
Linux記憶體管理:如何實現虛擬記憶體和實體記憶體的轉換和分配

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2024-02-10 17:24:261374瀏覽
在Linux系統中,記憶體管理是作業系統最重要的部分之一。它負責將有限的實體記憶體分配給多個進程,並提供虛擬記憶體的抽象,使得每個進程都有自己的位址空間,並能夠保護和共享記憶體。本文將介紹Linux記憶體管理的原理與方法,包括虛擬記憶體、實體記憶體、邏輯記憶體、線性記憶體等概念,以及Linux記憶體管理的基本模型、系統呼叫、實作方式等。
本文以32位元機器為準,串講一些記憶體管理的知識點。
\1. 虛擬位址、實體位址、邏輯位址、線性位址
虛擬位址又叫線性位址。 linux沒有採用分段機制,所以邏輯位址和虛擬位址(線性位址)(在使用者狀態,核心態邏輯位址專指下文說的線性偏移前的位址)是一個概念。實體位址自不必提起。核心的虛擬位址和實體位址,大部分只差一個線性偏移量。使用者空間的虛擬位址和實體位址則採用了多層頁表進行映射,但仍稱之為線性位址。
\2. DMA/HIGH_MEM/NROMAL 分區
在x86結構中,Linux核心虛擬位址空間劃分0~3G為使用者空間,3~4G為核心空間(注意,核心可以使用的線性位址只有1G)。核心虛擬空間(3G~4G)再劃分為三種類型的區:
ZONE_DMA 3G之後起始的16MB
ZONE_NORMAL 16MB~896MB
ZONE_HIGHMEM 896MB ~1G
由於核心的虛擬和實體位址只差一個偏移:實體位址 = 邏輯位址 – 0xC0000000。所以如果1G核心空間完全用來線性映射,顯然實體記憶體也只能存取到1G區間,這顯然是不合理的。 HIGHMEM就是為了解決這個問題,專門開闢的一塊不必線性映射,可以靈活定制映射,以便訪問1G以上物理內存的區域。從網路上扣來一張圖,
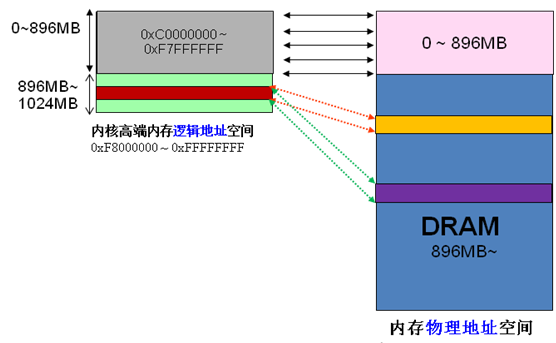
高階記憶體的劃分,又如下圖,
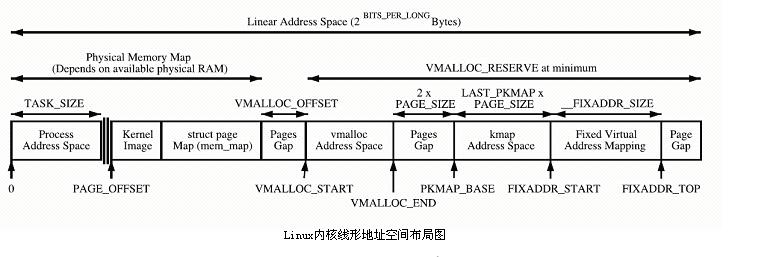
核心直接映射空間 PAGE_OFFSET~VMALLOC_START,kmalloc和__get_free_page()分配的是這裡的頁面。二者是藉助slab分配器,直接分配實體頁再轉換為邏輯位址(實體位址連續)。適合分配小段記憶體。此區域 包含了核心鏡像、實體頁框表mem_map等資源。
核心動態映射空間 VMALLOC_START~VMALLOC_END,被vmalloc用到,可表示的空間大。
核心永久映射空間 PKMAP_BASE ~ FIXADDR_START,kmap
核心臨時映射空間 FIXADDR_START~FIXADDR_TOP,kmap_atomic
3.夥伴演算法與slab分配器
夥伴Buddy演算法解決了外部碎片問題.核心在每個zone區管理可用的頁面,以2的冪級(order)大小排成鍊錶佇列,存放在free_area數組。
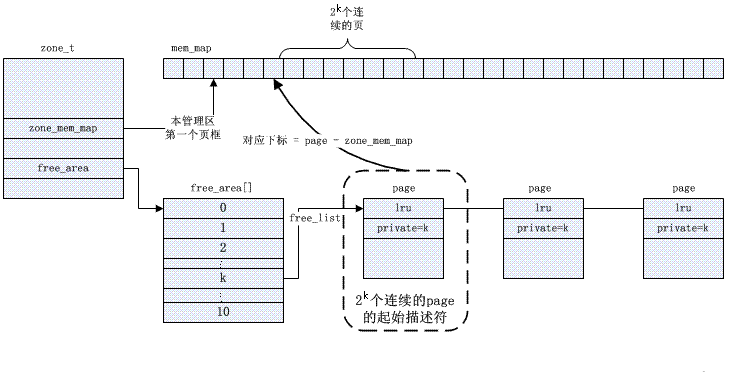
具體buddy管理基於點陣圖,其分配回收頁面的演算法描述如下,
buddy演算法舉例描述:
假設我們的系統記憶體只有***16******個頁面*****RAM*。因為RAM只有16個頁面,我們只需用四個等級(orders)的夥伴位圖(因為最大連續記憶體大小為******16******個頁面* **),如下圖所示。
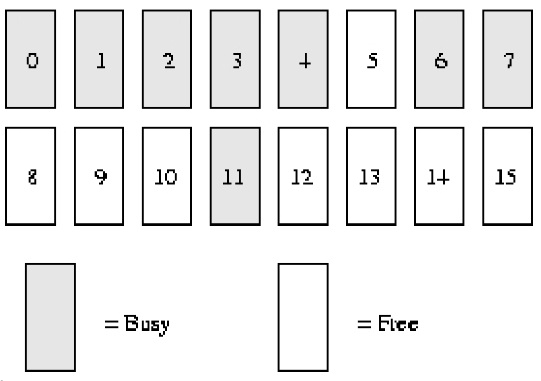

order(0)bimap有8個bit位元(***頁面最多******16******個頁面,所以******16/ 2***)
order(1)bimap有4個bit位元(***order******(******0******)******bimap**** **有******8******個******bit******位元***,所以8/2);
也就是order(1)第一塊由***兩個頁框****page1* ***與******page2*****組成與*order(1)第2塊由兩個頁框****page3* ***與******page4** ****組成,這兩個區塊之間有一個******bit****位元*
#order(2)bimap有2個bit位元(***order******(******1******)******bimap**** **有******4******個******bit******位元***,所以4/2)
order(3)bimap有1個bit位元(***order******(******2******)******bimap**** **有******4******個******bit******位元***,所以2/2)
在order(0),第一個bit表示開始***的******2******個頁面***,第二個bit表示接下來的2個頁面,以此類推。因為頁面4已分配,而頁面5空閒,故第三個bit為1。
同樣在order(1)中,bit3是1的原因是一個夥伴完全空閒(頁8和9),和它對應的伙伴(頁10和11)卻並非如此,故以後回收頁面時,可以合併。
分配過程
***當我們需要******order******(******1******)的空閒頁面區塊時,***則執行以下步驟:
1、初始空閒鍊錶為:
order(0): 5, 10
#order(1): 8 [8,9]
#order(2): 12 [12,13,14,15]
#order(3):
#2、從上面空閒鍊錶中,我們可以看出,order(1)鍊錶上,有*一個空閒的頁面區塊,把它分配給用戶,並從該鍊錶中刪除。 *
3、當我們再需要一個order(1)的區塊時,同樣我們從order(1)空閒鍊錶開始掃描。
4、若在***order******(******1******)上沒有空閒頁面區塊***,那麼我們就到更高的等級( order)上找,order(2)。
5、此時(***order******(******1*****)上沒有空閒頁面區塊*)有一個空閒頁面區塊,該區塊是從頁面12開始。此頁面區塊被分割成兩個稍微小一些order(1)的頁面區塊,[12,13]和[14,15]。 [14,15]頁面區塊加到order******(******1*****)空閒鍊錶*,同時[12******,******13]****頁面區塊傳回給使用者。 *
6、最終空閒鍊錶為:
order(0): 5, 10
#order(1): 14 [14,15]
order(2):
#order(3):
#回收過程
***當我們回收頁面******11******(******order 0****)時,則執行以下步驟:*
***1******、******找到在******order******(******0******)夥伴位圖中代表頁面******11******的位元****,計算使用下列公示:*
#*index =* *page_idx >> (order 1)*
#*= 11 >> (0 1)*
#*= 5*
#2、檢查上面一步計算位圖中對應bit的值。若該bit值為1,則和我們臨近的,有一個空閒夥伴。 Bit5的值為1(注意是從bit0開始的,Bit5即為第6bit),因為它的夥伴頁面10是空閒的。
3、現在我們重新設定該bit的值為0,因為此時兩個夥伴(頁面10和頁面11)完全空閒。
4、我們將頁10,從order(0)空閒鍊錶中摘除。
5、此時,我們對2個空閒頁面(頁10和11,order(1))進行進一步操作。
6、新的空閒頁面是從頁面10開始的,於是我們在order(1)的伙伴位圖中找到它的索引,看是否有空閒的伙伴,以進一步進行合併操作。使用第一步驟中的計算公司,我們得到bit 2(第3位)。
7、Bit 2(order(1)點陣圖)同樣也是1,因為它的夥伴頁面區塊(頁8和9)是空閒的。
8、重新設定bit2(order(1)點陣圖)的值,然後在order(1)鍊錶中刪除該空閒頁面區塊。
9、現在我們合併成了4頁面大小(從頁面8開始)的空閒區塊,從而進入另外的層級。在order(2)中找出夥伴位圖對應的bit值,是bit1,且值為1,需進一步合併(原因同上)。
10、從oder(2)鍊錶中摘除空閒頁面區塊(從頁面12開始),進而將該頁面區塊和前面合併得到的頁面區塊進一步合併。現在我們得到從頁面8開始,大小為8個頁面的空閒頁面區塊。
11、我們進入另一個級別,order(3)。它的位元索引為0,它的值同樣為0。這意味著對應的夥伴不是全部空閒的,所以沒有再進一步合併的可能。我們只設定該bit為1,然後將合併得到的空閒頁面區塊放入order(3)空閒鍊錶中。
12、最終我們得到大小為8個頁面的空閒區塊,

buddy避免內部碎片的努力
物理記憶體的碎片化一直是Linux作業系統的弱點之一,儘管已經有人提出了很多解決方法,但是沒有哪個方法能夠徹底的解決,memory buddy分配就是解決方法之一。我們知道磁碟檔案也有碎片化問題,但是磁碟檔案的碎片化只會減慢系統的讀寫速度,並不會導致功能性錯誤,而且我們還可以在不影響磁碟功能的前提的下,進行磁碟碎片整理。而實體記憶體碎片則截然不同,實體記憶體和作業系統結合的太過於緊密,以至於我們很難在運行時,進行實體記憶體的移(這一點上,磁碟碎片要容易的多;實際上mel gorman已經提交了記憶體緊縮的patch,只是還沒有被主線核心接收)。因此解決的方向主要放在預防碎片上。在2.6.24核心開發期間,防止碎片的核心功能加入了主線核心。在了解反碎片的基本原理前,先對記憶體頁面做個歸類:
\1. 不可移動頁面 unmoveable:在記憶體中位置必須固定,無法移動到其他地方,核心核心分配的大部分頁面都屬於這一類。
\2. 可回收頁面reclaimable:不能直接移動,但是可以回收,因為還可以從某些來源重建頁面,例如映射檔案的資料屬於這種類別,kswapd會依照一定的規則,週期性的回收這類頁面。
\3. 可移動頁面 movable:可以隨意的移動。屬於使用者空間應用程式的頁屬於此類頁面,它們是透過頁表映射的,因此我們只需要更新頁表項,並把資料複製到新位置就可以了,當然要注意,一個頁面可能被多個進程共享,對應多個頁表項。
防止碎片的方法就是把這三類page放在不同的鍊錶上,避免不同類型頁面互相干擾。考慮這樣的情形,一個不可移動的頁面位於可移動頁面中間,那麼我們移動或回收這些頁面後,這個不可移動的頁面阻礙著我們獲得更大的連續物理空閒空間。
另外,每個zone區都有一個自己的失活淨頁面隊列,與此對應的是兩個跨zone的全域隊列,失活臟頁隊列 和 活躍隊列。這些隊列都是透過page結構的lru指標鏈入的。
思考:失活隊列的意義是什麼(見
#slab分配器:解決內部碎片問題
核心通常依賴小物件的分配,它們會在系統生命週期內進行無數次分配。 slab 快取分配器透過對類似大小(遠小於1page)的物件進行快取而提供此功能,從而避免了常見的內部碎片問題。此處暫貼一圖,關於其原理,常見參考文獻3。很顯然,slab機制是基於buddy演算法的,前者是對後者的細化。
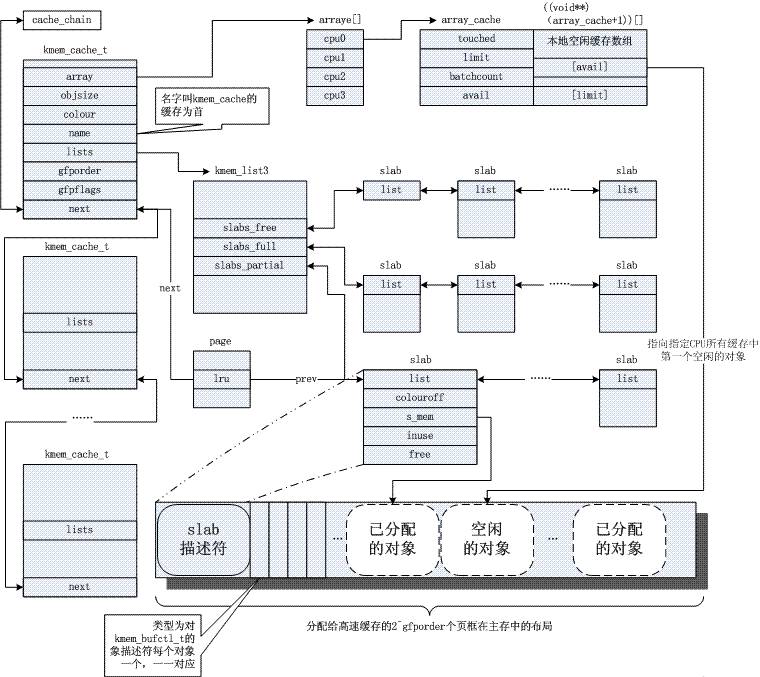
4.頁面回收/專注機制
#關於頁面的使用
#
在之前的一些文章中,我們了解到linux核心會在很多情況下分配頁面。
1.核心程式碼可能呼叫alloc_pages之類的函數,從管理實體頁面的夥伴系統(管理區zone上的free_area空閒鍊錶)直接分配頁面(請參閱《linux核心記憶體管理淺析》)。例如:驅動程式可能用這種方式來分配快取;創建進程時,核心也是透過這種方式分配連續的兩個頁面,作為進程的thread_info結構和核心堆疊;等等。從夥伴系統分配頁面是最基本的頁面分配方式,其他的記憶體分配都是基於這種方式的;
2.核心中的許多物件都是用slab機制來管理的(請參閱《linux slub分配器淺析》)。 slab就相當於物件池,它將頁面“格式化”成“物件”,存放在池中供人使用。當slab中的物件不足時,slab機制會自動從夥伴系統中指派頁面,並「格式化」成新的物件;
3.磁碟高速緩存(請參閱《linux核心檔案讀寫淺析》)。讀寫檔案時,頁面被從夥伴系統分配並用於磁碟高速緩存,然後磁碟上的檔案資料被載入到對應的磁碟高速緩存頁面中;
4、記憶體映射。這裡所謂的記憶體映射其實是指將記憶體頁面映射到使用者空間,供使用者進程使用。進程的task_struct->mm結構中的每一個vma就代表著一個映射,而映射的真正實作則是在使用者程式存取對應的記憶體位址之後,由缺頁異常所引起的頁面被分配和頁表被更新(見《linux核心記憶體管理淺析》);
頁面回收簡述
#
有頁面分配,就會有頁面回收。頁面回收的方法大致上可分為兩種:
一是主動釋放。就像使用者程式透過free函數釋放曾經透過malloc函數分配的記憶體一樣,頁面的使用者明確知道頁面什麼時候要被使用,什麼時候又不再需要了。
上面提到的前兩種分配方式,一般都是由內核程式主動釋放的。對於直接從夥伴系統分配的頁面,這是由使用者使用free_pages之類的函數主動釋放的,頁面釋放後被直接放歸夥伴系統;從slab中分配的物件(使用kmem_cache_alloc函數),也是由使用者主動釋放的(使用kmem_cache_free函數)。
另一種頁面回收方式是透過linux核心提供的頁框回收演算法(PFRA)進行回收。頁面的使用者一般會將頁面當作某種緩存,以提高系統的運作效率。快取一直存在固然好,但是如果快取沒有了也不會造成什麼錯誤,只是效率受影響而已。頁面的使用者不明確知道這些快取頁面什麼時候最好被保留,什麼時候最好被回收,這些都交由PFRA來關心。
簡單來說,PFRA要做的事就是回收這些可以被回收的頁面。為了避免系統陷入頁面緊缺的困境,PFRA會在核心執行緒中周期性地被呼叫運行。或者由於系統已經頁面緊缺,試圖分配頁面的核心執行流程因為沒有所需的頁面,而同步地呼叫PFRA。
上述的後兩種分配方式,一般是由PFRA來進行回收的(或由類似刪除檔案、進程退出、這樣的過程來同步回收)。
PFRA回收一般頁面
#
而對於上述的前兩種頁面分配方式(直接分配頁面和透過slab分配物件),也有可能需要透過PFRA來回收。
頁面的使用者可以向PFRA註冊回呼函數(使用register_shrink函數)。然後由PFRA在適當的時機來呼叫這些回調函數,以觸發對應頁面或物件的回收。
其中較為典型的是對dentry的回收。 dentry是由slab指派的,用來表示虛擬檔案系統目錄結構的物件。在dentry的引用記數被減為0的時候,dentry並不是直接被釋放,而是被放到一個LRU鍊錶中緩存起來,方便後續的使用。 (請參閱《linux核心虛擬檔案系統淺析》。)
而這個LRU鍊錶中的dentry最終是需要被回收的,於是虛擬檔案系統在初始化時,呼叫register_shrinker註冊了回收函數shrink_dcache_memory。
系統中所有檔案系統的超級區塊物件被存放在一個鍊錶中,shrink_dcache_memory函數掃描這個鍊錶,取得每個超級區塊的未被使用dentry的LRU,然後從中回收一些最老的dentry。隨著dentry的釋放,對應的inode將被減引用,也可能引起inode被釋放。
inode被釋放後也是放在一個未使用鍊錶中,虛擬檔案系統在初始化時也呼叫register_shrinker註冊了回呼函數shrink_icache_memory,用來回收這些未使用的inode,從而inode中關聯的磁碟快取也將被釋放。
另外,隨著系統的運行,slab中可能會存在很多的空閒物件(例如在對某一物件的使用高峰過後)。 PFRA中的cache_reap函數就用來回收這些多餘的空閒對象,如果某些空閒的物件剛好能夠還原成一個頁面,則這個頁面可以被釋放回夥伴系統;
cache_reap函數要做的事情說起來很簡單。系統中所有存放物件池的kmem_cache結構連成一個鍊錶,cache_reap函數掃描其中的每個物件池,然後尋找可以回收的頁面,並將其回收。 (當然,實際的過程要更複雜一點。)
關於記憶體映射
#
前面說到,磁碟快取和記憶體映射一般由PFRA來進行回收。 PFRA對這兩者的回收是很類似的,實際上,磁碟高速緩存很可能就被映射到了用戶空間。下面簡單對記憶體映射做一些介紹:
記憶體映射分為檔案映射和匿名映射。
文件映射是指代表這個映射的vma對應到一個檔案中的某個區域。這種映射方式相對較少被使用者態程式明確地使用,使用者態程式一般習慣於open一個檔案、然後read/write去讀寫檔案。
而實際上,使用者程式也可以使用mmap系統呼叫將一個檔案的某個部分映射到記憶體上(對應到一個vma),然後以存取的方式去讀寫檔案。儘管用戶程式較少這樣使用,但是用戶進程中卻充斥著這樣的映射:進程正在執行的可執行程式碼(包括可執行檔、lib庫檔)就是以這樣的方式被映射的。
在《linux核心檔讀寫淺析》一文中,我們並沒有討論關於檔案映射的實作。實際上,文件映射是將文件的磁碟高速緩存中的頁面直接映射到了用戶空間(可見,文件映射的頁面是磁碟高速緩存頁面的子集),用戶可以0拷貝地對其進行讀寫。而使用read/write的話,則會在使用者空間的記憶體和磁碟快取間發生一次拷貝。
匿名映射相對於檔案映射,代表這個映射的vma沒有對應到檔案。對於使用者空間普通的記憶體分配(堆疊空間、堆疊空間),都屬於匿名映射。
顯然,多個進程可能透過各自的檔案映射來映射到同一個檔案上(例如大多數進程都映射了libc庫的so檔);那匿名映射呢?實際上,多個進程也可能透過各自的匿名映射來映射到同一段實體記憶體上,這種情況是由於fork之後父子進程共享原來的物理記憶體(copy-on-write)而引起的。
檔案映射又分為共享映射和私有映射。私有映射時,如果程序對映射的位址空間進行寫入操作,則映射對應的磁碟快取並不會直接被寫入。而是將原有內容複製一份,然後再寫這個複製品,並且當前進程的對應頁面映射將切換到這個複製品上去(寫時複製)。也就是說,寫入操作是只有自己可見的。而對於共享映射,寫入操作則會影響到磁碟高速緩存,是大家都可見的。
哪些頁面****該回收
#
至於回收,磁碟高速緩存的頁面(包括檔案映射的頁面)都是可以被丟棄並回收的。但是如果頁面是髒頁面,則丟棄之前必須將其寫回磁碟。
而匿名映射的頁面則都是不可以丟棄的,因為頁面裡面存有使用者程式正在使用的數據,丟棄之後數據就沒辦法還原了。相較之下,磁碟快取頁面中的資料本身是保存在磁碟上的,可以復現。
於是,要回收匿名映射的頁面,只好先把頁面上的資料轉儲到磁碟,這就是頁面交換(swap)。顯然,頁面交換的代價相對更高一些。
匿名對映的頁面可以交換到磁碟上的交換檔案或交換分割區上(分割區即是設備,設備即也是檔案。所以下文統稱為交換檔案)。
於是,除非頁面被保留或被上鎖(頁面標記PG_reserved/PG_locked被置位。某些情況下,核心需要暫時性地將頁面保留,避免被回收),所有的磁碟高速緩存頁面都可回收,所有的匿名映射頁面都可交換。
儘管可以回收的頁面很多,但是顯然PFRA應當盡可能少地去回收/交換(因為這些頁面要從磁碟恢復,需要很大的代價)。所以,PFRA僅當必要時才回收/交換一部分很少被使用的頁面,每次回收的頁面數是一個經驗值:32。
於是,所有這些磁碟快取頁面和匿名映射頁面都被放到了一組LRU裡面。 (實際上,每個zone就有一組這樣的LRU,頁面都會放到自己對應的zone的LRU。)
一組LRU由幾對鍊錶組成,有磁碟高速緩存頁面(包括文件映射頁面)的鍊錶、匿名映射頁面的鍊錶、等。一對鍊錶其實是active和inactive兩個鍊錶,前者是最近使用過的頁面、後者是最近未使用的頁面。
進行頁面回收的時候,PFRA要做兩件事情,一是將active鍊錶中最近最少使用的頁面移動到inactive鍊錶、二是嘗試將inactive鍊錶中最近最少使用的頁面回收。
確定最近最少使用
#
現在就有一個問題了,要怎麼確定active/inactive鍊錶中哪些頁面是最近最少使用的呢?
一種方法是排序,當頁面被存取時,將其移動到鍊錶的尾部(假設回收從頭部開始)。但這意味著頁面在鍊錶中的位置可能頻繁移動,並且移動之前還必須先上鎖(可能有多個CPU在同時存取),這樣做對效率影響很大。
linux核心採用的是標記加順序的辦法。當頁面在active和inactive兩個鍊錶之間移動時,總是將其放置到鍊錶的尾部(同上,假設回收從頭部開始)。
頁面沒有在鍊錶間移動時,並不會調整它們的順序。而是透過訪問標記來表示頁面是否剛被訪問過。如果inactive鍊錶中已設定訪問標記的頁面再被訪問,則將其移動到active鍊錶中,並且清除訪問標記。 (實際上,為了避免存取衝突,頁面並不會直接從inactive鍊錶移動到active鍊錶,而是有一個pagevec中間結構作為緩衝,以避免鎖定鍊錶。)
頁面的存取標記有兩種情況,一是放在page->flags中的PG_referenced標記,在頁面被存取時該標記置位。對於磁碟高速緩存中(未被映射)的頁面,使用者進程透過read、write之類的系統呼叫去存取它們,系統呼叫程式碼中會將對應頁面的PG_referenced標記置位。
而對於記憶體映射的頁面,使用者進程可以直接存取它們(不經過核心),所以這種情況下的存取標記不是由核心來設定的,而是由mmu。將虛擬位址對應成實體位址後,mmu會在對應的頁表項上置一個accessed標誌位,表示頁面被存取。 (同樣的道理,mmu會在被寫的頁面所對應的頁表項上置一個dirty標誌,表示頁面是髒頁面。)
頁面的存取標記(包括上面兩種標記)將在PFRA處理頁面回收的過程中被清除,因為訪問標記顯然是應該有有效期的,而PFRA的運行週期就代表這個有效期。 page->flags中的PG_referenced標記可以直接清除,而頁表項中的accessed位元則需要透過頁面找到其對應的頁表項後才能清除(請參閱下文的「反向映射」)。
那麼,回收過程又是怎麼掃描LRU鍊錶的呢?
由於存在多組LRU(系統中有多個zone,每個zone又有多組LRU),如果PFRA每次回收都掃描所有的LRU找出其中最值得回收的若干個頁面的話,回收算法的效率顯然不夠理想。
linux內核PFRA所使用的掃描方法是:定義一個掃描優先權,透過這個優先權換算出在每個LRU上應該掃描的頁數。整個回收演算法以最低的優先權開始,先掃描每個LRU中最近最少使用的幾個頁面,然後試圖回收它們。如果一遍掃描下來,已經回收了足夠數量的頁面,則本次回收過程結束。否則,增加優先級,再重新掃描,直到足夠數量的頁面被回收。而如果始終無法回收足夠數量的頁面,則優先順序將增加到最大,也就是所有頁面將會被掃描。這時,就算回收的頁面數量還是不足,回收過程都會結束。
每次掃描一個LRU時,都從active鍊錶和inactive鍊錶取得目前優先權對應數目的頁面,然後再對這些頁面做處理:如果頁面不能被回收(如被保留或被上鎖),則放回對應鍊錶頭部(同上,假設回收從頭部開始);否則如果頁面的存取標記置位,則清除該標記,並將頁面放回對應鍊錶尾部(同上,假設回收從頭部開始);否則頁面將從active鍊錶移至inactive鍊錶、或從inactive鍊錶回收。
被掃描到的頁面根據存取標記是否置位來決定其去留。那麼這個訪問標記是如何設定的呢?有兩個途徑,一是用戶透過read/write之類的系統呼叫存取檔案時,核心操作磁碟快取中的頁面,會設定這些頁面的存取標記(設定在page結構中);二是進程直接存取已對應的頁面時,mmu會自動為對應的頁表項加上存取標記(設定在頁表的pte)。關於訪問標記的判斷就基於這兩個資訊。 (給定一個頁面,可能有多個pte引用到它。如何知道這些pte是否被設定了存取標記?那就需要透過反向映射找到這些pte。下面會講到。)
PFRA不傾向於從active鍊錶回收匿名映射的頁面,因為用戶進程使用的內存一般相對較少,且回收的話需要進行交換,代價較大。所以在記憶體剩餘較多、匿名映射所佔比例較少的情況下,都不會去回收匿名映射對應的active鍊錶中的頁面。 (而如果頁面已經被放到inactive鍊錶中,就不再去管那麼多了。)
反向映射
像這樣,在PFRA處理頁面回收的過程中,LRU的inactive鍊錶中的某些頁面可能就要被回收了。
如果頁面沒有被映射,直接回收到夥伴系統即可(對於髒頁,先寫回、再回收)。否則,還有一件麻煩的事情要處理。因為使用者進程的某個頁表項正引用著這個頁面呢,在回收頁面之前,還必須給引用它的頁表項一個交待。
於是,問題來了,內核怎麼知道這個頁面被哪些頁表項所引用呢?為了做到這一點,核心建立了從頁面到頁表項的反向映射。
透過反向映射可以找到一個被映射的頁面對應的vma,透過vma->vm_mm->pgd就能找到對應的頁表。然後透過page->index得到頁面的虛擬位址。再透過虛擬位址從頁表中找到對應的頁表項。 (前面說到的獲取頁表項中的accessed標記,就是透過反向映射實現的。)
頁面對應的page結構中,page->mapping如果最低位置位,則這是一個匿名映射頁面,page->mapping指向一個anon_vma結構;否則是檔案映射頁面,page->mapping檔案對應的address_space結構。 (顯然,anon_vma結構和address_space結構在分配時,位址必須要對齊,至少保證最低位元為0。)
對於匿名映射的頁面,anon_vma結構作為一個鍊錶頭,將映射這個頁面的所有vma透過vma->anon_vma_node鍊錶指標連接起來。每當一個頁面被(匿名)映射到一個使用者空間時,對應的vma就會被加入這個鍊錶。
對於檔案映射的頁面,address_space結構除了維護了一棵用於存放磁碟快取頁面的radix樹,還為該檔案映射到的所有vma維護了一棵優先搜尋樹。因為這些被文件映射到的vma並不一定都是映射整個文件,很可能只映射了文件的一部分。所以,這棵優先搜尋樹除了索引到所有被映射的vma,還要能知道檔案的哪些區域是映射到哪些vma上的。每當一個頁面被(檔案)映射到一個使用者空間時,對應的vma就會被加入這個優先搜尋樹。於是,給定磁碟快取上的一個頁面,就能透過page->index得到頁面在檔案中的位置,就能透過優先搜尋樹找出這個頁面對應到的所有vma。
上面兩步驟中,神奇的page->index做了兩件事,得到頁面的虛擬位址、得到頁面在檔案磁碟快取中的位置。
vma->vm_start記錄了vma的首虛擬位址,vma->vm_pgoff記錄了該vma在對應的映射檔案(或共享記憶體)中的偏移,而page->index則記錄了頁面在檔案(或共享記憶體)中的偏移。
透過vma->vm_pgoff和page->index能得到頁面在vma中的偏移,加上vma->vm_start就能得到頁面的虛擬位址;而透過page->index就能得到頁面在檔案磁碟快取中的位置。
頁面換入換出
#
在找到了引用待回收頁面的頁表項後,對於文件映射,可以直接把引用該頁面的頁表項清空。等用戶再造訪這個位址的時候觸發缺頁異常,異常處理程式碼再重新分配一個頁面,並去磁碟裡面把對應的資料讀出來就行了(說不定,頁面在對應的磁碟高速緩存裡面已經有了,因為其他進程先訪問過)。這就跟頁面映射以後,第一次被訪問的情形一樣;
對於匿名映射,先將頁面寫回交換文件,然後還得在頁表項中記錄該頁面在交換文件中的index。
頁表項中有一個present位,如果該位被清除,則mmu認為頁表項無效。在頁表項無效的情況下,其他位元不被mmu關心,可以用來儲存其他資訊。這裡就用它們來儲存頁面在交換文件中的index了(實際上是交換文件號碼 交換文件內的索引號)。
將匿名對應的頁面交換到交換檔案的過程(換出過程)與將磁碟快取中的髒頁寫回檔案的過程很相似。
交換檔案也有其對應的address_space結構,匿名對映的頁面在換出時先被放到這個address_space對應磁碟快取中,然後跟髒頁寫回一樣,被寫回交換檔。寫回完成後,這個頁面才被釋放(記住,我們的目的是要釋放這個頁面)。
那為什麼不直接把頁面寫回交換文件,而要經過磁碟快取呢?因為,這個頁面可能被映射了多次,不可能一次性把所有使用者程序的頁表中對應的頁表項都修改好(修改成頁面在交換文件中的索引),所以在頁面被釋放的過程中,頁面被暫時放在磁碟高速緩存上。
而並不是所有頁表項的修改過程都是能成功的(例如在修改之前頁面又被訪問了,於是現在又不需要回收這個頁面了),所以頁面放到磁碟高速緩存的時間也可能會很長。
同樣,將匿名對應的頁面從交換文件讀出的過程(換入過程)也與將文件資料讀出的過程很相似。
先去對應的磁碟高速緩存看看頁面在不在,不在的話再去交換文件裡面讀。文件裡的資料也是被讀到磁碟快取中的,然後使用者進程的頁表中對應的頁表項會被改寫,直接指向這個頁面。
這個頁面可能不會馬上從磁碟高速緩存中拿下來,因為如果還有其他用戶進程也映射到這個頁面(它們的對應頁表項已經被修改成了交換文件的索引),他們也可以引用到這裡。直到沒有其他的頁表項再引用這個交換文件索引時,頁面才可以從磁碟快取中被取下來。
最後的必殺
#
前面說到,PFRA可能掃描了所有的LRU還沒辦法回收所需的頁面。同樣,在slab、dentry cache、inode cache、等地方,也可能無法回收頁面。
這時,如果某段內核程式碼一定要取得頁面呢(沒有頁面,系統可能就要崩潰了)? PFRA只好讓出最後的必殺技-OOM(out of memory)。所謂的OOM就是尋找一個最不重要的進程,然後將其殺死。透過釋放這個進程所佔有的記憶體頁面,以緩解系統壓力。
5.記憶體管理架構
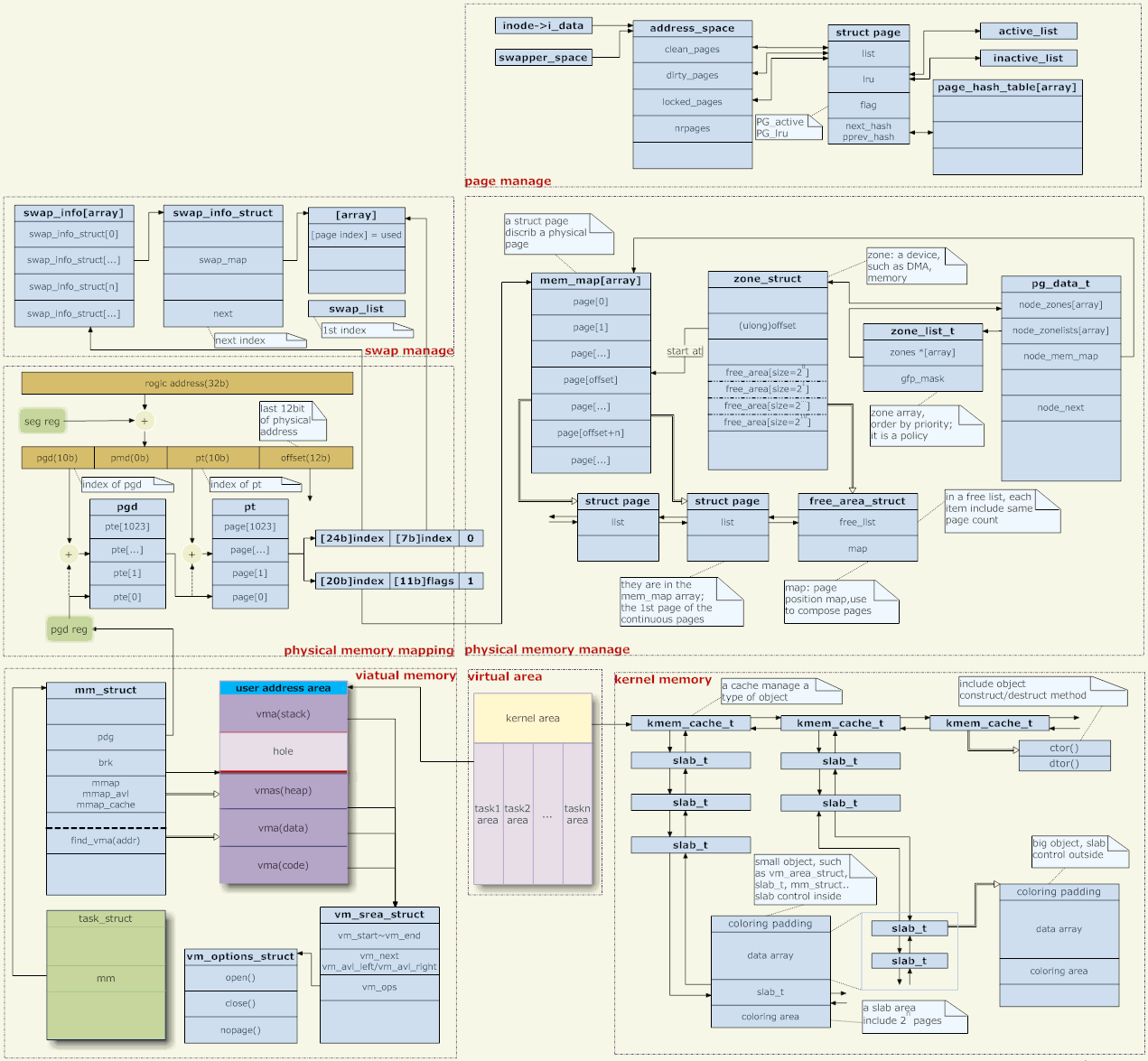
#針對上圖,說幾句,
位址映射
linux核心使用頁式記憶體管理,應用程式給出的記憶體位址是虛擬位址,它需要經過若干級頁表一級一級的變換,才變成真正的實體地址。
想一下,地址映射還是一件很恐怖的事情。當訪問一個由虛擬位址表示的記憶體空間時,需要先經過若干次的記憶體訪問,得到每一層頁表中用於轉換的頁表項(頁表是存放在記憶體裡面的),才能完成對應。也就是說,要實現一次記憶體訪問,實際上記憶體被訪問了N 1次(N=頁表級數),並且還需要做N次加法運算。
所以,位址映射必須要有硬體支持,mmu(記憶體管理單元)就是這個硬體。並且需要有cache來保存頁表,這個cache就是TLB(Translation lookaside buffer)。
儘管如此,地址映射還是有著不小的開銷。假設cache的訪問速度是記憶體的10倍,命中率是40%,頁表有三級,那麼平均一次虛擬位址存取大概就消耗了兩次實體記憶體存取的時間。
於是,一些嵌入式硬體上可能會放棄使用mmu,這樣的硬體能夠運行VxWorks(一個很高效的嵌入式即時作業系統)、linux(linux也有禁用mmu的編譯選項)、等系統。
但是使用mmu的優勢也是很大的,最主要的是出於安全性考量。各個流程都是相互獨立的虛擬位址空間,互不干擾。而放棄位址映射之後,所有程式將運行在同一個位址空間。於是,在沒有mmu的機器上,一個行程越界訪存,可能造成其他行程莫名其妙的錯誤,甚至導致核心崩潰。
在位址映射這個問題上,核心只提供頁表,實際的轉換是由硬體去完成的。那麼核心如何產生這些頁表呢?這就有兩方面的內容,虛擬位址空間的管理和實體記憶體的管理。 (實際上只有使用者態的位址對映才需要管理,核心態的位址對應是寫死的。)
虛擬位址管理
#
每個進程對應一個task結構,它指向一個mm結構,這就是該進程的記憶體管理器。 (對於線程來說,每個線程也都有一個task結構,但是它們都指向同一個mm,所以地址空間是共享的。)
mm->pgd指向容納頁表的內存,每個進程都有自已的mm,每個mm都有自己的頁表。於是,當進程調度時,頁表切換(一般會有一個CPU暫存器來保存頁表的位址,例如X86下的CR3,頁表切換就是改變該暫存器的值)。所以,各個進程的位址空間互不影響(因為頁表都不一樣了,當然無法存取到別人的位址空間上。但是共享記憶體除外,這是故意讓不同的頁表能夠存取到相同的實體位址上)。
使用者程式對記憶體的操作(分配、回收、映射、等)都是對mm的操作,具體來說是對mm上的vma(虛擬記憶體空間)的操作。這些vma代表著進程空間的各個區域,例如堆疊、堆疊、程式碼區、資料區、各種映射區、等等。
使用者程式對記憶體的操作並不會直接影響頁表,更不會直接影響實體記憶體的分配。例如malloc成功,只是改變了某個vma,頁表不會變,實體記憶體的分配也不會變。
假設用戶分配了內存,然後訪問這塊內存。由於頁表裡面並沒有記錄相關的映射,CPU產生一次缺頁異常。核心捕捉異常,檢查產生異常的位址是不是存在於一個合法的vma中。如果不是,則給進程一個”段錯誤”,讓其崩潰;如果是,則分配一個物理頁,並為之建立映射。
實體記憶體管理
#
那麼實體記憶體是如何分配的呢?
首先,linux支援NUMA(非均質儲存結構),而物理記憶體管理的第一個層次就是媒體的管理。 pg_data_t結構就描述了媒體。一般而言,我們的記憶體管理媒體只有內存,而且它是均勻的,所以可以簡單地認為系統中只有一個pg_data_t物件。
每一種介質下面有若干個zone。一般是三個,DMA、NORMAL和HIGH。
DMA:因為有些硬體系統的DMA匯流排比系統匯流排窄,所以只有一部分位址空間能夠用作DMA,這部分位址被管理在DMA區(這屬於高階貨了);
HIGH:高端記憶體。在32位元系統中,位址空間是4G,其中核心規定3~4G的範圍是核心空間,0~3G是用戶空間(每個用戶進程都有這麼大的虛擬空間)(圖:中下)。前面提到過核心的位址映射是寫死的,就是指這3~4G的對應的頁表是寫死的,它映射到了物理位址的0~1G。 (實際上沒有映射1G,只映射了896M。剩下的空間留下來映射大於1G的物理地址,而這一部分顯然不是寫死的)。所以,大於896M的實體位址是沒有寫死的頁表來對應的,核心不能直接存取它們(必須要建立映射),稱它們為高階記憶體(當然,如果機器記憶體不足896M,就不存在高階記憶體。如果是64位元機器,也不存在高階內存,因為位址空間很大很大,屬於核心的空間也不只1G了);
NORMAL:不屬於DMA或HIGH的記憶體就叫NORMAL。
在zone之上的zone_list代表了分配策略,即記憶體分配時的zone優先權。一種記憶體分配往往不是只能在一個zone裡進行分配的,例如分配一個頁給核心使用時,最優先是從NORMAL裡面分配,不行的話就分配DMA裡面的好了(HIGH就不行,因為還沒建立映射),這就是一種分配策略。
每個記憶體媒體維護了一個mem_map,為媒體中的每一個實體頁面建立了一個page結構與之對應,以便管理實體記憶體。
每個zone記錄它在mem_map上的起始位置。並且透過free_area串連著這個zone上空閒的page。實體記憶體的分配就是從這裡來的,從 free_area上把page摘下,就算是分配了。 (核心的記憶體分配與使用者進程不同,使用者使用記憶體會被核心監督,使用不當就」段錯誤」;而核心則無人監督,只能靠自覺,不是自己從free_area摘下的page就不要亂用。 )
[建立位址對映]
當核心需要實體記憶體時,很多情況是整頁分配的,這在上面的mem_map中摘一個page下來就好了。例如前面說到的內核捕捉缺頁異常,然後需要分配一個page來建立映射。
說到這裡,會有一個疑問,核心在分配page、建立位址映射的過程中,使用的是虛擬位址還是實體位址呢?首先,核心程式碼所存取的位址都是虛擬位址,因為CPU指令接收的就是虛擬位址(位址映射對於CPU指令是透明的)。但是,建立位址映射時,核心在頁表裡面填寫的內容卻是實體位址,因為位址映射的目標就是要得到實體位址。
那麼,核心怎麼得到這個物理位址呢?其實,上面也提到了,mem_map中的page就是根據實體記憶體來建立的,每一個page就對應了一個實體頁。
於是我們可以說,虛擬位址的映射是靠這裡page結構來完成的,是它們給了最終的實體位址。然而,page結構顯然是透過虛擬位址來管理的(前面已經說過,CPU指令接收的就是虛擬位址)。那麼,page結構實作了別人的虛擬位址映射,誰又來實作page結構自己的虛擬位址映射呢?沒人能夠實現。
這就引出了前面提到的問題,核心空間的頁表項是寫死的。在核心初始化時,核心的位址空間就已經把位址映射寫死了。 page結構顯然存在於核心空間,所以它的位址映射問題已經透過「寫死」解決了。
由於核心空間的頁表項是寫死的,又引出另一個問題,NORMAL(或DMA)區域的記憶體可能同時被映射到核心空間和使用者空間。被映射到內核空間是顯然的,因為這個映射已經寫死了。而這些頁面也可能被映射到使用者空間的,在前面提到的缺頁異常的場景裡面就有這樣的可能。映射到用戶空間的頁面應該優先從HIGH區域獲取,因為這些記憶體被核心訪問起來很不方便,拿給用戶空間再合適不過了。但是HIGH區域可能會耗盡,或者可能因為設備上實體記憶體不足導致系統裡面根本沒有HIGH區域,所以,將NORMAL區域映射給用戶空間是必然存在的。
但是NORMAL區域的記憶體被同時映射到內核空間和用戶空間並沒有問題,因為如果某個頁面正在被內核使用,對應的page應該已經從free_area被摘下,於是缺頁異常處理代碼中不會再將該頁映射到使用者空間。反過來也一樣,被映射到用戶空間的page自然已經從free_area被摘下,內核不會再去使用這個頁面。
核心空間管理
#
除了對記憶體整頁的使用,有些時候,核心也需要像使用者程式使用malloc一樣,分配一塊任意大小的空間。這個功能是由slab系統來實現的。
slab相當於為核心中常用的一些結構體物件建立了物件池,例如對應task結構的池、對應mm結構的池、等等。
而slab也維護有通用的物件池,例如」32位元組大小」的物件池、」64位元組大小”的物件池、等等。核心中常用的kmalloc函數(類似使用者態的malloc)就是在這些通用的物件池中實作分配的。
slab除了物件實際使用的記憶體空間外,還有其對應的控制結構。有兩種組織方式,如果物件較大,則控制結構使用專門的頁面來保存;如果物件較小,控制結構與物件空間使用相同的頁面。
除了slab,linux 2.6也引進了mempool(記憶體池)。其意圖是:某些物件我們不希望它會因為記憶體不足而分配失敗,於是我們預先分配若干個,放在mempool中存起來。正常情況下,分配物件時是不會去動mempool裡面的資源的,照常透過slab去分配。到系統記憶體緊缺,已經無法透過slab分配記憶體時,才會使用 mempool中的內容。
頁面換入換出(圖:右上)
頁面換入換出又是一個很複雜的系統。內存頁面被換出到磁碟,與磁碟檔案被映射到內存,是很相似的兩個過程(內存頁被換出到磁碟的動機,就是今後還要從磁碟將其載回內存)。所以swap復用了檔案子系統的一些機制。
頁面換入換出是一件很費CPU和IO的事情,但是由於記憶體昂貴這一歷史原因,我們只好拿磁碟來擴充記憶體。但現在內存越來越便宜了,我們可以輕鬆安裝數G的內存,然後將swap系統關閉。於是swap的實現實在讓人難有探索的慾望,在這裡就不贅述了。 (另見:《linux核心頁面回收淺析》)
[使用者空間記憶體管理]
malloc是libc的函式庫函數,使用者程式一般透過它(或類似函數)來分配記憶體空間。
libc對記憶體的分配有兩種途徑,一是調整堆的大小,二是mmap一個新的虛擬記憶體區域(堆也是一個vma)。
在內核中,堆是一個一端固定、一端可伸縮的vma(圖:左中)。可伸縮的一端透過系統呼叫brk來調整。 libc管理堆的空間,當使用者呼叫malloc分配記憶體時,libc盡量從現有的堆中去分配。如果堆空間不夠,則透過brk增加一個大堆空間。
當使用者將已指派的空間free時,libc可能會透過brk減少堆空間。但是堆空間增大容易減少卻難,考慮這樣一種情況,用戶空間連續分配了10塊內存,前9塊已經free。這時,未free的第10塊就算只有1位元組大,libc也不能夠去減少堆的大小。因為堆只有一端可伸縮,中間無法掏空。而第10塊記憶體就死死地佔據著堆可伸縮的那一端,堆的大小沒辦法減小,相關資源也沒辦法歸還內核。
當使用者malloc一塊很大的記憶體時,libc會透過mmap系統呼叫來映射一個新的vma。因為對於堆的大小調整和空間管理還是比較麻煩的,重新建一個vma會更方便(上面提到的free的問題也是原因之一)。
那為什麼不總是在malloc的時候去mmap一個新的vma呢?第一,對於小空間的分配與回收,被libc管理的堆空間已經能夠滿足需要,不必每次都去進行系統呼叫。而vma是以page為單位的,最小就是分配一個頁;第二,太多的vma會降低系統效能。缺頁異常、vma的新建與銷毀、堆空間的大小調整、等等情況下,都需要對vma進行操作,需要在當前進程的所有vma中找到需要被操作的那個(或那些)vma。 vma數目太多,必然導致性能下降。 (在進程的vma較少時,核心採用鍊錶來管理vma;vma較多時,改用紅黑樹來管理。)
[使用者的堆疊]
與堆一樣,棧也是一個vma(圖:左中),這個vma是一端固定、一端可伸(注意,不能縮)的。這個vma比較特殊,沒有類似brk的系統呼叫讓這個vma伸展,它是自動伸展的。
當使用者造訪的虛擬位址越過這個vma時,核心會在處理缺頁異常的時候將自動將這個vma增加。核心會檢查當時的堆疊暫存器(如:ESP),存取的虛擬位址不能超過ESP加n(n為CPU壓棧指令一次壓棧的最大位元組數)。也就是說,核心是以ESP為基準來檢查存取是否越界。
但是,ESP的值是可以由使用者態程式自由讀寫的,使用者程式如果調整ESP,將棧劃得很大很大怎麼辦呢?核心中有一套關於進程限制的配置,其中有棧大小的配置,棧只能這麼大,再大就出錯。
對於一個行程來說,棧一般是可以被伸展得比較大(如:8MB)。然而對於線呢?
首先線程的棧是怎麼回事?前面說過,線程的mm是共享其父進程的。雖然棧是mm中的vma,但是執行緒不能與其父行程共用這個vma(兩個運行實體顯然不用共用一個棧)。於是,當執行緒建立時,執行緒函式庫透過mmap新建了一個vma,以此作為執行緒的堆疊(大於一般為:2M)。
可見,執行緒的堆疊在某種意義上並不是真正棧,它是一個固定的區域,而且容量很有限。
透過本文,你應該對Linux記憶體管理有了基本的了解,它是一種實現虛擬記憶體和實體記憶體的轉換和分配的有效方式,可以適應Linux系統的多樣化需求。當然,記憶體管理也不是一成不變的,它需要根據特定的硬體平台和核心版本進行客製化和修改。總之,記憶體管理是Linux系統中不可或缺的一個元件,值得你深入學習與掌握。
以上是Linux記憶體管理:如何實現虛擬記憶體和實體記憶體的轉換和分配的詳細內容。更多資訊請關注PHP中文網其他相關文章!