
Mamba超強進化體一舉顛覆Transformer!單張A100跑140K上下文

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2024-03-29 15:11:18890瀏覽
之前引爆了AI圈的Mamba架構,今天又推出了一版超強變體!
人工智慧獨角獸AI21 Labs剛剛開源了Jamba,世界上第一個生產級的Mamba大模型!

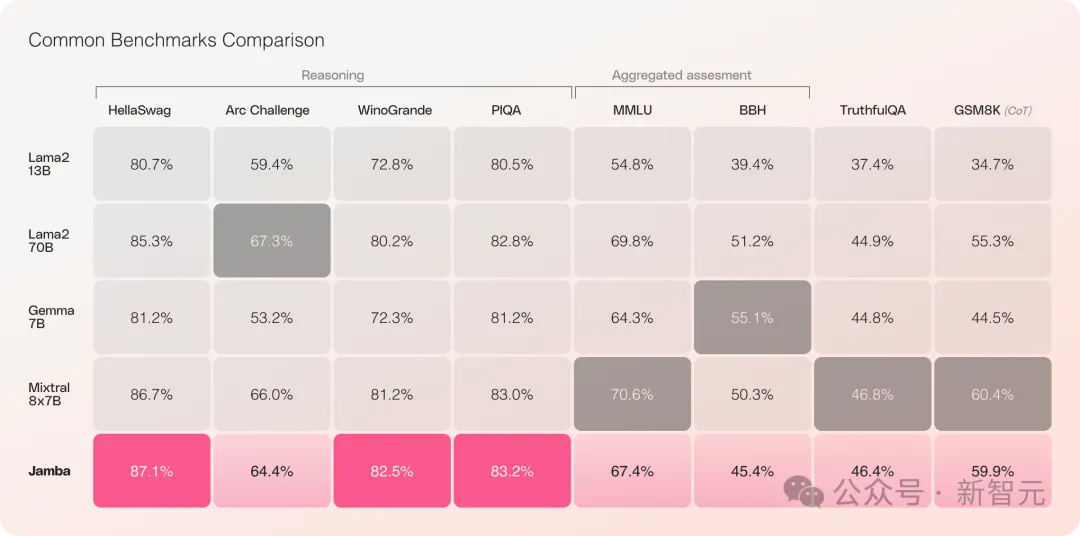
Jamba在多項基準測試中表現亮眼,與目前最強的幾個開源Transformer平起平坐。
特別是比較效能最好的、同為MoE架構的Mixtral 8x7B,也互有勝負。
具體來說它-
- 是基於全新SSM-Transformer混合架構的首個生產級Mamba模型
- 與Mixtral 8x7B相比,長文字處理吞吐量提高了3倍
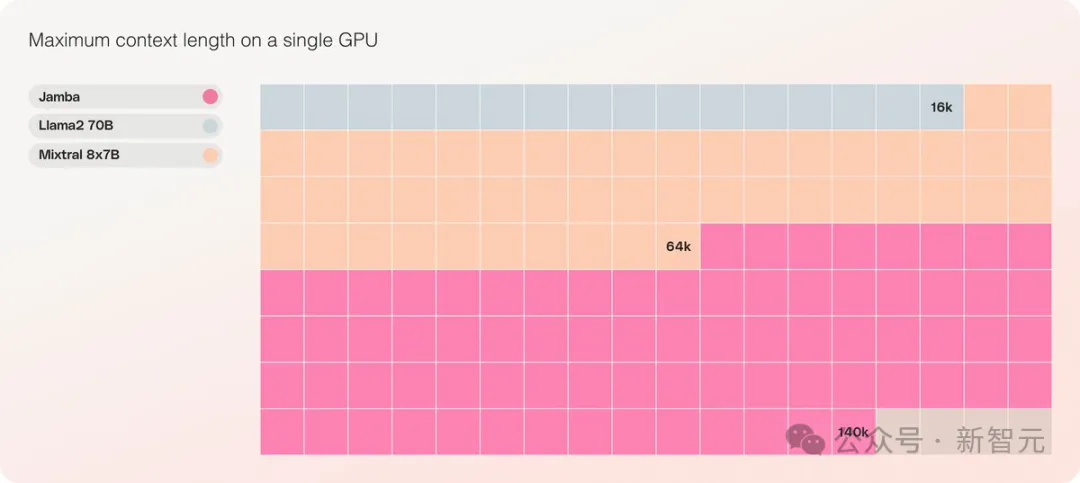
- 實作了256K超長上下文視窗
- #是同等規模中,唯一能在單張GPU上處理140K上下文的模型
- 以Apache 2.0開源授權協議發布,開放權重
之前的Mamba因為各種限制,只能做到3B,還被質疑能否接過Transformer的大旗,而同為線性RNN家族的RWKV、Griffin等也只擴展到了14B。
——Jamba這次直接幹到52B,讓Mamba架構第一次能夠正面硬剛生產等級的Transformer。

Jamba在原始Mamba架構的基礎上,融入了Transformer的優勢來彌補狀態空間模型(SSM)的固有限制。
可以認為,這其實是一種新的架構-Transformer和Mamba的混合體,最重要的是,它可以在單張A100上運行。
它提供了高達256K的超長上下文窗口,單一GPU就可以跑140K上下文,而且吞吐量是Transformer的3倍!
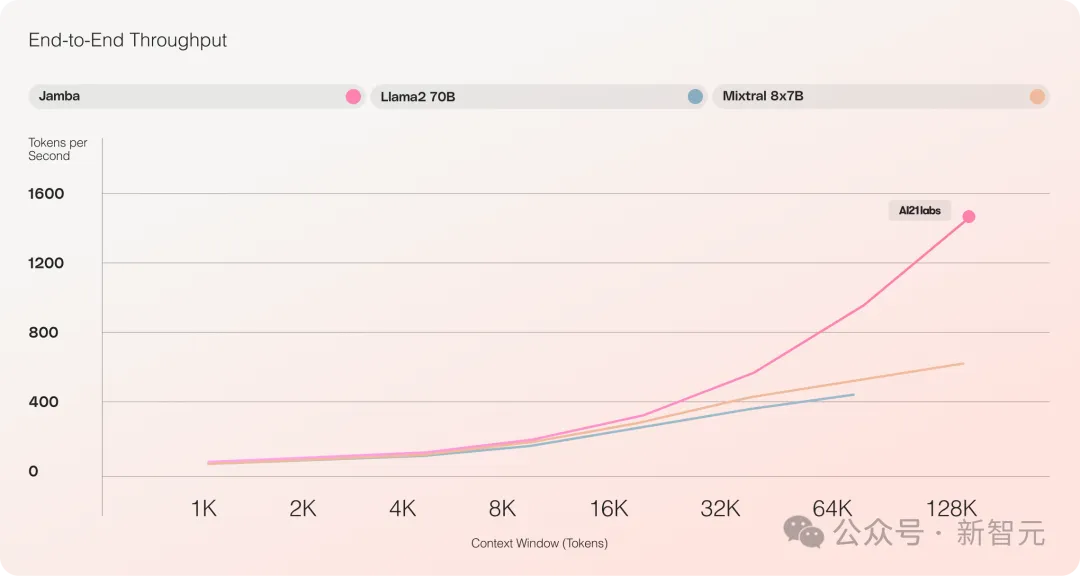
與Transformer相比,看看Jamba如何擴展到巨大的上下文長度,非常震撼
## Jamba採用了MoE的方案,52B中有12B是活躍參數,目前模型在Apache 2.0下開放權重,可以在huggingface下載。

模式下載:https://huggingface.co/ai21labs/Jamba-v0.1
#LLM新里程碑Jamba的發布標誌著LLM的兩個重要里程碑:
一是成功將Mamba與Transformer架構結合,二是將新形態的模型(SSM-Transformer)成功提升到了生產級的規模和品質。
目前效能最強的大模型全是基於Transformer的,儘管大家也都體認到了Transformer架構存在的兩個主要缺點:
記憶體佔用量大:Transformer的記憶體佔用量隨上下文長度而擴展。想要運行長上下文窗口,或大量並行批次就需要大量硬體資源,這限制了大規模的實驗和部署。
隨著上下文的增長,推理速度會變慢:Transformer的注意力機制導致推理時間相對於序列長度平方增長,吞吐會越來越慢。因為每個token都依賴它之前的整個序列,所以要做到超長上下文就變得相當困難。
年前,兩位來自卡內基美隆和普林斯頓的大佬提出了Mamba,一下子就點燃了人們的希望。
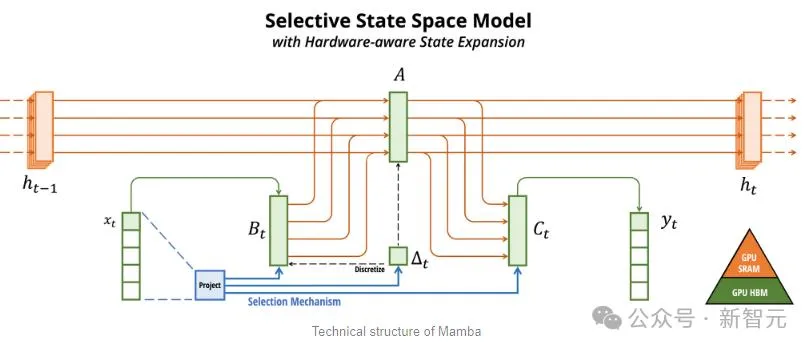
Mamba以SSM為基礎,增加了選擇性提取資訊的能力、以及硬體上高效的演算法,一舉解決了Transformer存在的問題。
這個新領域馬上就吸引了大量的研究者,arXiv上一時湧現了大量關於Mamba的應用和改進,例如將Mamba用於視覺的Vision Mamba。
不得不說,現在的科學研究領域實在是太捲了,把Transformer引入視覺(ViT)用了三年,但Mamba到Vision Mamba只花了一個月。
不過原始Mamba的上下文長度較短,加上模型本身也沒有做大,所以很難打過SOTA的Transformer模型,尤其是在與召回相關的任務上。
Jamba於是更進一步,透過Joint Attention and Mamba架構,整合了Transformer、Mamba、以及專家混合(MoE)的優勢,同時優化了記憶體、吞吐量和效能。

Jamba是第一個達到生產級規模(52B參數)的混合架構。
如下圖所示,AI21的Jamba架構採用blocks-and-layers的方法,使Jamba能夠成功整合這兩種架構。
每個Jamba區塊都包含一個注意力層或一個Mamba層,然後是一個多層感知器(MLP)。
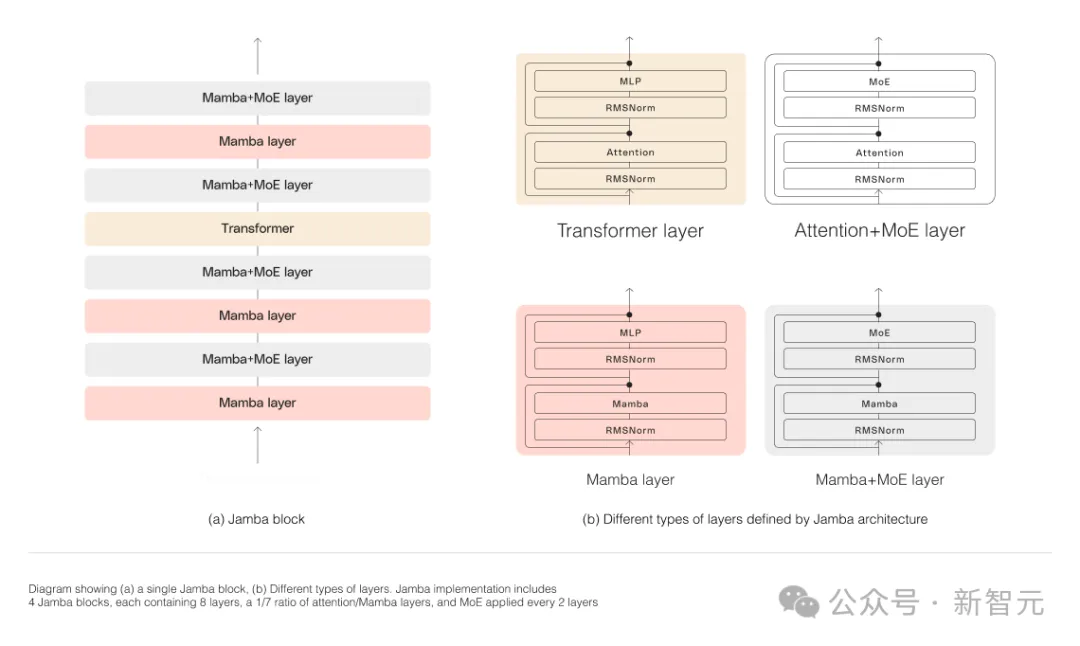
Jamba的第二個特點,是利用MoE來增加模型參數的總數,同時簡化推理中所使用的活動參數的數量,從而在不增加計算要求的情況下提高模型容量。
為了在單一80GB GPU上最大限度地提高模型的品質和吞吐量,研究人員優化了使用的MoE層和專家的數量,為常見的推理工作負載留出足夠的記憶體。
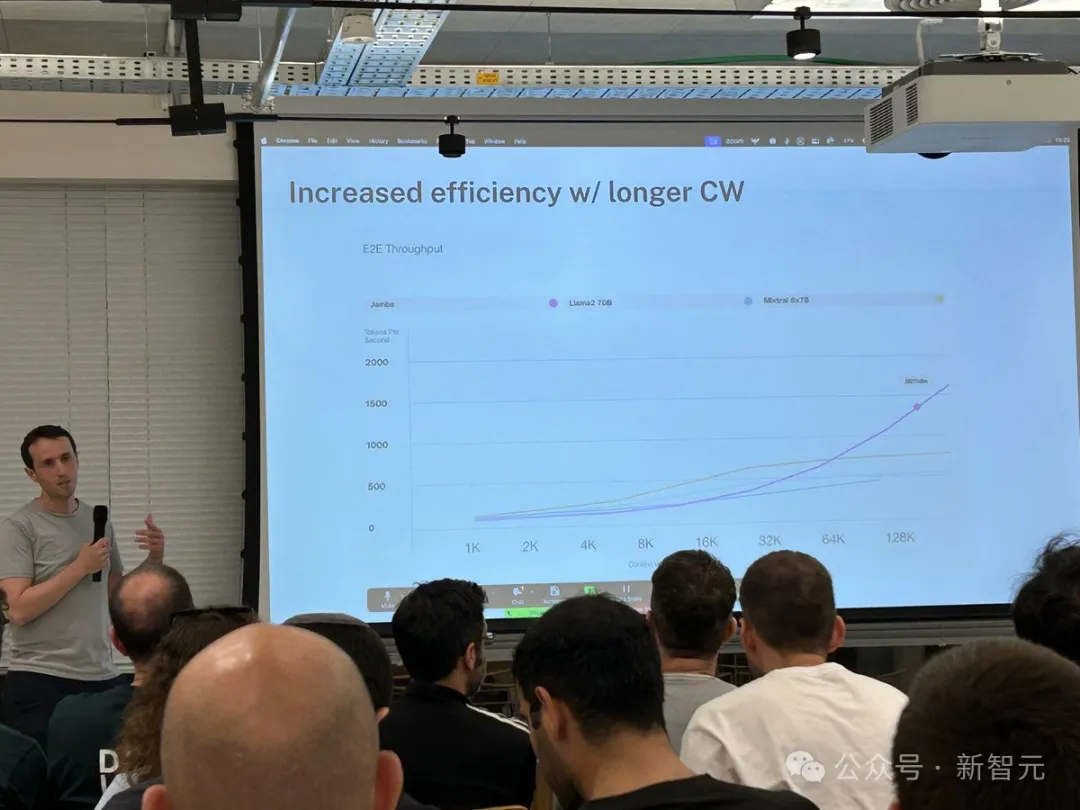
對比Mixtral 8x7B等類似大小的基於Transformer的模型,Jamba在長上下文上做到了3倍的加速。
Jamba將在不久之後加入NVIDIA API目錄。
長上下文又出新選手
最近,各大公司都在卷長上下文。
具有較小上下文視窗的模型,往往會忘記最近對話的內容,而具有較大上下文的模型則避免了這種陷阱,可以更好地掌握所接收的數據流。
不過,具有長上下文視窗的模型,往往是計算密集的。
新創公司AI21 Labs的生成式模型就證明,事實並非如此。

Jamba在具有至少80GB顯存的單一GPU(如A100)上運行時,可以處理多達140,000個token。
這相當於大約105,000字,或210頁,是一本長度適中的長篇小說的篇幅。
相較之下,Meta Llama 2的上下文窗口,只有32,000個token,需要12GB的GPU顯存。
以今天的標準來看,這種上下文視窗顯然是偏小的。
對此,有網友也第一時間表示,性能什麼的都不重要,關鍵的是Jamba有256K的上下文,除了Gemini,其他人都沒有這麼長,— —而Jamba可是開源的。
Jamba真正的獨特之處
從表面上看,Jamba似乎並不起眼。
無論是昨天風頭正盛的DBRX,還是Llama 2,現在都已經有大量免費提供、可下載的生成式AI模型。
而Jamba的獨特之處,是藏在模型底下的:它同時結合了兩種模型架構-Transformer和狀態空間模型SSM。
一方面,Transformer是複雜推理任務的首選架構。它最核心的定義特徵,就是「注意力機制」。對於每個輸入數據,Transformer會權衡所有其他輸入的相關性,並從中提取以產生輸出。
另一方面,SSM結合了早期AI模型的多個優點,例如遞歸神經網路和卷積神經網絡,因此能夠實現長序列資料的處理,且運算效率更高。
雖然SSM有自己的限制。但一些早期的代表,例如由普林斯頓和CMU提出的Mamba,就可以處理比Transformer模型更大的輸出,在語言生成任務上也更優。
對此,AI21 Labs產品負責人Dagan表示-
#雖然也有一些SSM模型的初步範例,但Jamba是第一個生產規模的商業級模型。
在他看來,Jamba除了創新和趣味性可供社群進一步研究,還提供了巨大的效率,和吞吐量的可能性。
目前,Jamba是基於Apache 2.0許可發布的,使用限制較少但不能商用。後續的微調版本,預計將在幾週內推出。
即便還處在研究的早期階段,但Dagan斷言,Jamba無疑展示了SSM架構的巨大前景。
「這個模型的附加價值-無論是因為尺寸或架構的創新-都可以很容易地安裝到單一GPU上。」
以上是Mamba超強進化體一舉顛覆Transformer!單張A100跑140K上下文的詳細內容。更多資訊請關注PHP中文網其他相關文章!