
大數據 AI 一體化解讀

- 王林轉載
- 2024-03-25 12:46:401119瀏覽
一、AI 的「iPhone」時刻
在過去的一年中,大模型的發展非常迅速,算力和資料的堆疊使模型具備了一些通用的構造和回答問題的能力,引領人們進入了一直夢想的人工智慧階段。舉個例子,在與大語言模型聊天時,會感覺面對的不是一個生硬的機器人,而是一個有血有肉的人。它為我們開啟了更多的想像空間。原來的人機交互,需要透過鍵盤滑鼠,透過一些格式化的方式告訴機器我們的指令。而現在,人們可以透過語言來與電腦交互,機器能夠理解我們的意思,並做出回應。
為了跟上潮流,許多科技公司開始專注於大型模型的研究。 2023年被認為是人工智慧的元年,就像當年iPhone的推出開啟了行動網路的新紀元。這次真正的突破在於大規模運算能力和大量資料的應用。
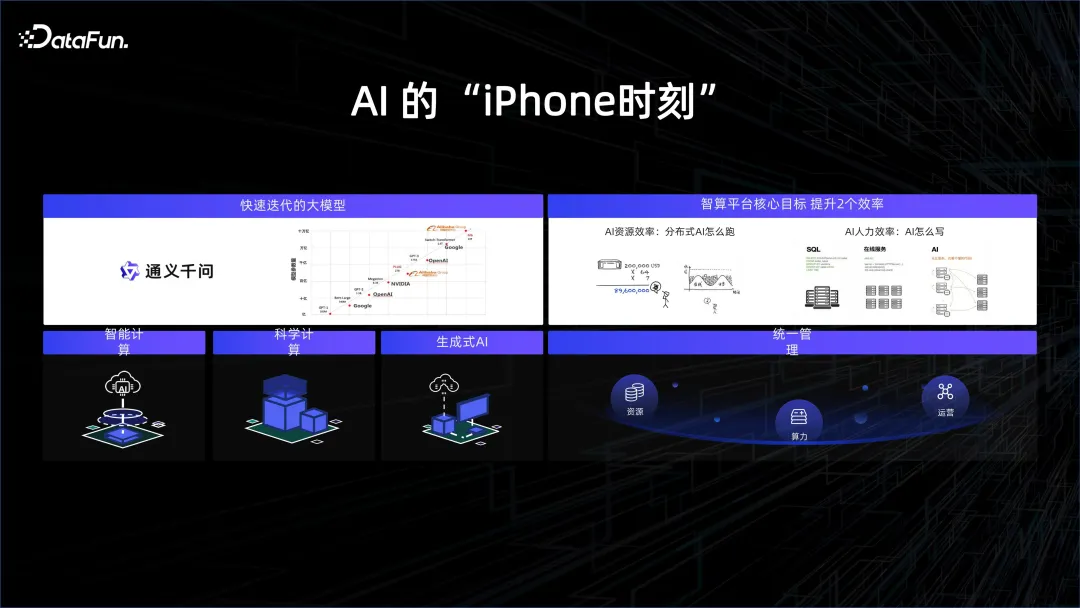
從模型結構來看,Transformer 結構其實已經推出很久了。事實上,GPT 模型比 Bert 模型更早一年發表,但由於當時算力的限制,GPT 的效果遠遠不如 Bert,所以 Bert 先火起來,被用來做翻譯,效果非常好。但今年的焦點已變為GPT,背後的原因就是因為有了非常高的算力,因為硬體廠商的努力,以及在封裝和儲存顆粒上的一些進步,使得我們有能力把非常高的算力堆疊在一起,推動對更多數據的深入理解,帶來了AI 的突破性成果。正是基於底層平台的強力支撐,演算法同學可以更方便、有效率地進行模型的開發與迭代,推動模型快速演進。

更好的機器學習是 80% 的資料加 20% 的模型,重心應該在資料這一塊。
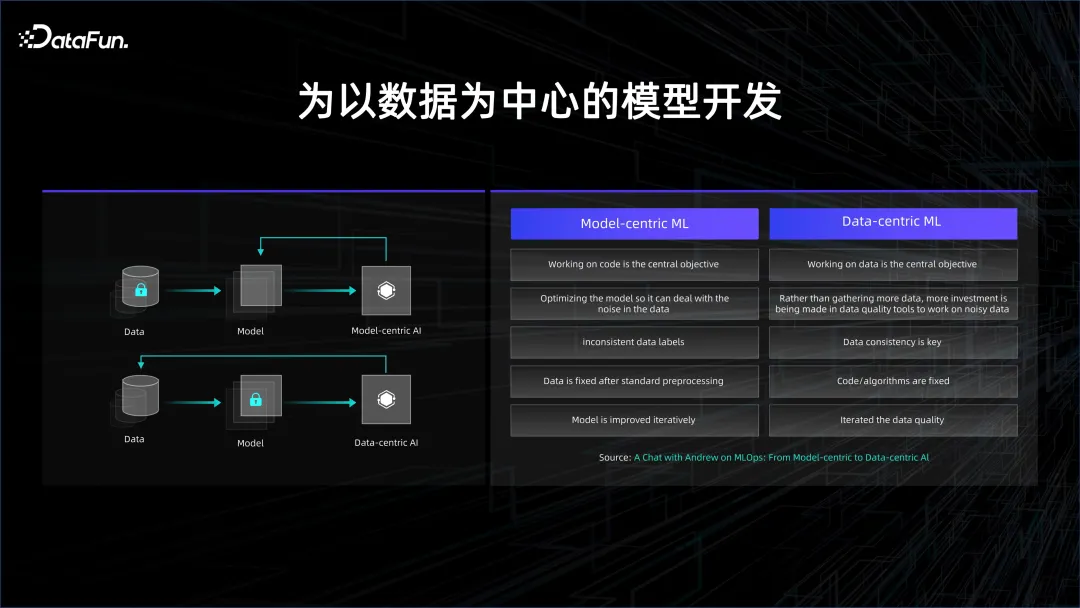
這也反映了模型開發的演進趨勢,原來的模型開發是以模型為中心,而現在則變成以資料為中心。
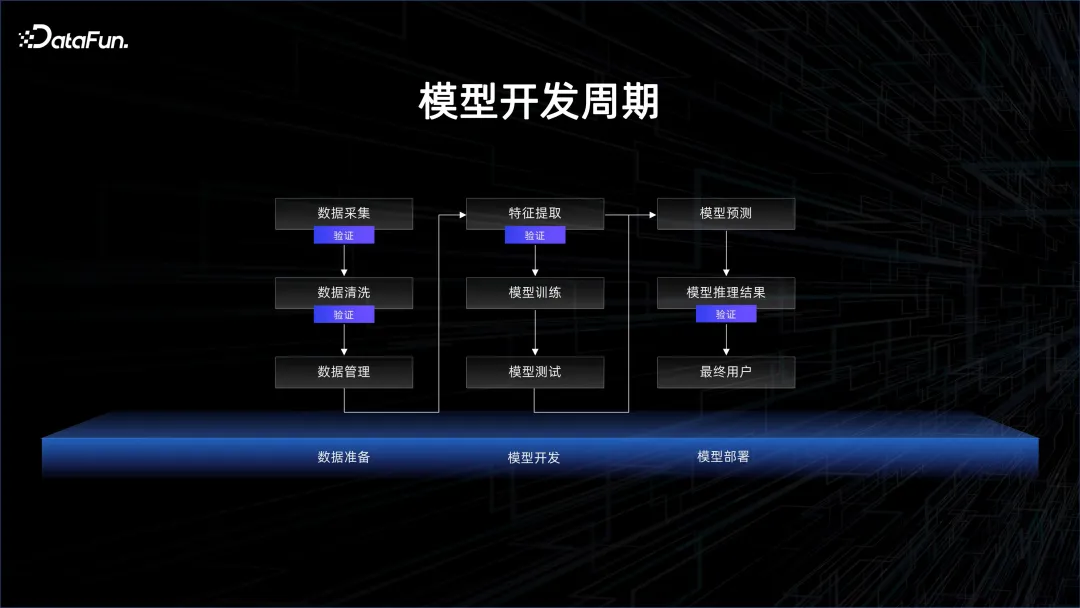
深度學習出現的初期,以監督學習為主,最重要的是要有標註的資料。標註的數據分為兩類,一類是訓練數據,另一類是驗證數據。透過訓練數據,讓模型去做訓練,然後再去驗證模型是否能在測試數據上給出很好的結果。標註數據成本是非常高的,因為需要人標註。如果想要提高模型的效果,需要將大量的時間和人力花在模型結構上面,透過結構的變化來提高模型的泛化能力,減少模型的 overfit,這就是以模型為中心的開發範式。
隨著數據和算力的積累,逐漸開始使用無監督的學習,透過海量的數據,讓模型自主地去發現這些數據中存在的關係,此時就進入了以資料為中心的開發範式。
在以資料為中心的開發模式下,模型結構都是類似的,基本上都是 Transformer 的堆疊,因此更關注的是如何利用資料。在用數據的過程中會有大量的數據清洗和比對,因為需要大量的數據,所以會耗費很多時間。如何精細地控制數據,決定了模型收斂和迭代的速度。
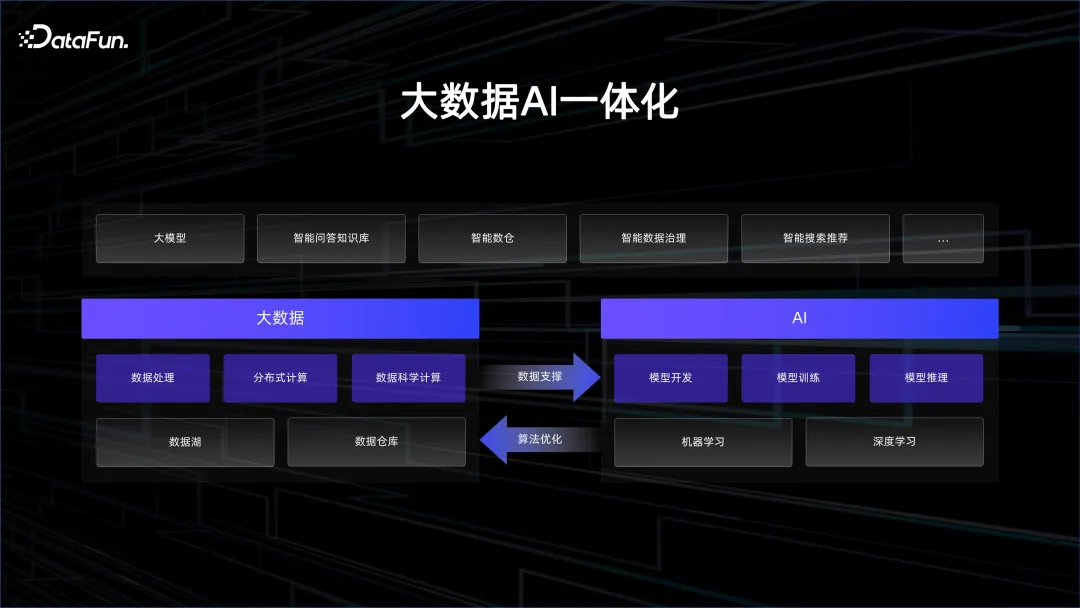
三、大數據AI 一體化
1 . 大數據AI 全景

阿里雲一直強調AI 與大數據的融合。因此我們建立了一套平台,它具有非常好的基礎設施,包括透過高頻寬的 GPU 叢集提供高效能 AI 算力,以及 CPU 叢集提供高性價比的儲存和資料管理能力。在此之上,我們建構了大數據 AI 一體化 PaaS 平台,其中包括大數據的平台、AI 的平台,以及高算力的平台和雲端原生的平台等等。引擎部分,包括串流運算、大數據離線計算 MaxCompute 和 PAI。
在服務層,有大模型應用平台百煉和開源模型社群 ModelScope。阿里一直在積極推動模型社群的分享,希望以 Model as a service 的理念去激發更多有 AI 需求的用戶,能夠利用這些模型的基礎能力,快速組成 AI 應用。
2. 為什麼需要將大數據和 AI 結合
下面透過兩個案例,來解釋為什麼需要大數據與 AI 的連動。
案例1:知識庫檢索增強的大模型問答系統
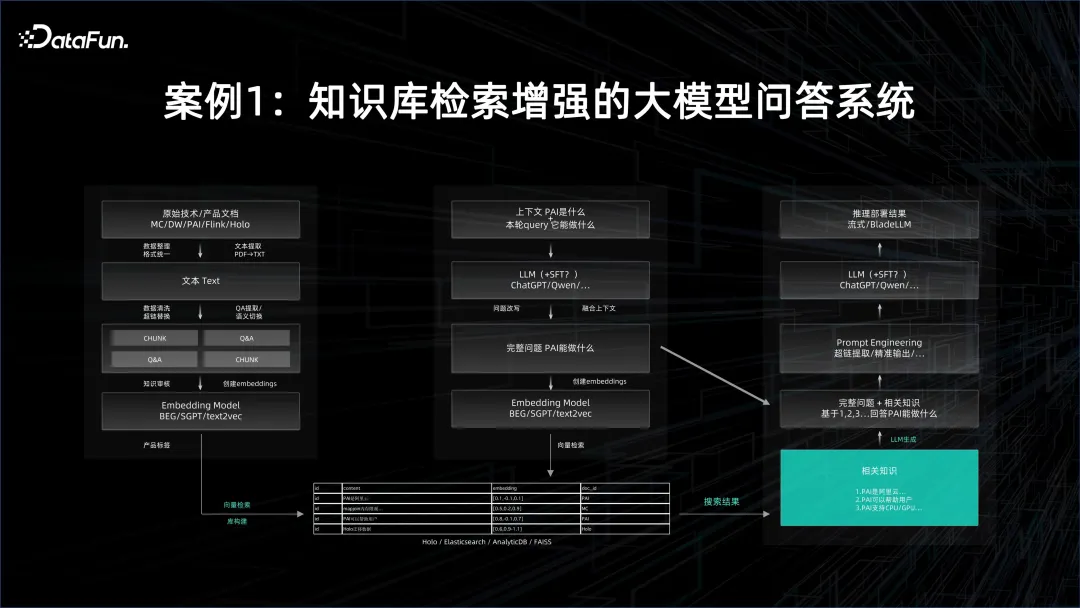
在大模型問答系統中,首先要用到基礎模型,然後把目標的文檔進行embedding 化,並將embedding 化的結果存在向量資料庫中。文件的數量可能會非常大,因此 embedding 化時需要批次的能力。本身基礎模型的推理服務也是很耗資源的,當然這也取決於用多大的基礎模型,以及如何平行化。產生的所有 embedding 灌入到向量資料庫中,在查詢時,query 也要經過向量化,然後透過向量檢索,把可能跟這個問答有關的知識從向量資料庫裡面提取出來。這需要非常好的推理服務的效能。
提取出向量後,需要把向量所代表的文檔當作context,再去約束這個大模型,在此基礎上做出問答,這樣回答的效果就會遠遠比自己搜尋方式得到的結果,而且是以人的自然語言的方式來回答的。
在上述過程中,既需要有離線的分散式大數據平台去快速產生embedding,又需要有對大模型訓練和服務的AI 平台,將整個流程連起來,才能構成一個大模型問答系統。
案例2:智慧推薦系統
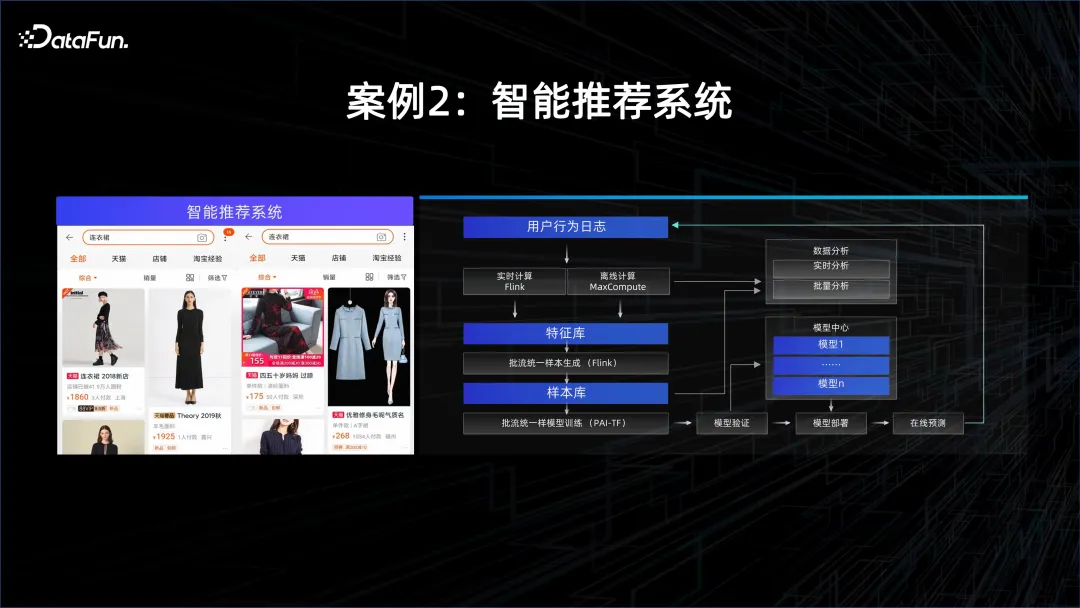
#另一個例子就是個人化推薦,這個模型往往需要很高的時效性,因為每個人的興趣和個性都會發生變化,要捕捉這些變化,需要用流式計算的系統對APP 內獲取到的數據進行分析,然後透過提取的特徵,不停地讓模型online learning,每當有新的資料進來時,模型就會更新,然後透過新的模型去服務客戶。因此,在這個場景中,需要有流式運算的能力,還需要有模型服務和訓練的能力。
3. 如何將大數據與AI 結合
透過上述案例可以看到AI 與大數據結合已成為必然的發展趨勢。在這個理念基礎之上,首先需要有一個工作空間,能夠將大數據平台和 AI 平台納入一起管理,這就是 AI 工作空間誕生的原因。
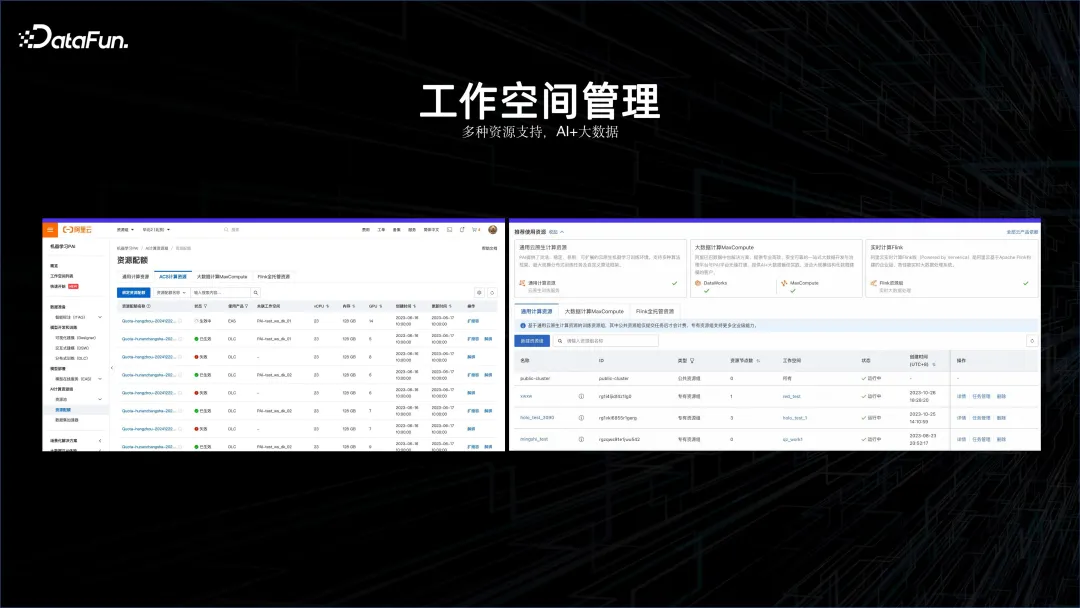
在這個 AI 工作空間裡面,支援 Flink 的叢集、離線運算叢集 MaxCompute,也能夠支援 AI 的平台,也支援容器服務運算平台等等。
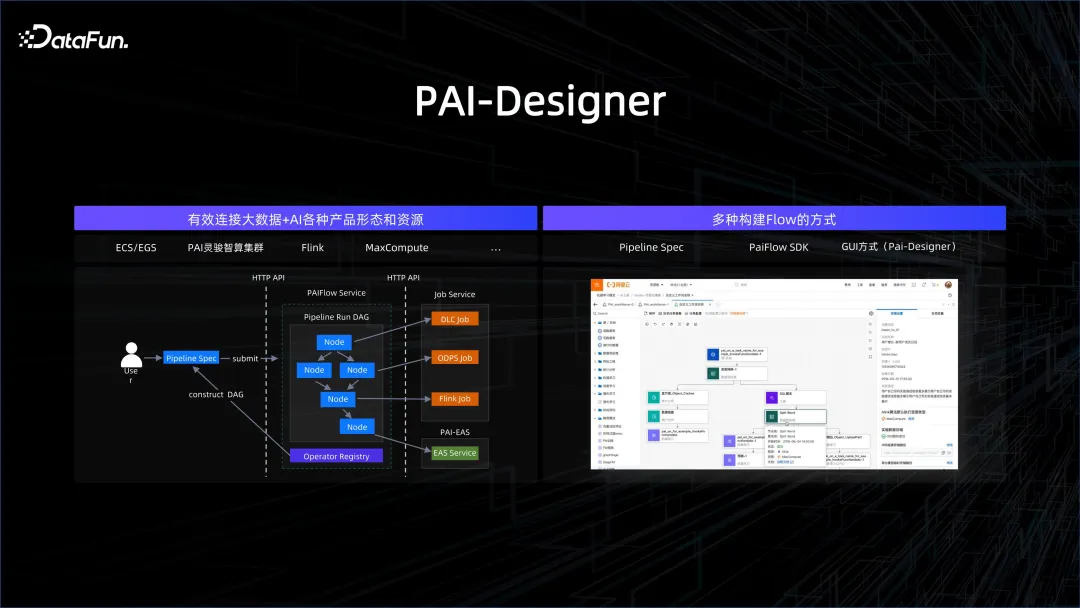
將大數據與 AI 統一管起來只是第一步,更重要的是以工作流程的方式將它們連接起來。可以透過多種方式建立工作流程,如 SDK 的方式、圖形化的方式、GUI 的方式、寫 SPEC 的方式等等。工作流程中的節點可以是大數據處理的節點,也可以是 AI 處理的節點,這樣就能夠很好地將複雜的流程連結起來。
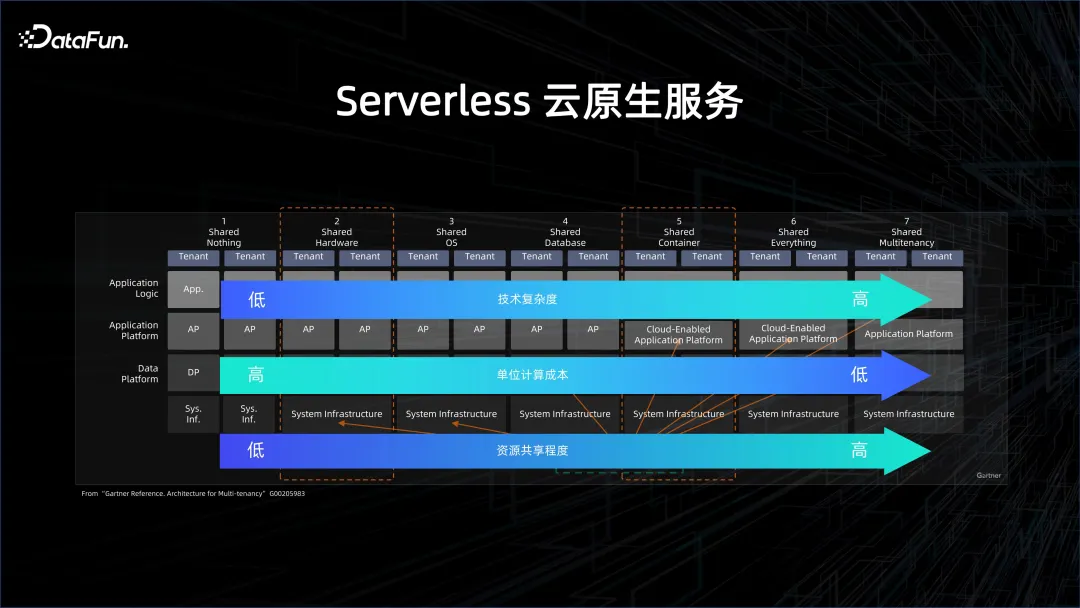
要進一步提高效率、降低成本,就需要 Severless 雲端原生服務。上圖中詳細描述了什麼是 Severless。雲原生,從 share nothing(非雲化方式),到 share everything(非常雲化的方式),之間有很多不同的層次。層次越高,資源的共享程度越高,單位計算的成本就越低,但對於系統的壓力也會越大。

大數據和資料庫領域在這兩年開始慢慢走向 Serverless,也是基於成本的考量。原先,即便是在雲端上使用的 Server,如雲端上的資料庫,也是以實例化的形式存在。這些實例的背後有資源的影子,例如這個實例是多少 CPU、多少 Core。慢慢逐漸轉變為 Serverless,第一層是單租運算,指的是在雲端上起一個 cluster,然後在裡面佈大資料或資料庫的平台。但這個 cluster 是單租的,也就是和其他人共享實體機,物理機虛擬化出一個虛擬機,用於做大數據的平台,這種叫做單租計算、單租存儲、單租管控。使用者得到的是雲端上彈性的 ECS 機器,但是大數據管理、運維的方案需要自己來做。 EMR 就是這方面一個經典的方案。
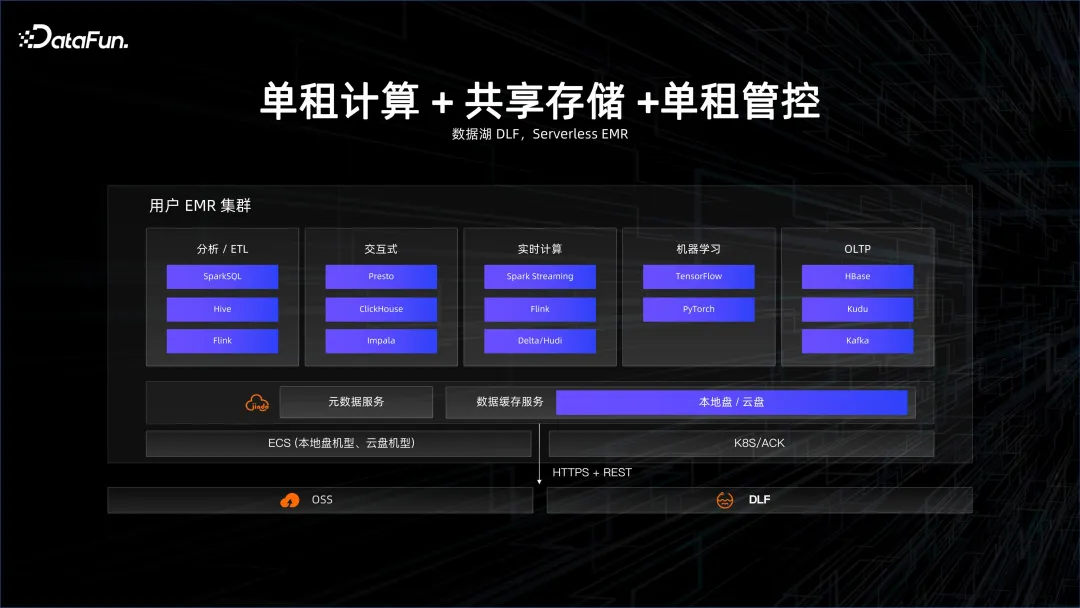
慢慢地會從單租存儲走向共享存儲,也就是資料湖的方案。資料在一個更共享的大數據系統裡面,計算是動態拉起一個集群,算完了之後這個cluster 就消亡了,但數據不會消亡,因為數據是在一個reliable 的remote 的存儲端,這就是共享存儲。典型的就是資料湖 DLF 以及 serverless EMR 的方案。

最極致的是Share Everything,大家如果去用BigQuery 或阿里雲的MaxCompute,看到的會是一個平台,一些虛擬化的project 的管理,使用者提供一個query,平台根據query 來計費計量。

這樣可以帶來非常多的好處。例如大數據運算中有很多節點,並不需要有使用者的程式碼,因為這些節點其實是一些build-in 的operator,像是join、aggregator,這些確定性的結果並不需要用一個比較重的Sandbox,因為它們是確定性的算子,是經過嚴格的測試檢驗的,沒有任何惡意程式碼或隨意的UDF 程式碼,因此可以讓其去掉虛擬化這些overhead。
UDF 帶來的好處是靈活性,使我們能夠有能力去處理豐富的數據,在數據量大的時候有很好的擴展性。但 UDF 會帶來的一個挑戰就是需要有安全性,需要做隔離。
無論是Google 的BigQuery 還是MaxComputer,都是走在share everything 的架構上面,我們認為只有技術的不斷提升,才能夠把資源用得更加緊實,將算力成本節省下來,讓更多企業能夠消費得起這些數據,並推動數據在模型訓練上面的使用。
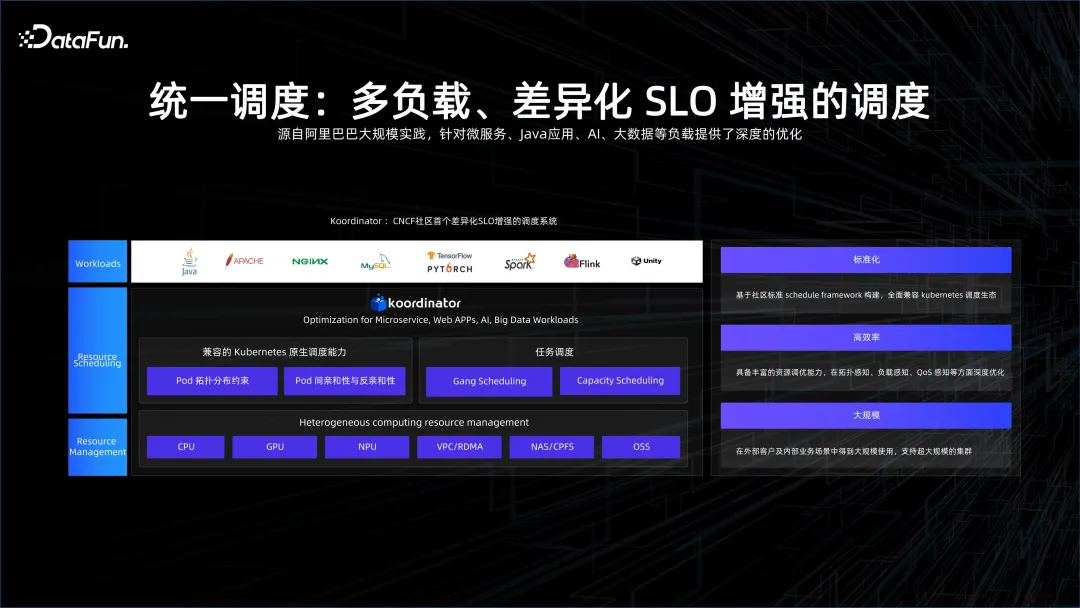
正是因為有share everything,我們不僅可以將大數據和AI 透過工作空間統一管理起來,透過PAI-flow 連起來,更能夠以share everything 的方式進行統一調度。這樣企業 AI 大數據的研發成本會進一步下降。
在這一點上,有很多工作要做。 K8S 本身的調度是面向微服務的,對於大數據會面臨很大挑戰,因為大數據的服務調度粒度非常小,很多task 只會存活幾秒到幾十秒,這對於調度的規模性以及對調度的整體壓力會有幾個量級的提升。我們主要需要解決在 K8S 上,怎樣讓這種調度的能力得到 scale off,我們推出的 Koordinator 開源專案就是要去提高調度能力,使大數據和 AI 在 K8S 生態上得到融合。

另一項重要的工作就是多租安全隔離。如何在 K8S 的服務層、控制層做多租,如何在網路上去做 over lake 多租,使得在一個 K8S 之上服務多種用戶,各用戶的資料和資源能夠得到有效的隔離。
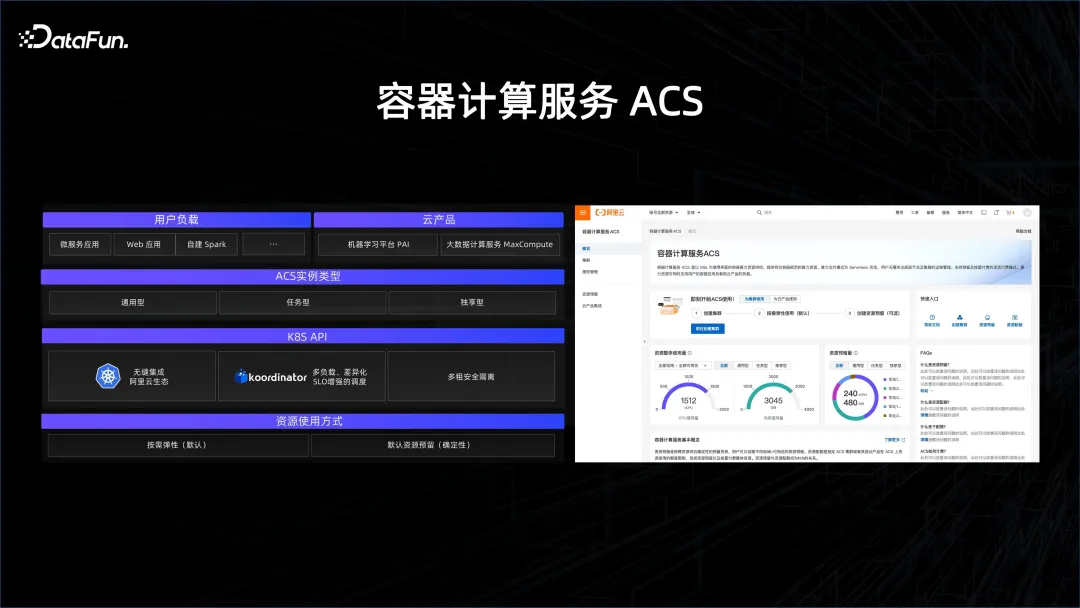
阿里推出了一個容器服務叫做ACS,也就是透過前面介紹的兩個技術把所有資源透過容器化的方式露出來,使得用戶在大數據平台和AI 平台上面能夠無縫地使用。它是一種多租的方式,並且能夠支撐住大數據的需求。大數據在調度上面的需求是比在微服務和 AI 上面都高幾個量級的,必須做好。在這個基礎上面,透過 ACS 產品,可以幫助客戶好好地去管理其資源。
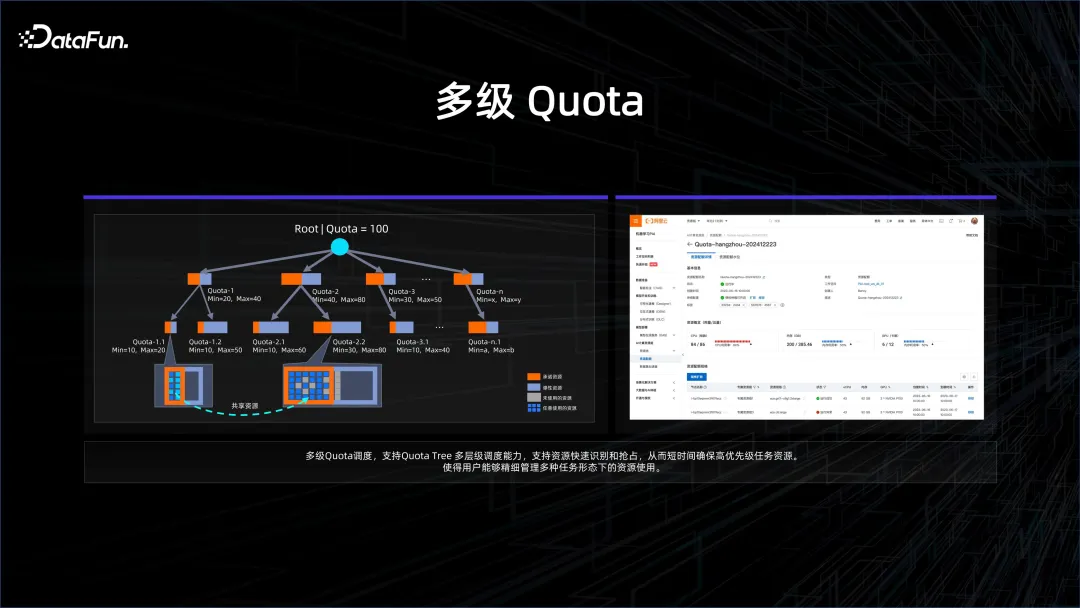
企業面臨許多需求,需要把資源管得更精細。例如企業中分各個部門、子團隊,在做大模型的時候,會把資源拆成很多方向,每個團隊去做發散性的創新,看看這個基模型到底在什麼場景下能夠得到很好的應用。但在某一個時刻,希望集中力量辦大事,把所有的算力及資源集中起來去訓練下一個迭代的基模型。為了解決這個問題,我們引入了多層 quota 管理,也就是在更高需求的任務到來時,可以有一個更高的層次,把下面所有的子 quota 合併集中起來。
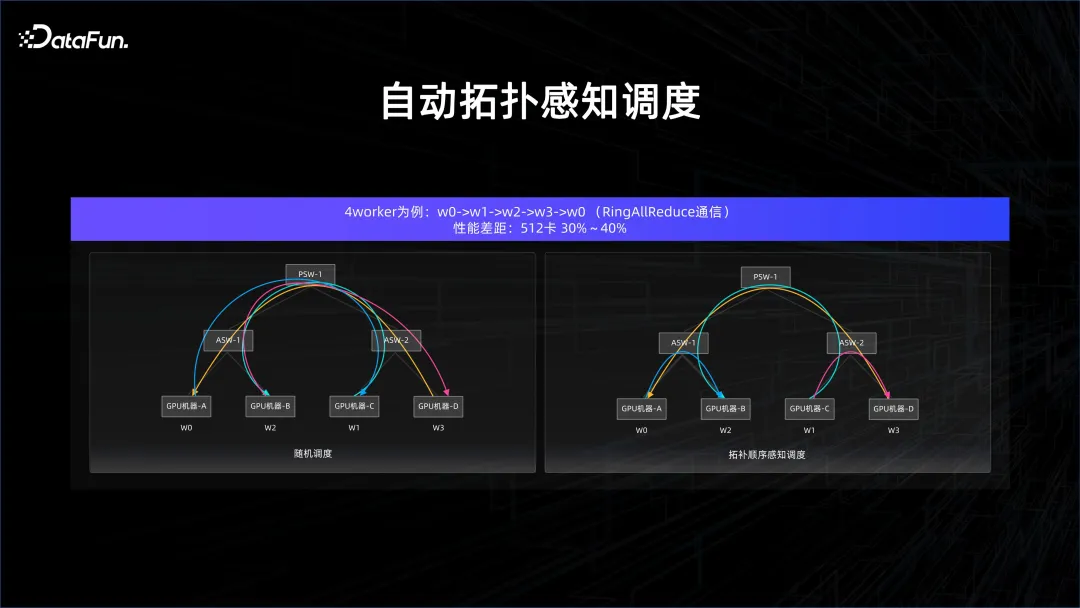
在AI 這個場景裡面其實有非常多的特殊性,有很多的情況下是同步計算,而同步計算對於延遲的敏感度非常強,並且AI 計算密度大,對於網絡的要求是非常高的。如果要保證算力,就需要供數,需要交換梯度(gradient)這些信息,並且在模型並行的時候,交換的東西會更多。在這些情況下,為了確保通訊沒有短板,就需要做基於拓樸感知的調度。
舉一個例子,在模型訓練的All Reduce 環節中,如果進行隨機調度,cross port 的交換器連接會非常多,而如果精細控制順序,那麼cross 交換器的連接就會很乾淨,這樣延遲就能夠得到很好的保證,因為不會在上層的交換器裡面發生衝突。
經過這些最佳化,效能可以大幅提升。如何把這些拓樸感知的調度下沉到整個平台的管理器上,也是 AI 加大資料平台管理需要考慮的問題。
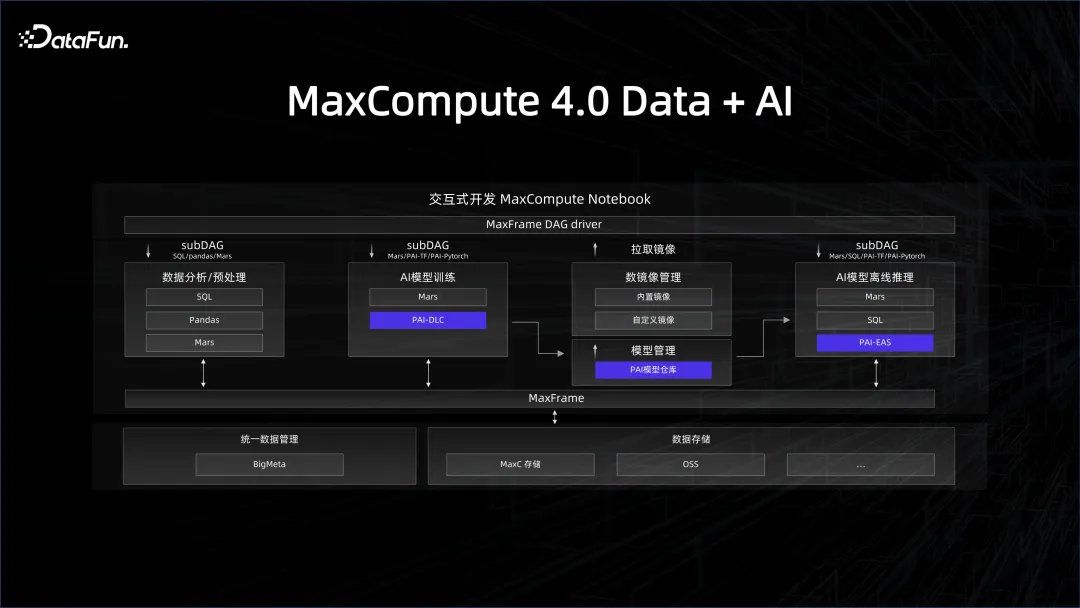
前面介紹的是資源和平台上的管理,資料的管理也是至關重要的,我們一直在耕耘的就是數倉的系統,例如資料治理、資料品質等等。要將資料系統和 AI 系統進行關聯,需要數倉提供一個 AI 友善的資料鏈路。例如在 AI 開發過程中用的是 Python 的生態,資料這邊怎麼透過一個 Python 的 SDK 去使用這個平台。 Python 最受歡迎的函式庫就是類似於pandas 這樣的data frame 資料結構,我們可以把大數據引擎的client 端包裝成pandas 的接口,這樣所有熟悉Python 的AI 開發工作者就能夠很好地去使用它背後的數據平台。這也是我們今年在 MaxCompute 上推出的 MaxFrame 框架的理念。
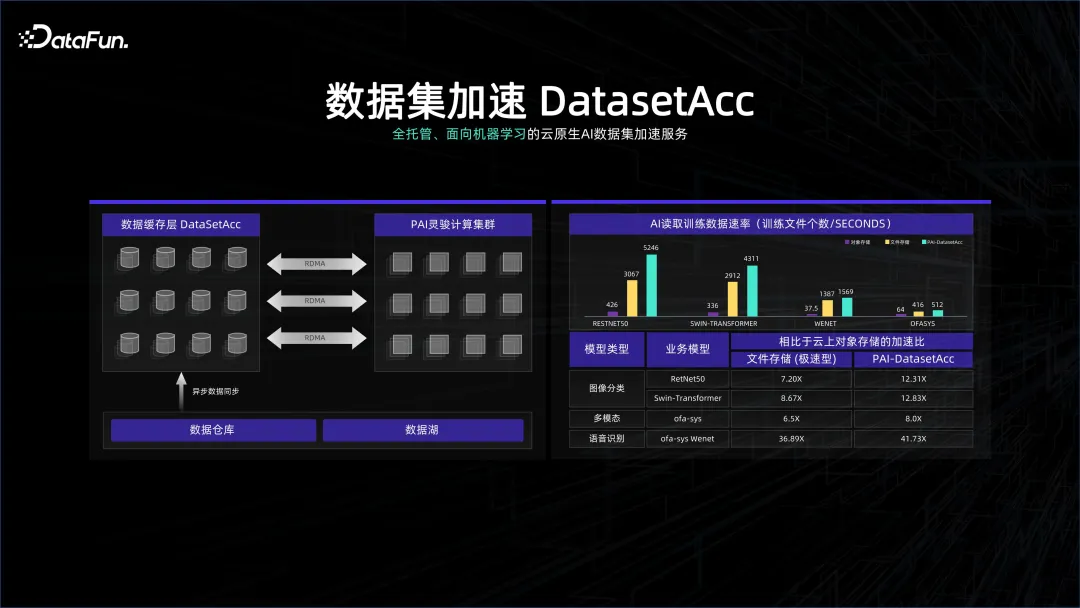
資料處理系統在許多情況下對成本的敏感度較高,有時會用更高密的儲存系統來存數倉的系統,但是為了不浪費這個系統,又會在上面佈很多GPU,這個高密的集群對於網路和GPU 都是非常苛刻的,這兩個系統很可能是存算分離的。我們的數據系統可能是偏治理、偏管理,而計算系統偏計算,可能是remote 的連接方式,雖然都在一個K8S 的管理下,但為了讓計算的時候不會等數據,我們做了數據集加速DataSetAcc,其實就是一個data cache,無縫地和遠端儲存節點的資料進行連接,幫助演算法工程師在背後把資料拉到本地的記憶體或SSD 上面,以供運算使用。
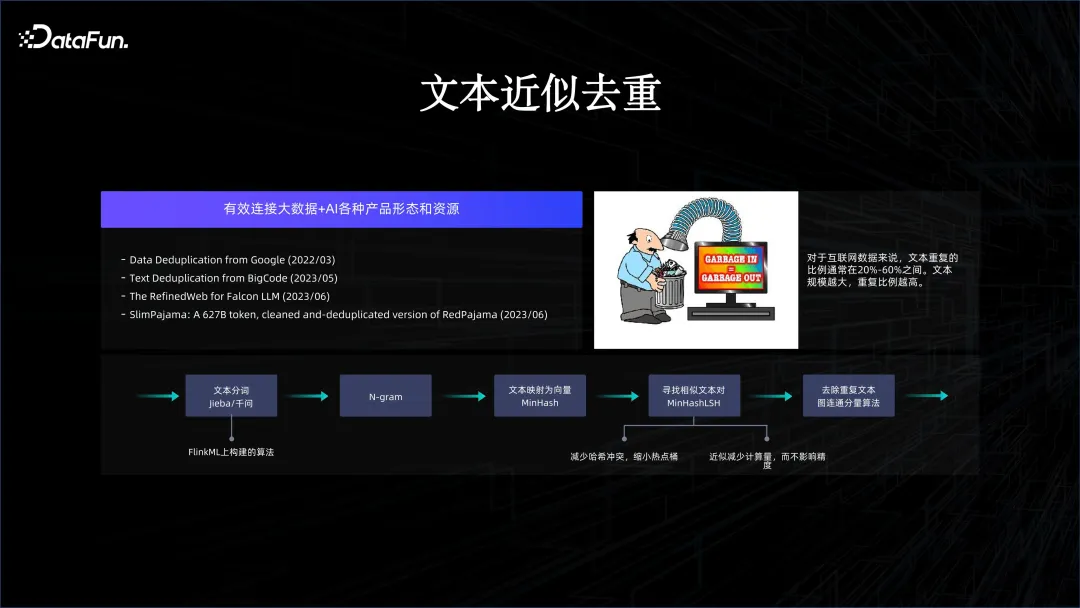
透過上述方式,使得 AI 和大數據的平台能夠有機結合在一起,這樣我們才能去做一些創新。例如,在支援許多通義系列的模型訓練時,有許多資料是需要清洗的,因為網路資料有很多重複,如何透過大數據系統去做資料的去重就很關鍵。正是因為我們把兩套系統很好的有機結合在一起,很容易在大數據平台進行資料的清洗,出來的結果能夠馬上灌給模型訓練。

前文主要介紹了大數據如何為 AI 模型訓練提供支撐。另一方面,也可以利用 AI 技術來協助資料洞察,走向 BI AI 的資料處理模式。
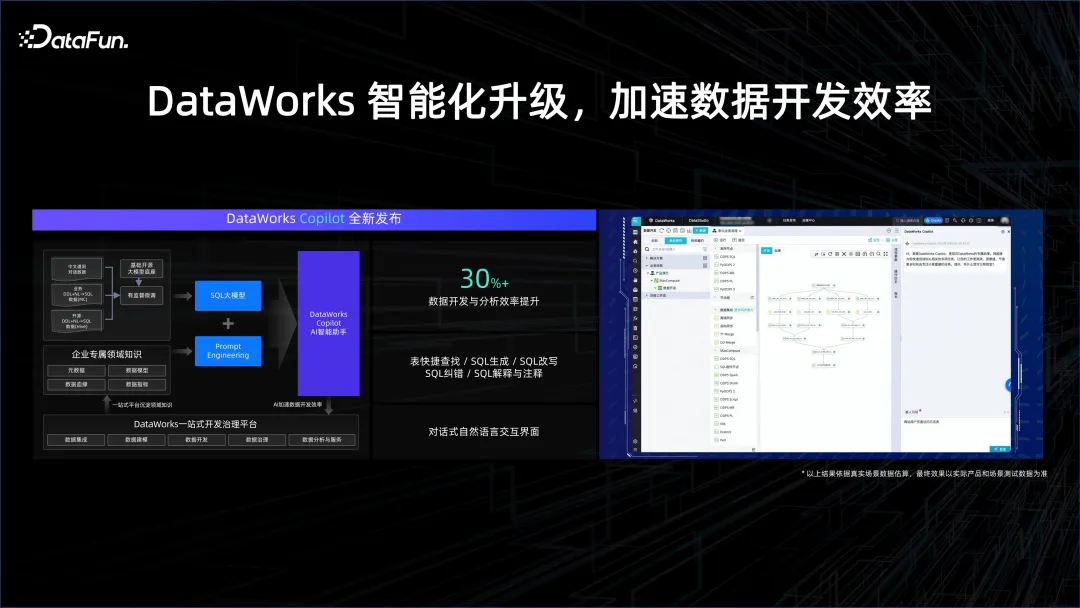
在資料處理環節,可以幫助資料分析師更簡單地去建立分析,原來可能要寫SQL,學習如何用工具與數據系統進行互動。但 AI 時代,改變了人機互動的方式,可以透過自然語言的方式跟著數據系統互動。例如 Copilot 程式設計助手,可以輔助產生 SQL,幫助完成資料開發環節中的各個步驟,進而大幅提升開發效率。

另外,還可以透過 AI 的方式來做資料洞察。例如一份數據,unique key 有多少,適合用什麼樣的方式去做 visualization,都可以用 AI 來取得。 AI 可以從各個角度去觀察數據、理解數據,實現自動的數據探查、智慧的數據查詢、圖表的生成,還有一鍵生成分析報表等等,這就是智慧的分析服務。
四、總結
以上是大數據 AI 一體化解讀的詳細內容。更多資訊請關注PHP中文網其他相關文章!