在 2024 年世界經濟論壇的一次會談中,圖靈獎得主 Yann LeCun 提出用來處理影片的模型應該學會在抽象的表徵空間中進行預測,而不是具體的像素空間 [1]。借助文字訊息的多模態視訊表徵學習可抽取利於視訊理解或內容生成的特徵,正是促進此過程的關鍵技術。 然而,當下視訊與文字描述間廣泛存在的雜訊關聯現象嚴重阻礙了視訊表徵學習。因此本文中,研究者基於最優傳輸理論,提出穩健的長視訊學習方案以應對此挑戰。這篇論文被機器學習頂會 ICLR 2024 接收為了 Oral。 
- 論文主題:Multi-granularity Correspondence Learning from Long-term Noisy Videos
- #論文地址: https://openreview.net/pdf?id=9Cu8MRmhq2
- #專案網址:https://lin-yijie.github.io/projects/Norton
- #程式碼位址:https://github.com/XLearning-SCU/2024-ICLR-Norton
影片表徵學習是多模態研究中最熱門的問題之一。大規模影片 - 語言預訓練已在多種影片理解任務中取得顯著效果,例如影片檢索、視覺問答、片段分割與定位等。目前大部分影片 - 語言預訓練工作主要面向短影片的片段理解,忽略了長影片中存在的長時關聯與依賴。 如下圖1 所示,長視訊學習核心困難是如何去編碼影片中的時序動態,目前的方案主要集中在設計客製化的視訊網路編碼器去捕捉長時依賴[2],但通常面臨很大的資源開銷。
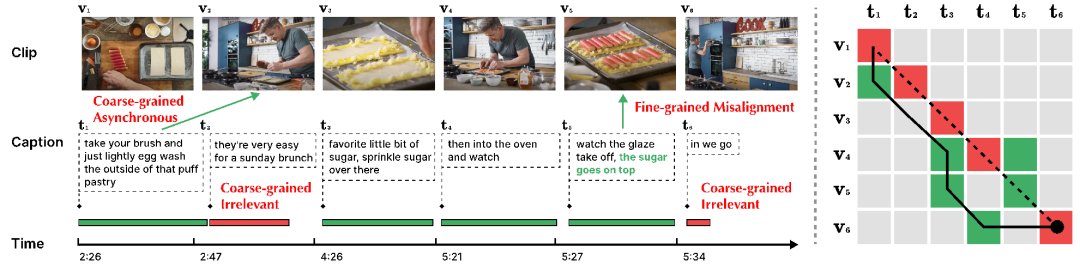
圖 1:長影片資料範例 [2]。該影片中包含了複雜的故事情節和豐富的時序動態。每個句子只能描述一個簡短的片段,理解整個影片需要具有長時關聯推理能力。 由於長影片通常採用自動語言辨識(ASR)得到對應的文字字幕,整個影片所對應的文字段落(Paragraph)可根據ASR 文字時間戳記分為多個短的文字標題(Caption),同時長影片(Video)可對應切分為多個影片片段(Clip)。對影片片段與標題進行後期融合或對齊的策略相比直接編碼整個影片更為高效,是長時時序關聯學習的一種優選方案。 然而,影片片段與文字句子間廣泛存在雜訊關聯現象(Noisy correspondence [3-4],NC),即影片內容與文字語料錯誤地對應/ 關聯在一起。如下圖 2 所示,影片與文字間會存在多粒度的雜訊關聯問題。
圖 2:多粒度雜訊關聯。此範例中影片內容依文字標題切分為 6 塊。 (左圖)綠色時間軸指示該文字可與影片內容對齊,紅色時間軸則指示該文字無法與整個影片中的內容對齊。 t5 中的綠色文字表示與影片內容 v5 有關聯的部分。 (右圖)虛線表示原本給定的對齊關係,紅色指示原本對齊中錯誤的對齊關係,綠色則指示真實的對齊關係。實線表示透過 Dynamic Time Wraping 演算法進行重新對齊的結果,其也未能很好地處理雜訊關聯挑戰。
- 粗粒度 NC(Clip-Caption 間)。粗粒度 NC 包括非同步(Asynchronous)和不相關(Irrelevant)兩類,區別在於該影片片段或標題能否與現有標題或影片片段相對應。其中「非同步」指影片片段與標題間存在時序上的錯位,例如圖 2 中 t1。由於講述者在實際執行動作的前後進行解釋,導致陳述與行動的順序不符。 「不相關」則指無法與影片片段對齊的無意義標題(例如 t2 和 t6),或無關的影片片段。根據牛津Visual Geometry Group 的相關研究[5],HowTo100M 資料集中只有約30% 的影片片段與標題在視覺上是可對齊的,而僅有15% 是原本就對齊的;
- 細粒度NC(Frame-Word 間)。針對一個影片片段,可能一句文字描述中只有部分文字與其相關。在圖 2 中,標題 t5 中「糖撒在上面」與視覺內容 v5 強相關,但動作「觀察釉面脫落」則與視覺內容並不相關。無關的單字或視訊幀可能會阻礙關鍵訊息提取,從而影響片段與標題間的對齊。
#本文提出雜訊穩健的時序最優傳輸(NOise Robust Temporal Optimal transport, Norton),透過視訊- 段落層級對比學習與片段- 標題級對比學習,以後期融合的方式從多個粒度學習視訊表徵,顯著節省了訓練時間開銷。
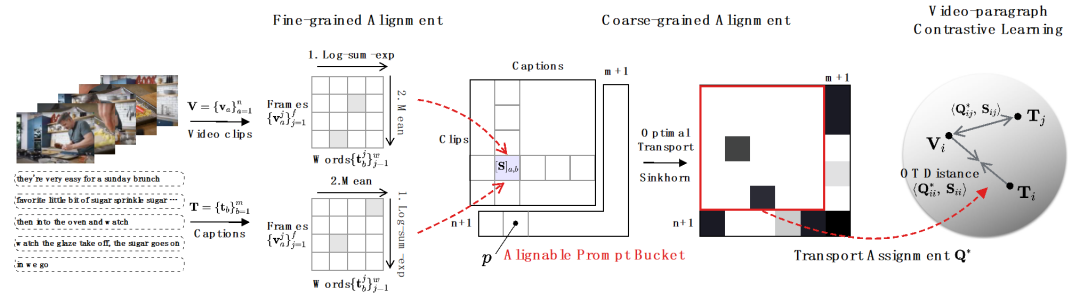
1)影片 - 段落比較。如圖 3 所示,研究者以 fine-to-coarse 的策略進行多粒度關聯學習。首先利用幀 - 詞間相關性得到片段 - 標題間相關性,並進一步聚集得到視頻 - 段落間相關性,最終通過視頻級對比學習捕捉長時序關聯。針對多粒度雜訊關聯挑戰,具體應對如下:
- #面對細粒度 NC。研究者採用log-sum-exp 近似作為Soft-maximum 算子去識別幀- 詞和詞- 幀對齊中的關鍵詞和關鍵幀,以細粒度的交互方式實現重要信息抽取,累計得到片段- 標題相似性。
- 面對粗粒度異步 NC。研究者採用最適傳輸距離作為影片片段和標題之間的距離量測。給定影片片段- 文字標題間相似性矩陣,其中表示片段與標題個數,最優傳輸目標為最大化整體對齊相似性,可天然處理時序異步或一對多(如t3與v4,v5 對應)的複雜對齊情況。
其中为均匀分布给予每个片段、标题同等权重,为传输指派或重对齐矩,可通过 Sinkhorn 算法求解。- 面向粗粒度不相关 NC。受特征匹配中 SuperGlue [6] 启发,我们设计了自适应的可对齐提示桶去尝试过滤不相关的片段与标题。提示桶是一行一列的相同值向量,拼接于相似性矩阵上,其数值代表是否可对齐的相似度阈值。提示桶可无缝融入最优传输 Sinkhorn 求解中。
通过最优传输来度量序列距离,而非直接对长视频进行建模,可显著减少计算量。最终视频 - 段落损失函数如下,其中表示第个长视频与第个文本段落间的相似性矩阵。
2)片段 - 标题对比。该损失确保视频 - 段落对比中片段与标题对齐的准确性。由于自监督对比学习会将语义相似的样本错误地作为负样本优化,我们利用最优传输识别并矫正潜在的假阴性样本:
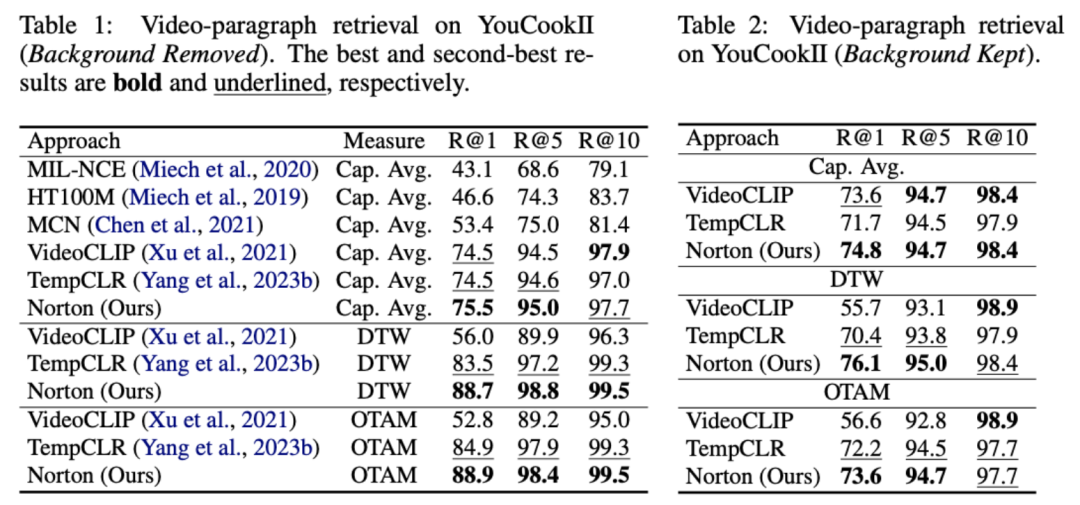
其中代表训练批次中的所有视频片段和标题个数,单位矩阵代表对比学习交叉熵损失中的标准对齐目标,代表融入最优传输矫正目标后的重对齐目标,为权重系数。本文旨在克服噪声关联以提升模型对长视频的理解能力。我们通过视频检索、问答、动作分割等具体任务进行验证,部分实验结果如下。该任务目标为给定文本段落,检索对应的长视频。在 YouCookII 数据集上,依据是否保留文本无关的视频片段,研究者测试了背景保留与背景移除两种场景。他们采用 Caption Average、DTW 与 OTAM 三种相似性度量准则。Caption Average 为文本段落中每个标题匹配一个最优视频片段,最终召回匹配数最多的长视频。DTW 和 OTAM 按时间顺序累计视频与文本段落间距离。结果如下表 1、2 所示。
表1、2 在YouCookII 數據集上的長視頻檢索性能比較牛津Visual Geometry Group 對HowTo100M 中的影片進行了手動重標註,對每個文字標題重新標註正確的時間戳。產出的 HTM-Align 資料集 [5] 包含 80 個影片與 49K 個文字。在該資料集上進行視訊檢索主要驗證模型是否過度擬合了雜訊關聯,結果如下表 9 所示。
##總結與展望
#本文是雜訊關聯學習[3][4]— 資料錯配/ 錯誤關聯的深入延續,研究多模態視訊- 文字預訓練面臨的多粒度雜訊關聯問題,所提出的長視訊學習方法能夠以較低資源開銷擴展到更廣泛的視訊資料。 展望未來,研究者可進一步探討多種模態間的關聯問題,例如視訊往往包含視覺、文字及音訊訊號;可嘗試結合外部大語言模型(LLM)或多模態模型(BLIP-2)來清洗和重組織文本語料;並探索將噪音作為模型訓練正激勵的可能性,而非僅僅抑制噪音的負面影響。 #1. 本站,「Yann LeCun :生成模型不適合處理視頻,AI 得在抽象空間中進行預測”,2024-01-23.2.Sun, Y., Xue , H., Song, R., Liu, B., Yang, H., & Fu, J. (2022). Long-form video-language pre-training with multimodal temporal contrastive learning. Advances in neural information processing systems, 35, 38032-38045.3.Huang, Z., Niu, G., Liu, X., Ding, W., Xiao, X. , Wu, H., & Peng, X. (2021). Learning with noisy correspondence for cross-modal 生產。 4.Lin, Y., Yang, M., Yu, J., Hu, P., Zhang, C., & Peng, X. (2023). Graph matching with bi-level noisy correspondence . In Proceedings of the IEEE/CVF international conference on computer vision.
5.Han, T., Xie, W., & Zisserman, A. ( 2022). Temporal alignment networks for long-term video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 2906-2916).
6.Sarlin, P. E., DeTone, D., Malisiewicz, T., & Rabinovich, A. (2020). Superglue: Learning feature matching with graph neural networks. In Proceedings of the IEEE/CVF conference on compternuter and pattern recognition (pp. 4938-4947).
以上是ICLR 2024 Oral:長影片中噪音關聯學習,單卡訓練僅需1天的詳細內容。更多資訊請關注PHP中文網其他相關文章!




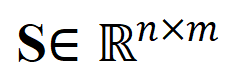 ,其中
,其中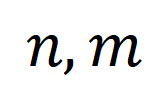 表示片段與標題個數,最優傳輸目標為最大化整體對齊相似性,可天然處理時序異步或一對多(如t3與v4,v5 對應)的複雜對齊情況。
表示片段與標題個數,最優傳輸目標為最大化整體對齊相似性,可天然處理時序異步或一對多(如t3與v4,v5 對應)的複雜對齊情況。 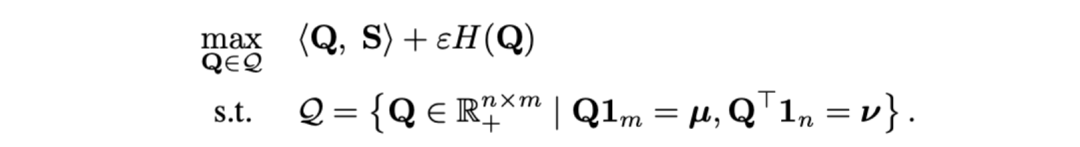
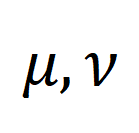 为均匀分布给予每个片段、标题同等权重,
为均匀分布给予每个片段、标题同等权重,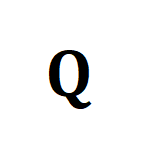 为传输指派或重对齐矩,可通过 Sinkhorn 算法求解。
为传输指派或重对齐矩,可通过 Sinkhorn 算法求解。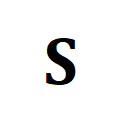 上,其数值代表是否可对齐的相似度阈值。提示桶可无缝融入最优传输 Sinkhorn 求解中。
上,其数值代表是否可对齐的相似度阈值。提示桶可无缝融入最优传输 Sinkhorn 求解中。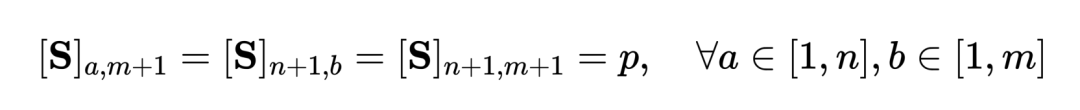
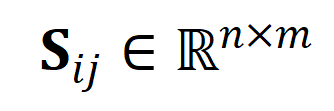 表示第
表示第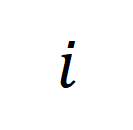 个长视频与第
个长视频与第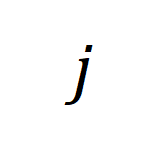 个文本段落间的相似性矩阵。
个文本段落间的相似性矩阵。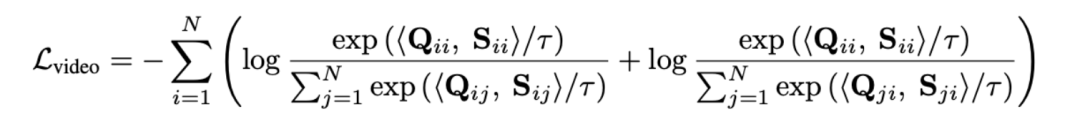
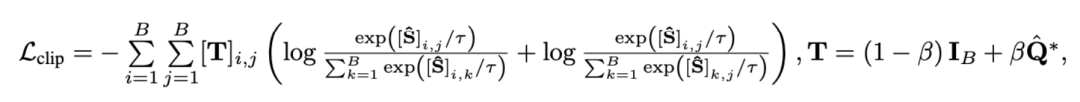
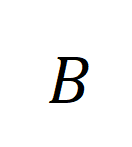 代表训练批次中的所有视频片段和标题个数,单位矩阵
代表训练批次中的所有视频片段和标题个数,单位矩阵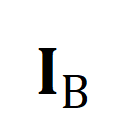 代表对比学习交叉熵损失中的标准对齐目标,
代表对比学习交叉熵损失中的标准对齐目标,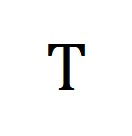 代表融入最优传输矫正目标
代表融入最优传输矫正目标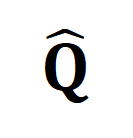 后的重对齐目标,
后的重对齐目标,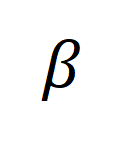 为权重系数。
为权重系数。