
用範例示範如何理解二進位類別的混淆矩陣

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2024-01-22 14:30:22938瀏覽
混淆矩陣是一種評估模式,幫助機器學習工程師更了解模型效能。本文以一個二元類不平衡資料集為例,測試集由60個正類樣本和40個負類樣本組成,用於評估機器學習模型。
二元類別資料集僅有兩個不同類別的數據,可簡單命名為「正面」和「負面」類別。
現在,要完全理解這個二分類問題的混淆矩陣,我們首先需要熟悉以下術語:
True Positive(TP)是指屬於正類的樣本被正確分類。
True Negative(TN)是指屬於負類別的樣本被正確分類。
False Positive(FP)是指屬於陰性類別的樣本被錯誤地分類為屬於陽性類別。
False Negative(FN)是指屬於正類別的樣本被錯誤地歸類為負類別。
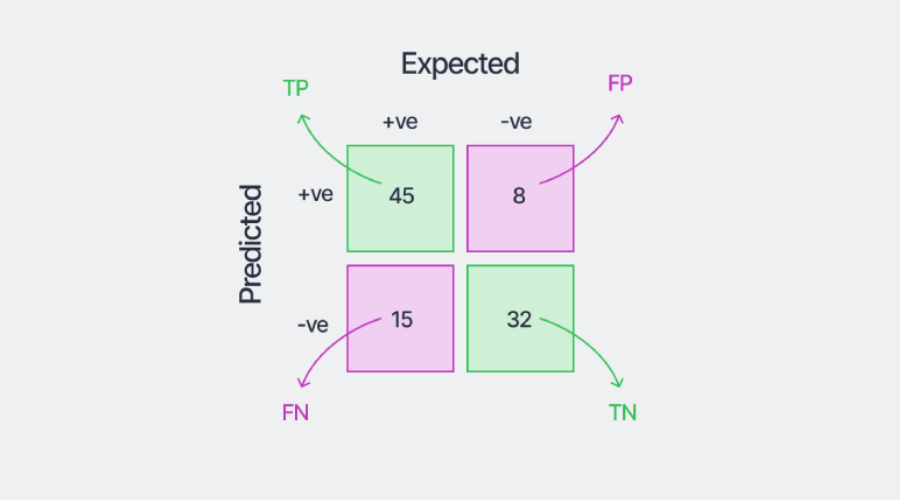
我們可以透過訓練模型獲得的混淆矩陣範例如上所示,用於此範例資料集。
將第一列中的數字相加,我們看到正類別中的樣本總數為45 15=60。將第二列的數字相加得到負類中的樣本數,在本例中為40。所有方框中的數字總和給出了評估的樣本總數。此外,正確的分類是矩陣的對角線元素-正類45個,負類32個。
現在,模型將左下角的框歸類為正類樣本,所以它被稱為"FN",因為模型預測的"陰性"是錯誤的。同理,右上框預計屬於負類,但被模型分類為"正"。因此,它們被稱為“FP”。我們可以使用矩陣中的這四個不同數字來更仔細地評估模型。
以上是用範例示範如何理解二進位類別的混淆矩陣的詳細內容。更多資訊請關注PHP中文網其他相關文章!
陳述:
本文轉載於:163.com。如有侵權,請聯絡admin@php.cn刪除