
用擴散模型產生網路參數,LeCun點贊尤洋團隊新研究

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2024-02-26 08:10:03540瀏覽
如果你有被 Sora 生成的影片震撼到,那你就已經見識過擴散模型在視覺生成方面的巨大潛力。當然,擴散模型的潛力不止於此,它在許多其它不同領域也有著讓人期待的應用前景,更多案例可參閱本站不久前的報道《爆火Sora背後的技術,一文綜述擴散模型的最新發展方向》。
最近,由新加坡國立大學的尤洋團隊、加州大學柏克萊分校以及Meta AI Research 所進行的研究發現了擴散模型的一個新應用:用於產生神經網路的模型參數。

論文網址:https://arxiv.org/pdf/2402.13144.pdf
項目網址:https://github.com/NUS-HPC-AI-Lab/Neural-Network-Diffusion
論文標題:Neural Network Diffusion
#這種方法似乎使得可以利用現有的神經網路輕鬆產生新的模型! Yann LeCun 對此表示讚賞並分享。生成的模型不僅能夠保持原始模型的性能,甚至可能超越它。
擴散模型最初源自於非平衡熱力學的概念。在2015年,Jascha Sohl-Dickstein等人在他們的論文《Deep Unsupervised Learning using Nonequilibrium Thermodynamics》中首次使用擴散過程來逐步消除輸入中的噪音,從而產生清晰的圖像。
之後的 DDPM 和 DDIM 等研究工作優化了擴散模型,使其訓練範式有了前向和反向過程的鮮明特徵。
當時,擴散模型產生的影像的品質還未達到理想水準。
GuidedDiffusion 這項工作進行了充分的消融研究並發現了一個更好的架構;這項開創性的工作開始讓擴散模型在影像品質上超越基於 GAN 的方法。之後出現的 GLIDE、Imagen、DALL·E 2 和 Stable Diffusion 等模型已經可以產生照片級真實感的影像。
儘管擴散模型在視覺生成領域已經取得了巨大成功,但它們在其它領域的潛力仍相對欠開發。
新加坡國立大學、加州大學柏克萊分校、Meta AI Research 最近的這項研究則發掘出了擴散模型的一個驚人能力:產生高性能的模型參數。
要知道,這項任務與傳統的視覺生成任務有著根本性的差異!參數生成任務的重心是創造能在給定任務上表現良好的神經網路參數。先前已有研究者從先驗和機率建模方面探索過這項任務,例如隨機神經網路和貝葉斯神經網路。但是,之前還沒有人研究使用擴散模型來產生參數。
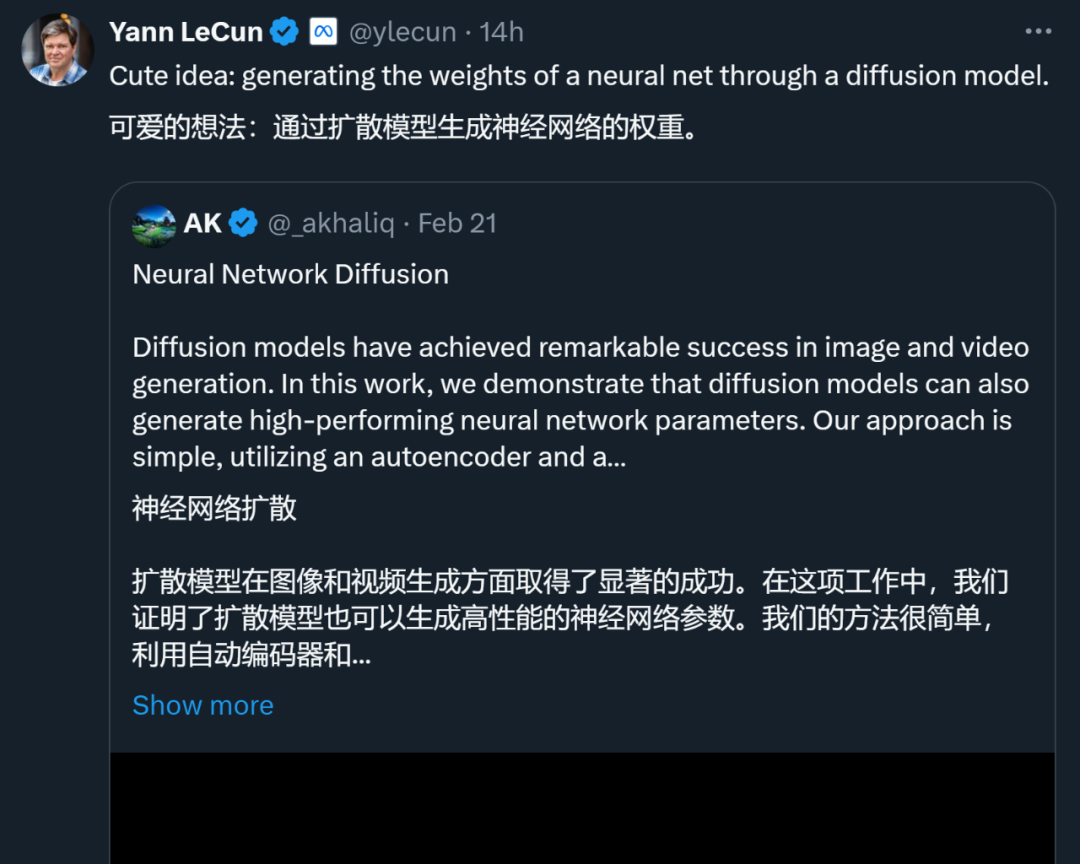
如圖1 所示,仔細觀察神經網路的訓練過程與擴散模型,可以發現基於擴散的圖像生成方法與隨機梯度下降(SGD)學習過程有一些共同點:1)神經網路的訓練過程和擴散模型的反向過程都可以被看作是從隨機噪聲/初始化轉換成特定分佈的過程;2)透過多次添加噪聲,可以將高品質影像和高性能參數降級為簡單分佈,例如高斯分佈。
該團隊基於上述觀察提出了一種用於參數生成的新方法:neural network diffusion,即神經網路擴散,縮寫為p-diff,其中的p是指參數(parameter)。
此方法的想法很直接,就是使用標準的隱擴散模型來合成神經網路的參數集,因為擴散模型能夠將給定的隨機分佈轉換為特定的分佈。
他們的方法很簡單:組合使用一個自動編碼器和一個標準隱擴散模型來學習高效能參數的分佈。
首先,對於使用 SGD 最佳化器訓練的模型參數子集,訓練一個自動編碼器來擷取這些參數的隱含特性。然後,使用一個標準隱擴散模型從雜訊開始合成隱含表徵。最後,用經過訓練的自動編碼器來處理合成的隱含表徵,得到新的高效能模型參數。
這種新方法表現出了這兩個特點:1)在多個資料集和架構上,其效能表現能在數秒時間內與其訓練資料(即SGD 最佳化器訓練的模型)媲美,甚至還能有所超越;2)產生的模型與訓練所得到的模型差異較大,這說明新方法能夠合成新參數,而非記憶訓練樣本。
神經網路擴散
介紹擴散模型
##擴散模型通常由前向和反向過程構成,這些過程組成一個多步驟的鍊式過程並且可透過時間步驟索引。前向過程。給定一個樣本 x_0 ∼ q(x),前向過程是在 T 個步驟中逐漸加入高斯噪聲,得到 x_1、x_2……x_T。
反向過程。不同於前向過程,反向過程的目標是訓練一個能遞歸地移除 x_t 中的雜訊的去雜訊網路。過程是多個步驟的反向過程,此時 t 從 T 一路降至 0。
神經網路擴散方法概述
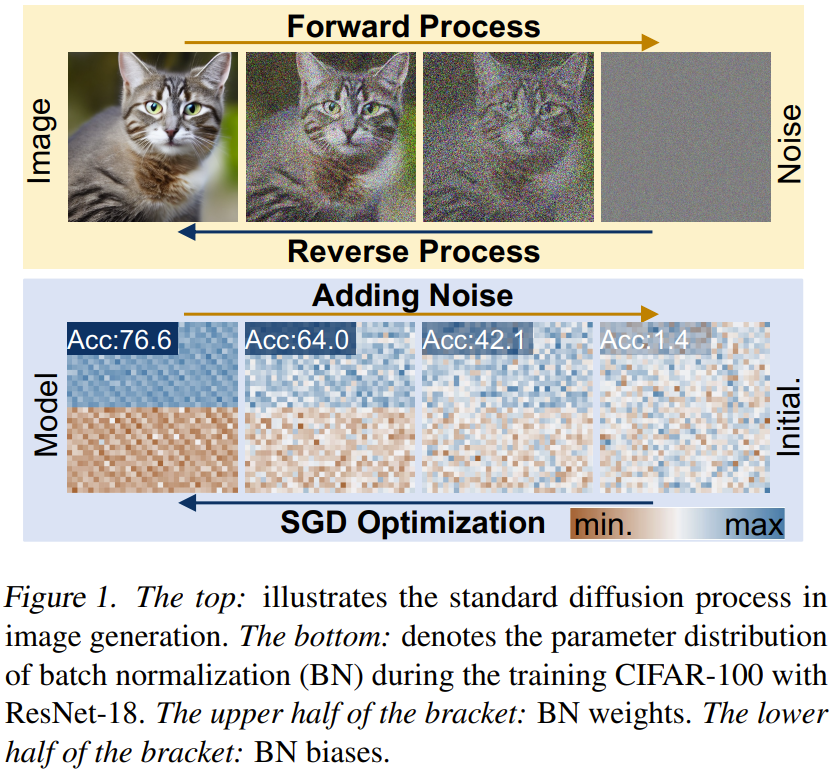
神經網路擴散(p-diff)這種新方法的目標是基於隨機雜訊產生高效能參數。如圖 2 所示,此方法包含兩個流程:參數自動編碼器和參數產生。
給定一組已經過訓練的高性能模型,首先選取其參數的子集並將其展平為一維向量。
之後,使用一個編碼器來擷取這些向量的隱含表徵,同時還有一個解碼器負責基於這些隱含表徵重建出參數。
然後,訓練一個標準的隱擴散模型來基於隨機雜訊合成這種隱含表徵。
訓練之後,就可以使用 p-diff 透過這樣的鍊式過程來產生新參數:隨機雜訊 → 反向過程 → 已訓練的解碼器 → 產生的參數。
實驗
團隊在論文中給出了詳細的實驗設置,可幫助其他研究者復現其結果,詳見原論文,我們這裡更關注其結果和消融研究。
結果
表 1 是在 8 個資料集和 6 種架構上與兩種基準方法的結果比較。

基於這些結果,可以得到以下觀察:1)在大多數實驗案例中,新方法能取得與兩種基準方法媲美或更優的結果。這顯示新提出的方法可以有效率地學習高效能參數的分佈,並能基於隨機雜訊產生更優的模型。 2)新方法在多個不同資料集上的表現都很好,這說明這種方法具有很好的泛化效能。
消融研究和分析
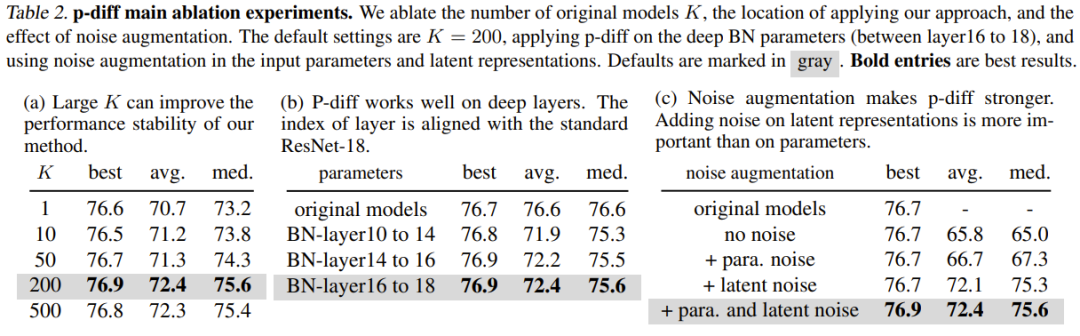
#表2(a) 展示了不同訓練資料規模(即原始模型的數量)的影響。可以看到,不同數量的原始模型的最佳結果之間的性能差異其實不大。
為了研究 p-diff 在其它歸一化層深度上的有效性,該團隊還探索了新方法合成其它淺層參數的性能。為了確保 BN 參數的數量相等,該團隊為三組 BN 層(它們位於不同深度的層之間)實現了新提出的方法。實驗結果見表 2(b),可以看到在所有深度的 BN 層設定上,新方法的表現(最佳準確度)都優於原始模型。
雜訊增強的目的是提升訓練自動編碼器的穩健性和泛化能力。該團隊對噪音增強在輸入參數和隱含表徵方面的應用進行了消融研究。結果見表 2(c)。
先前,實驗評估的都是新方法在合成模型參數子集(即批歸一化參數)的效果。那我們不禁要問:能否使用此方法合成模型的整體參數?
為了解答這個問題,團隊使用兩個小型架構進行了實驗:MLP-3 和 ConvNet-3。其中 MLP-3 包含三個線性層和 ReLU 活化函數,ConvNet-3 則包含三個卷積層和一個線性層。不同於先前提到的訓練資料收集策略,團隊基於 200 個不同的隨機種子從頭開始訓練了這些架構。
表 3 給出了實驗結果,其中將新方法與兩種基準方法(原始方法和整合方法)進行了比較。其中報告了 ConvNet-3 在 CIFAR-10/100 以及 MLP-3 在 CIFAR-10 和 MNIST 上的結果比較和參數數量。

這些實驗顯示新方法在合成整體模型參數方面的有效性和泛化能力,也就是說新方法實現了與基準方法相當或更優的性能。這些結果也能體現新方法的實際應用潛力。
但團隊也在論文中表明目前還無法合成 ResNet、ViT 和 ConvNeXt 等大型架構的整體參數。這主要是受限於 GPU 記憶體的極限。
至於為什麼這種新方法能夠有效地產生神經網路參數,該團隊也嘗試探索分析了原因。他們使用 3 個隨機種子從頭開始訓練了 ResNet-18 並對其參數進行了可視化,如圖 3 所示。
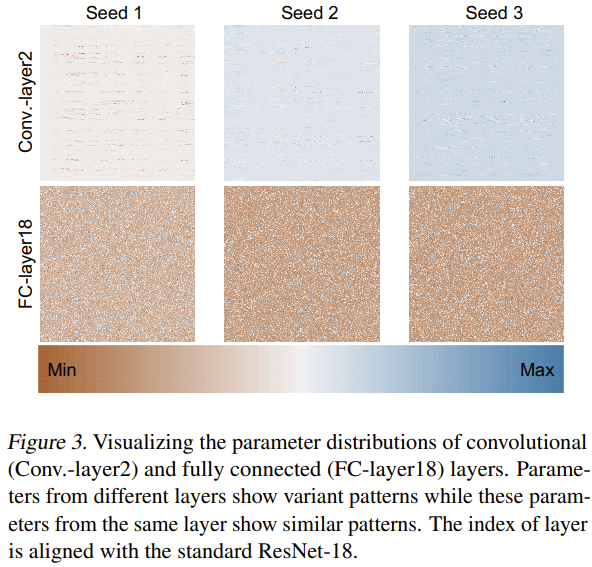
他們透過 min-max 歸一化方法,分別得到了不同層的參數分佈的熱力圖。基於卷積層(Conv.-layer2)和全連接層(FC-layer18)的可視化結果,可以看到這些層中確實存在一定的參數模式。透過學習這些模式,新方法就能產生高效能的神經網路參數。
p-diff 是單純靠記憶嗎?
p-diff 看起來能產生神經網路參數,但它究竟是產生參數還是只是記住了參數呢?團隊就此做了一番研究,比較了原始模型和生成模型的差異。
為了進行量化比較,他們提出了一個相似度指標。簡單來說,這個指標就是透過計算兩個模型在錯誤預測結果上的交並比(IoU)來決定它們的相似度。然後他們基於此進行了一些比較研究和視覺化。比較結果見圖 4。
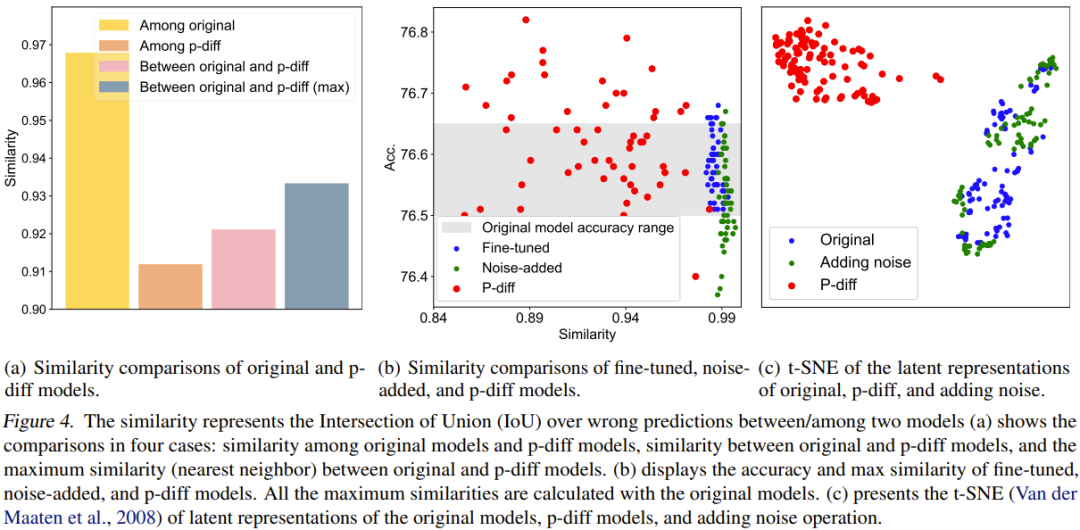
圖 4(a) 報告了原始模型和 p-diff 模型之間的相似度比較,其中涉及 4 種比較方案。
可以看到,產生的模型之間的差異比原始模型之間的差異大得多。另外,原始模型和產生的模型之間的最大相似度也低於原始模型之間的相似度。這足以表明,p-diff 可以產生與其訓練資料(即原始模型)不同的新參數。
該團隊也將新方法與微調模型和添加雜訊的模型進行了比較。結果見圖 4(b)。
可以看到,微調模型和添加雜訊的模型很難超過原始模型。此外,微調模型或添加雜訊的模型與原始模型之間的相似度非常高,這表明這兩種操作方法無法獲得全新且高效能的模型。但是,新方法產生的模型則表現出了多樣的相似度以及優於原始模型的性能。
該團隊也比較了隱含表徵。結果見圖 4(c)。可以看到,p-diff 可以產生全新的隱含表徵,而添加雜訊方法只會在原始模型的隱含表徵周圍進行插值。
該團隊也視覺化了 p-diff 流程的軌跡。具體而言,他們繪出了在推理階段的不同時間步驟所產生的參數軌跡。圖 5(a) 給出了 5 條軌跡(使用了 5 種不同的隨機雜訊初始化)。圖中紅心是原始模型的平均參數,灰色區域是其標準差(std)。
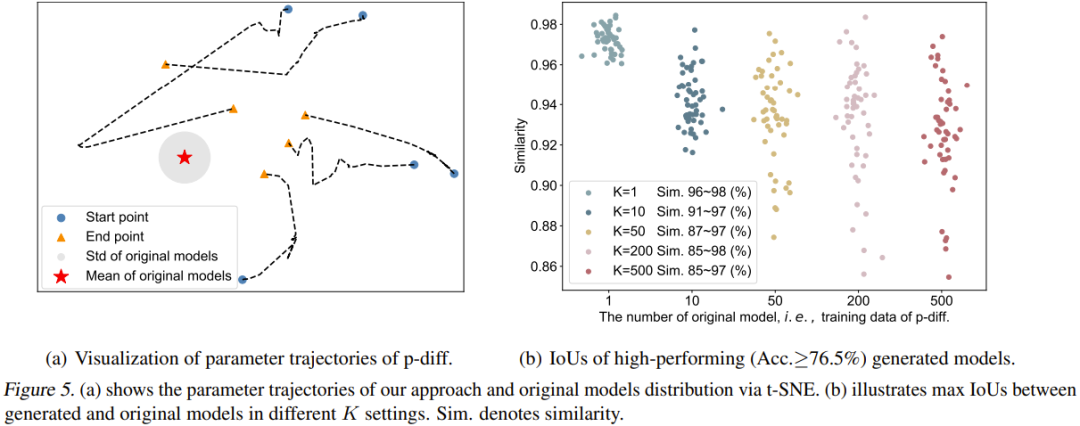
隨著時間步驟增加,產生的參數整體上會更接近原始模型。但也能看出,這些軌跡的終點(橘色三角形)與平均參數仍有一些距離。另外,這五條軌跡的形狀也很多樣化。
最後,團隊研究了原始模型的數量(K)對生成的模型的多樣性的影響。圖 5(b) 視覺化地展示了不同 K 時原始模型與產生的模型之間的最大相似度。具體來說,他們的做法是產生 50 個模型,透過持續生成參數,直到生成的 50 個模型在所有情況下的表現都優於 76.5%。
可以看到,當 K=1 時,相似度很高且範圍窄,說明這時候產生的模型基本上是記憶了原始模型的參數。隨著 K 增大,相似度範圍也變大了,這表明新方法可以產生與原始模型不同的參數。
以上是用擴散模型產生網路參數,LeCun點贊尤洋團隊新研究的詳細內容。更多資訊請關注PHP中文網其他相關文章!