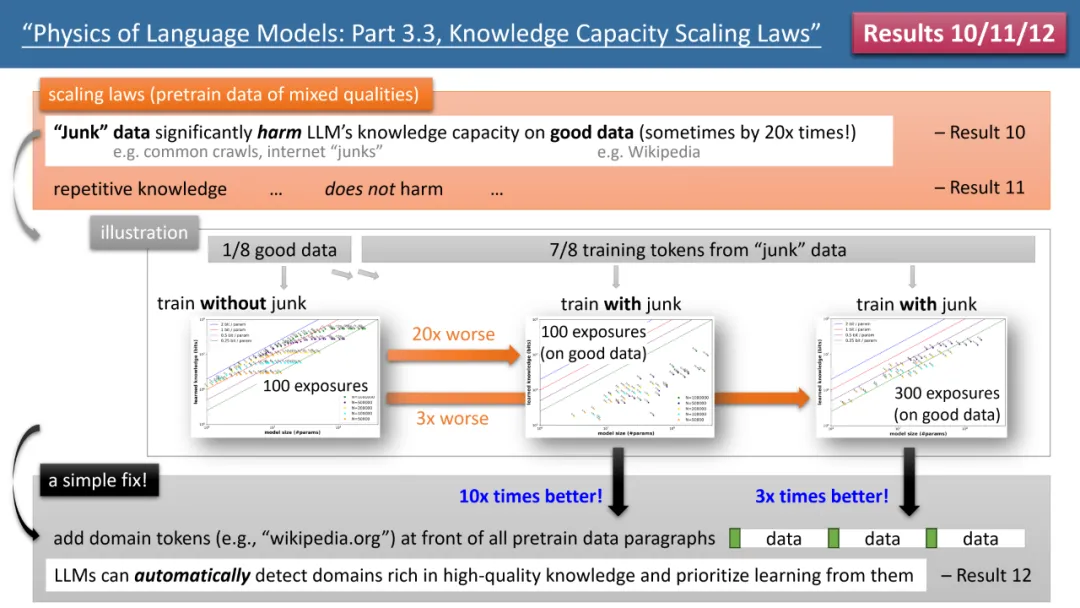
圖4:預訓練資料「知識品質不整齊」情況下的scaling laws,模型缺陷以及如何修復
結語
作者認為,透過合成數據,計算模型在訓練過程中獲得的知識總量的方法,可以為「評估模型架構、訓練方法和數據製備」提供了一套系統且精確的評分體系。這和傳統的 benchmark 比較完全不同,而且更可靠。他們希望這能幫助未來 LLM 的設計者做出更明智的決策。
以上是Llama架構比不上GPT2?神奇token提升10倍記憶?的詳細內容。更多資訊請關注PHP中文網其他相關文章!