



CLIP长文本能力被解锁,图像检索任务表现显著提升!
一些关键细节也能被捕捉到。上海交大联合上海AI实验室提出新框架Long-CLIP。

△棕色文本为区分两张图的关键细节
Long-CLIP基于保持CLIP原始特征空间的基础上,在图像生成等下游任务中即插即用,实现长文本细粒度图像生成。
长文本-图像检索提升20%,短文本-图像检索提升6%。
解锁CLIP长文本能力
CLIP 对齐了视觉与文本模态,拥有强大的 zero-shot 泛化能力。因此,CLIP 被广泛应用在各种多模态任务中,如图像分类、文本图像检索、图像生成等。
但CLIP的一大弊病是在于长文本能力的缺失。
首先,由于采用了绝对位置编码,CLIP的文本输入长度被限制在677个token。不仅如此,实验证明CLIP真正的有效长度甚至不足20个token,远远不够以表征细粒度信息。 然而,为了克服这个限制,研究者们提出了一种解决方案。通过在文本输入中引入特定的标记,使模型能够聚焦于重要的部分。这些标记在输入中的位置和数量都是事先确定的,不会超过20个token。 通过这种方式,CLIP在处理文本输入时能够
文本端的长文本缺失也限制了视觉端的能力。由于仅包含短文本,CLIP的视觉编码器也只会提取一张图片中最主要的成分,而忽略了各种细节。这对跨模态检索等细粒度任务是十分不利的。
同时,长文本的缺乏也使CLIP采取了类似bag-of-feature(BOF)的简单建模方式,不具备因果推理等复杂能力。
针对这一问题,研究人员提出了Long-CLIP模型。

具体提出了两大策略:保留知识的位置编码扩充(Knowledge-Preserving Stretching of Positional Embedding)与加入核心成分对齐(Primary Component Matching)的微调策略。
保留知识的位置编码扩充
一个简单的扩充输入长度、增强长文本能力的方法是先以固定的比率 λ1 对位置编码进行插值,再通过长文本进行微调。
研究者们发现,CLIP的不同位置编码的训练程度是不同的。由于训练文本很可能以短文本为主,较低位的位置编码训练较为充分,能够精确地表征绝对位置,而较高位的位置编码则仅能表征其大致的相对位置。因此,对不同位置的编码进行插值的代价是不同的。
基于以上观察,研究者保留了前20个位置编码,而对于剩下的57个位置编码,则以一个更大的比率λ2 进行插值,计算公式可表示为:
实验表明,相较于直接插值,该策略可以在支持更长的总长度的同时大幅提升在各个任务上的性能。
加入核心属性对齐的微调
仅仅引入长文本微调会使模型走入另一个误区,即一视同仁地囊括所有细节。针对这一问题,研究者们在微调中引入核心属性对齐这一策略。
具体而言,研究者们利用主成分分析(PCA)算法,从细粒度的图像特征中提取核心属性,将其余属性过滤后重建粗粒度图像特征,并将其与概括性的短文本进行对齐。这一策略既要求模型不仅能够包含更多的细节(细粒度对齐),同时还能识别并建模其中最为核心的属性(核心成分提取与粗粒度对齐)。

△加入核心属性对齐的微调流程
即插即用在各种多模态任务中
在图文检索、图像生成等领域,Long-CLIP可即插即用地替换CLIP。
比如图文检索,Long-CLIP能够在图像与文本模态捕捉更多细粒度信息,从而可以增强相似图像和文本的区分能力,大幅提升图文检索的表现。
无论是在传统的短文本检索(COCO、Flickr30k),还是在长文本检索任务上,Long-CLIP在召回率上均有显著提升。
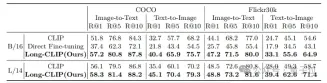
△短文本-图像检索实验结果
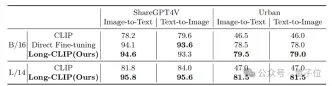
△长文本-图像检索实验结果

△长文本-图像检索可视化,棕色文本为区分两张图片的关键细节
除此之外,CLIP的文本编码器常被用于文本到图像生成模型中,如stable diffusion系列等。但由于长文本能力的缺失,用于生成图像的文本描述通常都十分简短,无法个性化地订制各种细节。
Long-CLIP可以突破77个token的限制,实现篇章级别的图像生成(右下)。
也可以在77个token内建模更多地细节,实现细粒度图像生成(右上)。

论文链接:https://arxiv.org/abs/2403.15378
代码链接:https://github.com/beichenzbc/Long-CLIP
以上是上海交大新框架解锁CLIP长文本能力,多模态生成细节拿捏,图像检索能力显著提升的詳細內容。更多資訊請關注PHP中文網其他相關文章!


 優化您的組織與Genai代理商的電子郵件營銷Apr 13, 2025 am 11:44 AM
優化您的組織與Genai代理商的電子郵件營銷Apr 13, 2025 am 11:44 AM介紹 恭喜!您經營一家成功的業務。通過您的網頁,社交媒體活動,網絡研討會,會議,免費資源和其他來源,您每天收集5000個電子郵件ID。下一個明顯的步驟是
 Apache Pinot實時應用程序性能監視Apr 13, 2025 am 11:40 AM
Apache Pinot實時應用程序性能監視Apr 13, 2025 am 11:40 AM介紹 在當今快節奏的軟件開發環境中,確保最佳應用程序性能至關重要。監視實時指標,例如響應時間,錯誤率和資源利用率可以幫助MAIN
 Chatgpt擊中了10億用戶? Openai首席執行官說:'短短幾週內翻了一番Apr 13, 2025 am 11:23 AM
Chatgpt擊中了10億用戶? Openai首席執行官說:'短短幾週內翻了一番Apr 13, 2025 am 11:23 AM“您有幾個用戶?”他扮演。 阿爾特曼回答說:“我認為我們上次說的是每週5億個活躍者,而且它正在迅速增長。” “你告訴我,就像在短短幾週內翻了一番,”安德森繼續說道。 “我說那個私人
 pixtral -12b:Mistral AI'第一個多模型模型 - 分析VidhyaApr 13, 2025 am 11:20 AM
pixtral -12b:Mistral AI'第一個多模型模型 - 分析VidhyaApr 13, 2025 am 11:20 AM介紹 Mistral發布了其第一個多模式模型,即Pixtral-12b-2409。該模型建立在Mistral的120億參數Nemo 12B之上。是什麼設置了該模型?現在可以拍攝圖像和Tex
 生成AI應用的代理框架 - 分析VidhyaApr 13, 2025 am 11:13 AM
生成AI應用的代理框架 - 分析VidhyaApr 13, 2025 am 11:13 AM想像一下,擁有一個由AI驅動的助手,不僅可以響應您的查詢,還可以自主收集信息,執行任務甚至處理多種類型的數據(TEXT,圖像和代碼)。聽起來有未來派?在這個a




熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

SublimeText3 Linux新版
SublimeText3 Linux最新版

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)

ZendStudio 13.5.1 Mac
強大的PHP整合開發環境

SAP NetWeaver Server Adapter for Eclipse
將Eclipse與SAP NetWeaver應用伺服器整合。

EditPlus 中文破解版
體積小,語法高亮,不支援程式碼提示功能

