



Sora 在 2024 年初的驚人表現成為了新的標桿,激勵所有研究文生影片的人士爭相追趕。每位研究者都懷著復現 Sora 成果的渴望,爭分奪秒地努力著。
根據OpenAI 揭露的技術報告,Sora 的一個重要創新點是將視覺數據轉換為patch 的統一表示形式,並透過Transformer 和擴散模型相結合,展現了出色的擴展性。隨著報告的發布,Sora 的核心研發人員 William Peebles 和紐約大學電腦科學助理教授謝賽寧合作撰寫的《Scalable Diffusion Models with Transformers》論文備受研究者關注。研究界希望透過論文中提出的 DiT 架構,探索再現 Sora 的可行性途徑。
最近,新加坡國立大學尤洋團隊開源的一個名為 OpenDiT 的專案為訓練和部署 DiT 模式開啟了新思路。
OpenDiT是一個專為提升DiT應用程式的訓練和推理效率而設計的系統,它不僅易於操作,而且速度快且記憶體利用高效。該系統涵蓋了文字到視訊生成和文字到圖像生成等功能,旨在為用戶提供高效、便利的體驗。
專案網址:https://github.com/NUS-HPC-AI-Lab/OpenDiT
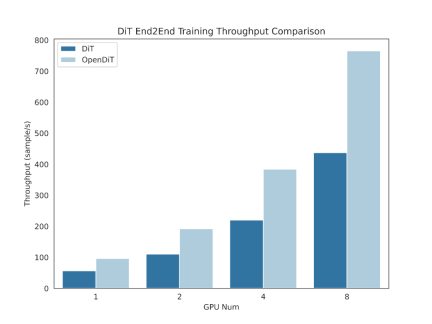
OpenDiT 方法介紹
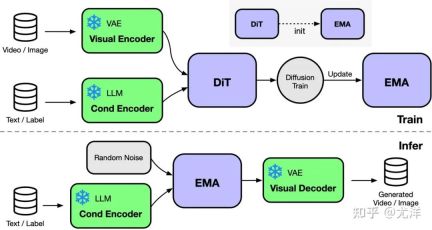
OpenDiT 提供由Colossal-AI 支援的Diffusion Transformer (DiT) 的高效能實作。在訓練時,視訊和條件資訊分別被輸入到對應的編碼器中,作為DiT模型的輸入。隨後,透過擴散方法進行訓練和參數更新,最終將更新後的參數同步至EMA(Exponential Moving Average)模型。推理階段則直接使用EMA模型,將條件資訊作為輸入,從而產生對應的結果。
圖片來源:https://www.zhihu.com/people/berkeley-you-yang
OpenDiT 利用了ZeRO 平行策略,將DiT 模型參數分佈到多台機器上,初步降低了顯存壓力。為了取得更好的性能與精準度平衡,OpenDiT 也採用了混合精準度的訓練策略。具體而言,模型參數和優化器使用 float32 進行存儲,以確保更新的準確性。在模型計算的過程中,研究團隊為 DiT 模型設計了 float16 和 float32 的混合精度方法,以在維持模型精度的同時加速計算過程。
DiT 模型中使用的 EMA 方法是一種用於平滑模型參數更新的策略,可以有效提高模型的穩定性和泛化能力。但是會額外產生一份參數的拷貝,增加了顯存的負擔。為了進一步降低這部分顯存,研究團隊將 EMA 模型分片,並分別儲存在不同的 GPU 上。在訓練過程中,每個 GPU 只需計算和儲存自己負責的部分 EMA 模型參數,並在每次 step 後等待 ZeRO 完成更新後進行同步更新。
FastSeq
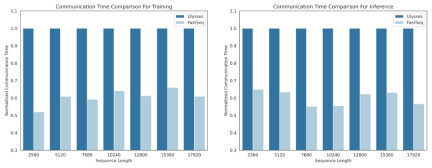
#在DiT 等視覺生成模型領域,序列並行性對於有效的長序列訓練和低延遲推理是必不可少的。
然而,DeepSpeed-Ulysses、Megatron-LM Sequence Parallelism 等現有方法在應用於此類任務時面臨局限性—— 要么是引入過多的序列通信,要么是在處理小規模序列並行時缺乏效率。
為此,研究團隊提出了 FastSeq,一種適用於大序列和小規模並行的新型序列並行。 FastSeq 透過為每個 transformer 層僅使用兩個通訊運算子來最小化序列通信,利用 AllGather 來提高通訊效率,並策略性地採用非同步 ring 將 AllGather 通訊與 qkv 計算重疊,進一步優化效能。
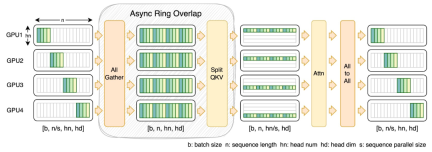
算符最佳化
在DiT 模型中引入adaLN 模組將條件資訊融入視覺內容,雖然這項操作對模型的性能提升至關重要,但也帶來了大量的逐元素操作,並且在模型中被頻繁調用,降低了整體的計算效率。為了解決這個問題,研究團隊提出了高效的 Fused adaLN Kernel,將多次操作合併成一次,從而增加了計算效率,並且減少了視覺資訊的 I/O 消耗。
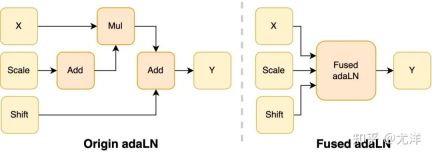
圖片來源:https://www.zhihu.com/people/berkeley-you-yang
簡單來說,OpenDiT 有以下效能優勢:
#1、在GPU 上加速高達80%,50%的記憶體節省
- #設計了高效率的算子,包括針對DiT設計的Fused AdaLN,以及FlashAttention、Fused Layernorm 和HybridAdam。
- 採用混合平行方法,包括 ZeRO、Gemini 和 DDP。對 ema 模型進行分片也進一步降低了記憶體成本。
2、FastSeq:一種新穎的序列平行方法
- 專為類似DiT 的工作負載而設計,在這些應用中,序列通常較長,但參數與LLM 相比較小。
- 節點內序列並行可節省高達 48% 的通訊量。
- 打破單一 GPU 的記憶體限制,減少整體訓練和推理時間。
3、易於使用
- #只需幾行程式碼的修改,即可獲得巨大的性能提升。
- 使用者無需了解分散式訓練的實作方式。
4、文字到圖像和文字到影片產生完整pipeline
- 研究人員和工程師可以輕鬆使用OpenDiT pipeline 並將其應用於實際應用,而無需修改平行部分。
- 研究團隊透過在 ImageNet 上進行文字到圖像訓練來驗證 OpenDiT 的準確性,並發布了檢查點(checkpoint)。
安裝與使用
要使用OpenDiT,首先要安裝先決條件:
- Python >= 3.10
- PyTorch >= 1.13(建議使用>2.0 版本)
- CUDA > = 11.6
建議使用Anaconda 建立一個新環境(Python >= 3.10)來執行範例:
conda create -n opendit pythnotallow=3.10 -yconda activate opendit
#安裝ColossalAI:
git clone https://github.com/hpcaitech/ColossalAI.gitcd ColossalAIgit checkout adae123df3badfb15d044bd416f0cf29f250bc86pip install -e .
#安裝OpenDiT:
git clone https://github.com/oahzxl/OpenDiTcd OpenDiTpip install -e .
#(可選擇但推薦)安裝函式庫以加快訓練和推理速度:
# Install Triton for fused adaln kernelpip install triton# Install FlashAttentionpip install flash-attn# Install apex for fused layernorm kernelgit clone https://github.com/NVIDIA/apex.gitcd apexgit checkout 741bdf50825a97664db08574981962d66436d16apip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-optinotallow=--cpp_ext" --config-settings "--build-optinotallow=--cuda_ext" ./--global-optinotallow="--cuda_ext" --global-optinotallow="--cpp_ext"
#圖片生成
- 你可以執行以下指令來訓練DiT 模型:
# Use scriptbash train_img.sh# Use command linetorchrun --standalone --nproc_per_node=2 train.py \--model DiT-XL/2 \--batch_size 2
- 預設禁用所有加速方法。以下是訓練過程中一些關鍵要素的詳細資訊:
- plugin: 支援 ColossalAI、zero2 和 ddp 使用的 booster 外掛程式。預設是 zero2,建議啟用 zero2。
- mixed_ precision:混合精準度訓練的資料類型,預設是 fp16。
- grad_checkpoint: 是否啟用梯度檢查點。這節省了訓練過程的記憶體成本。預設值為 False。建議在內存足夠的情況下禁用它。
enable_modulate_kernel: 是否啟用 modulate 核心最佳化,以加快訓練過程。預設值為 False,建議在 GPU
# Use scriptbash sample_img.sh# Use command linepython sample.py --model DiT-XL/2 --image_size 256 --ckpt ./model.pt####
视频生成
你可以通过执行以下命令来训练视频 DiT 模型:
# train with sciptbash train_video.sh# train with command linetorchrun --standalone --nproc_per_node=2 train.py \--model vDiT-XL/222 \--use_video \--data_path ./videos/demo.csv \--batch_size 1 \--num_frames 16 \--image_size 256 \--frame_interval 3# preprocess# our code read video from csv as the demo shows# we provide a code to transfer ucf101 to csv formatpython preprocess.py
使用 DiT 模型执行视频推理的代码如下所示:
# Use scriptbash sample_video.sh# Use command linepython sample.py \--model vDiT-XL/222 \--use_video \--ckpt ckpt_path \--num_frames 16 \--image_size 256 \--frame_interval 3
DiT 复现结果
为了验证 OpenDiT 的准确性,研究团队使用 OpenDiT 的 origin 方法对 DiT 进行了训练,在 ImageNet 上从头开始训练模型,在 8xA100 上执行 80k step。以下是经过训练的 DiT 生成的一些结果:

损失也与 DiT 论文中列出的结果一致:
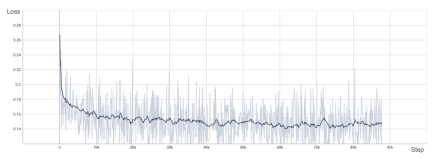
要复现上述结果,需要更改 train_img.py 中的数据集并执行以下命令:
torchrun --standalone --nproc_per_node=8 train.py \--model DiT-XL/2 \--batch_size 180 \--enable_layernorm_kernel \--enable_flashattn \--mixed_precision fp16
感兴趣的读者可以查看项目主页,了解更多研究内容。
以上是想訓練類Sora模型嗎?尤洋團隊OpenDiT實現80%加速的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 烹飪創新:人工智能如何改變食品服務Apr 12, 2025 pm 12:09 PM
烹飪創新:人工智能如何改變食品服務Apr 12, 2025 pm 12:09 PMAI增強食物準備 在新生的使用中,AI系統越來越多地用於食品製備中。 AI驅動的機器人在廚房中用於自動化食物準備任務,例如翻轉漢堡,製作披薩或組裝SA
 Python名稱空間和可變範圍的綜合指南Apr 12, 2025 pm 12:00 PM
Python名稱空間和可變範圍的綜合指南Apr 12, 2025 pm 12:00 PM介紹 了解Python函數中變量的名稱空間,範圍和行為對於有效編寫和避免運行時錯誤或異常至關重要。在本文中,我們將研究各種ASP
 視覺語言模型(VLMS)的綜合指南Apr 12, 2025 am 11:58 AM
視覺語言模型(VLMS)的綜合指南Apr 12, 2025 am 11:58 AM介紹 想像一下,穿過美術館,周圍是生動的繪畫和雕塑。現在,如果您可以向每一部分提出一個問題並獲得有意義的答案,該怎麼辦?您可能會問:“您在講什麼故事?
 聯發科技與kompanio Ultra和Dimenty 9400增強優質陣容Apr 12, 2025 am 11:52 AM
聯發科技與kompanio Ultra和Dimenty 9400增強優質陣容Apr 12, 2025 am 11:52 AM繼續使用產品節奏,本月,Mediatek發表了一系列公告,包括新的Kompanio Ultra和Dimenty 9400。這些產品填補了Mediatek業務中更傳統的部分,其中包括智能手機的芯片
 本週在AI:沃爾瑪在時尚趨勢之前設定了時尚趨勢Apr 12, 2025 am 11:51 AM
本週在AI:沃爾瑪在時尚趨勢之前設定了時尚趨勢Apr 12, 2025 am 11:51 AM#1 Google推出了Agent2Agent 故事:現在是星期一早上。作為AI驅動的招聘人員,您更聰明,而不是更努力。您在手機上登錄公司的儀表板。它告訴您三個關鍵角色已被採購,審查和計劃的FO
 生成的AI遇到心理摩托車Apr 12, 2025 am 11:50 AM
生成的AI遇到心理摩托車Apr 12, 2025 am 11:50 AM我猜你一定是。 我們似乎都知道,心理障礙由各種chat不休,這些chat不休,這些chat不休,混合了各種心理術語,並且常常是難以理解的或完全荒謬的。您需要做的一切才能噴出fo
 原型:科學家將紙變成塑料Apr 12, 2025 am 11:49 AM
原型:科學家將紙變成塑料Apr 12, 2025 am 11:49 AM根據本週發表的一項新研究,只有在2022年製造的塑料中,只有9.5%的塑料是由回收材料製成的。同時,塑料在垃圾填埋場和生態系統中繼續堆積。 但是有幫助。一支恩金團隊
 AI分析師的崛起:為什麼這可能是AI革命中最重要的工作Apr 12, 2025 am 11:41 AM
AI分析師的崛起:為什麼這可能是AI革命中最重要的工作Apr 12, 2025 am 11:41 AM我最近與領先的企業分析平台Alteryx首席執行官安迪·麥克米倫(Andy Macmillan)的對話強調了這一在AI革命中的關鍵但不足的作用。正如Macmillan所解釋的那樣,原始業務數據與AI-Ready Informat之間的差距


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

WebStorm Mac版
好用的JavaScript開發工具

SecLists
SecLists是最終安全測試人員的伙伴。它是一個包含各種類型清單的集合,這些清單在安全評估過程中經常使用,而且都在一個地方。 SecLists透過方便地提供安全測試人員可能需要的所有列表,幫助提高安全測試的效率和生產力。清單類型包括使用者名稱、密碼、URL、模糊測試有效載荷、敏感資料模式、Web shell等等。測試人員只需將此儲存庫拉到新的測試機上,他就可以存取所需的每種類型的清單。

Dreamweaver Mac版
視覺化網頁開發工具

Safe Exam Browser
Safe Exam Browser是一個安全的瀏覽器環境,安全地進行線上考試。該軟體將任何電腦變成一個安全的工作站。它控制對任何實用工具的訪問,並防止學生使用未經授權的資源。

