Lightning Attention-2 是一種新型的線性注意力機制,讓長序列的訓練和推理成本與 1K 序列長度的一致。
大語言模型序列長度的限制,大大製約了其在人工智慧領域的應用,例如多輪對話、長文本理解、多模態資料的處理與生成等。造成這項限制的根本原因在於目前大語言模型均採用的 Transformer 架構有著相對於序列長度的二次計算複雜度。這意味著隨著序列長度的增加,所需的計算資源成幾何倍數提升。如何有效率地處理長序列一直是大語言模型的挑戰之一。 之前的方法往往集中在如何讓大語言模型在推理階段適應更長的序列。例如採用Alibi 或類似的相對位置編碼的方式來讓模型自適應不同的輸入序列長度,亦或採用對RoPE 等類似的相對位置編碼進行差值的方式,在已經完成訓練的模型上再進行進一步的短暫精調來達到擴增序列長度的目的。這些方法只是讓大模型具有了一定的長序列建模能力,但實際訓練和推理的開銷並沒有減少。 OpenNLPLab 團隊嘗試一勞永逸地解決大語言模型長序列問題。他們提出並開源了 Lightning Attention-2—— 一種新型的線性注意力機制,讓長序列的訓練和推理成本與 1K 序列長度的一致。在遇到顯存瓶頸之前,無限地增加序列長度並不會對於模型訓練速度產生負面影響。這讓無限長度預訓練成為了可能。同時,超長文本的推理成本也與 1K Tokens 的成本一致甚至更少,這將大大減少當前大語言模型的推理成本。如下圖所示,在 400M、1B、3B 的模型大小下,隨著序列長度的增加,FlashAttention2 加持的 LLaMA 的訓練速度開始快速下降,然而 Lightning Attention-2 加持的 TansNormerLLM 的速度幾無變化。  圖 1
圖 1
#
- 論文:Lightning Attention-2: A Free Lunch for Handling Unlimited Sequence Lengths in Large Language Models
- 論文地址:https://arxiv.org /pdf/2401.04658.pdf
- 開源位址:https://github.com/OpenNLPLab/lightning-attention
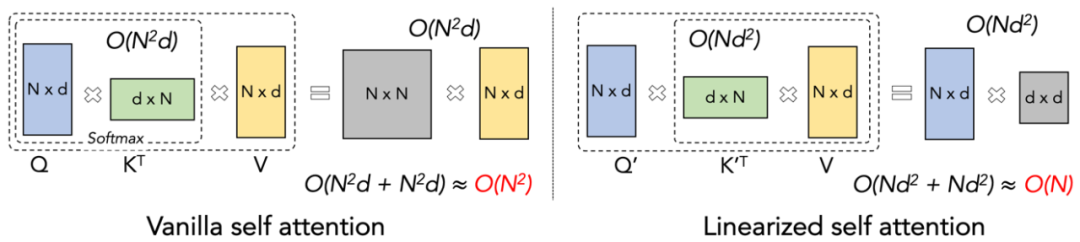
#Lightning Attention-2 簡介#讓大模型的預訓練速度在不同序列長度下保持一致,這聽起來是一個不可能的任務。事實上,如果一個注意力機制的計算複雜度相對於序列長度保持線性關係的話,就可以實現這一點。自 2020 年線性注意力【https://arxiv.org/abs/2006.16236】橫空出世以來,研究人員一直在為了線性注意力的實際效率符合它的理論線性計算複雜度而努力。在 2023 年之前,大多數的關於線性注意力的工作均集中在對齊它們與 Transformer 的精確度上。終於在 2023 年中期,改進的線性注意力機制【https://arxiv.org/abs/2307.14995】在精度上可以與最先進的 Transformer 架構對齊。然而,線性注意力中將計算複雜度變成線性的最關鍵的 “左乘變右乘” 的計算 Trick (如下圖所示),在實際實現中遠慢於直接左乘的演算法。原因在於右乘的實作需要用到包含大量循環操作的累積求和(cumsum),大量的 IO 操作使得右乘的效率遠低於左乘。 #為了更好的理解Lightning Attention-2 的思路,讓我們先回顧下傳統softmax attention 的計算公式:O=softmax ((QK^T)⊙M_) V,其中Q, K, V, M, O 分別為query, key, value, mask 和輸出矩陣,這裡的M 在單向任務(如GPT)中是一個下三角的全1 矩陣,在雙向任務(如Bert)中則可以忽略,即雙向任務沒有mask 矩陣。 作者將Lightning Attention-2 的整體想法總結為以下三點進行解釋:##1. Linear Attention 的核心想法之一就是移除了計算成本高昂的softmax 算子,讓Attention 的計算公式可以寫成O=((QK^T)⊙M_) V。但由於單向任務中 mask 矩陣 M 的存在,使得該形式依然只能進行左乘計算,因此無法獲得 O (N) 的複雜度。但對於雙向任務,由於沒有沒有 mask 矩陣,Linear Attention 的計算公式可以進一步簡化為 O=(QK^T) V。 Linear Attention 的精妙之處在於,僅僅利用簡單的矩陣乘法結合律,其計算公式就可以進一步轉化為:O=Q (K^T V),這種計算形式被稱為右乘,相對應的前者為左乘。透過圖 2 可以直觀地理解到 Linear Attention 在雙向任務中可以達到誘人的 O (N) 複雜度!
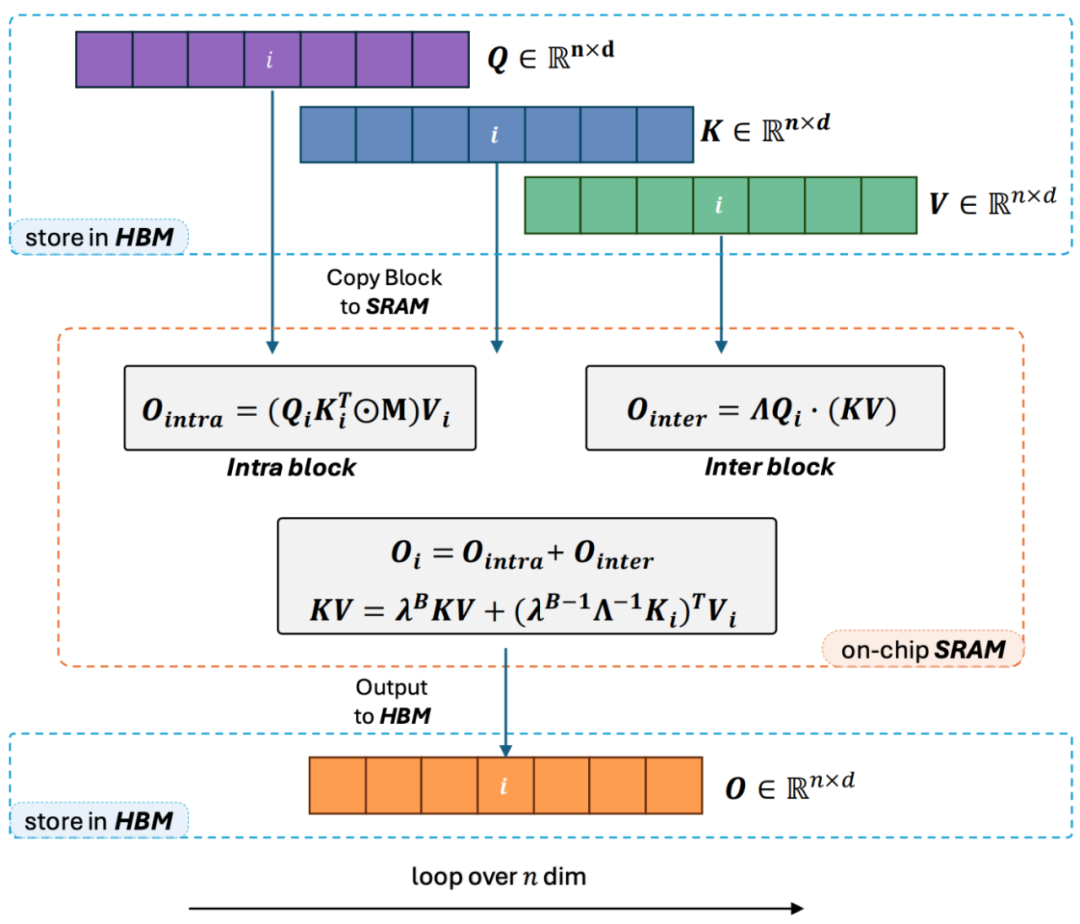
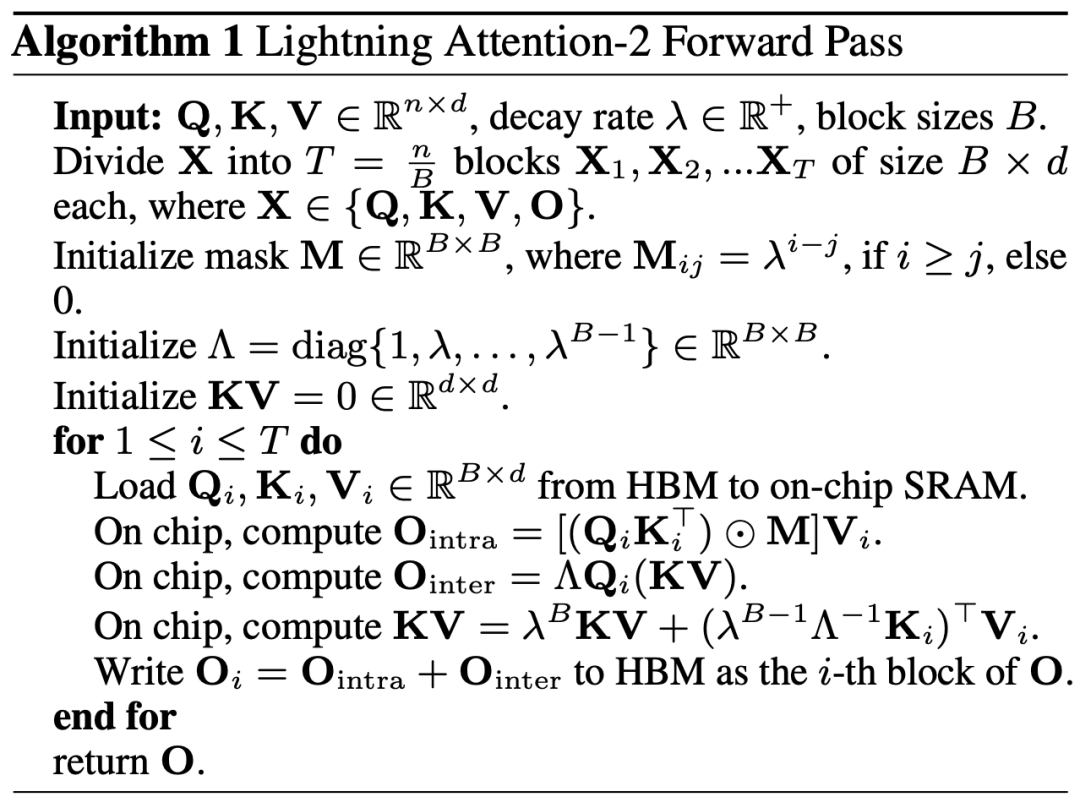
2. 但隨著decoder-only 的GPT 形式的模型逐漸成為LLM 的事實標準,如何利用Linear Attention 的右乘特性加速單向任務成為了亟待解決的難題。為了解決這個問題,本文作者提出了利用 「分而治之」 的思想,將注意力矩陣的計算分為對角陣和非對角陣兩種形式,並採用不同的方式對他們進行計算。如圖 3 所示,Linear Attention-2 利用電腦領域常用的 Tiling 思想,將 Q, K, V 矩陣分別切分為了相同數量的區塊 (blocks)。其中block 自身(intra-block)的計算由於mask 矩陣的存在,依然保留左乘計算的方式,具有O (N^2) 的複雜度;而block 之間(inter-block)的計算由於沒有mask 矩陣的存在,可以採用右乘計算方式,從而享受到O (N) 的複雜度。兩者分別計算完成後,可以直接相加得到對應第 i 塊的 Linear Attention 輸出 Oi。同時,透過 cumsum 對 KV 的狀態進行累積以在下一個 block 的計算中使用。這樣就得到了整個 Lightning Attention-2 的演算法複雜度為 intra-block 的 O (N^2) 和 inter-block 的 O (N) 的 Trade-off。怎麼取得更好的 Trade-off 則是由 Tiling 的 block size 決定的。
3. 細心的讀者會發現,以上的過程只是Lightning Attention-2 的演算法部分,之所以取名Lightning 是因為作者充分考慮了這個演算法過程在GPU 硬體執行過程中的效率問題。受到FlashAttention 系列工作的啟發,實際在GPU 上進行計算的時候,作者將切分後的Q_i, K_i, V_i 張量從GPU 內部速度更慢容量更大的HBM 搬運到速度更快容量更小的SRAM上進行計算,從而減少大量的memory IO 開銷。當該 block 完成 Linear Attention 的計算之後,其輸出結果 O_i 又會被搬回至 HBM。重複這個過程直到所有 block 處理完畢即可。
想要了解更多細節的讀者可以仔細閱讀本文中的 Algorithm 1 和 Algorithm 2,以及論文中的詳細推導過程。 Algorithm 以及推導過程都對 Lightning Attention-2 的前向和反向過程進行了區分,可以幫助讀者有更深入的理解。
圖3
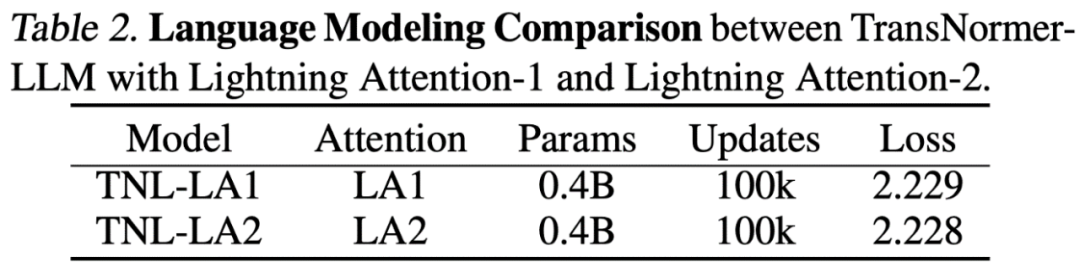
# Lightning Attention-2 精確度對比研究人員首先在小規模(400M)參數模型上對比了Lightning Attention-2 與Lightning Attention-1 的精確度區別,如下圖所示,二者幾無差別。
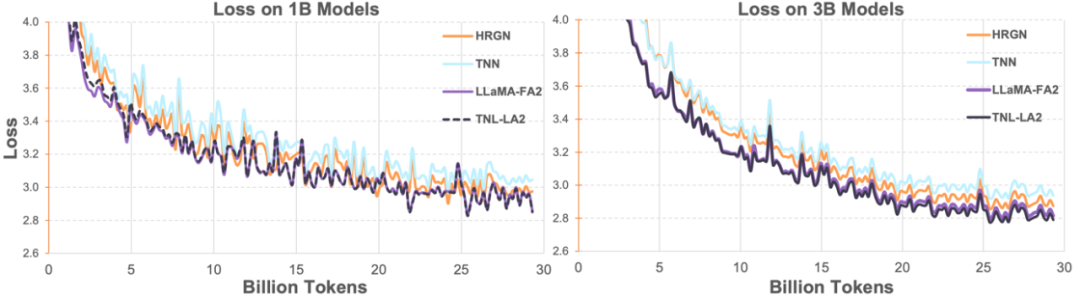
隨後研究人員在1B、3B 上將Lightning Attention-2 加持的TransNormerLLM(TNL-LA2)與其它先進的非Transformer 架構的網路以及FlashAttention2 加持的LLaMA在相同的語料下做了比較。如下圖所示,TNL-LA2 與 LLaMA 保持了相似的趨勢,且 loss 的表現更優。這個實驗表明,Lightning Attention-2 在語言建模方面有著不遜於最先進的 Transformer 架構的精度表現。
在大語言模型任務中,研究人員比較了 TNL-LA2 15B 與 Pythia 在類似大小下的大模型常見 Benchmark 的結果。如下表所示,在吃掉了相同 tokens 的條件下,TNL-LA2 在常識推理和多項選擇綜合能力上均略高於基於 Softmax 的注意力的 Pythia 模型。
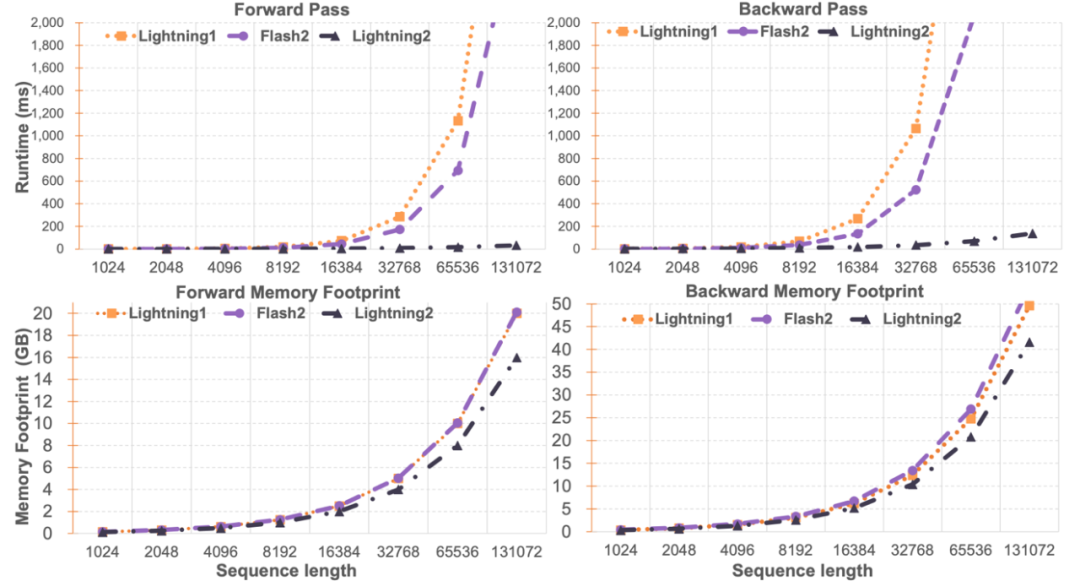
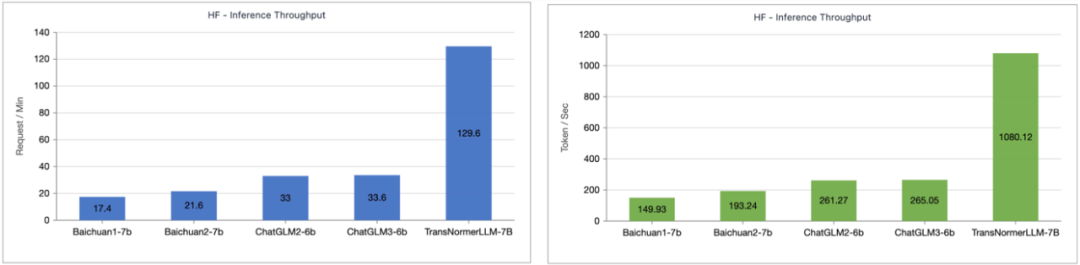
Lightning Attention-2 速度比較研究者對Lightning Attention-2 與FlashAttention2 進行了單模組速度與顯存佔用比較。如下圖所示,相較於 Lightning Attention-1 和 FlashAttention2,在速度上,Lightning Attention-2 表現出了相比於序列長度的嚴格線性增長。在顯存佔用上,三者都顯示了類似的趨勢,但 Lightning Attention-2 的顯存佔用更小。這個的原因是 FlashAttention2 和 Lightning Attention-1 的顯存佔用也是近似線性的。 筆者註意到,這篇文章主要關注點在解決線性注意力網路的訓練速度上,並實現了任意長度的長序列與1K 序列相似的訓練速度。在推理速度上,並沒有過多的介紹。這是因為線性注意力在推理的時候可以無損地轉化為 RNN 模式,從而達到類似的效果,即推理單 token 的速度恆定。對於 Transformer 來說,目前 token 的推理速度與它之前的 token 數量相關。 筆者測試了 Lightning Attention-1 加持的 TransNormerLLM-7B 與常見的 7B 模型在推理速度上的比較。如下圖所示,在近似參數大小下,Lightning Attention-1 的吞吐速度是百川的 4 倍,ChatGLM 的 3.5 倍以上,顯示出了優異的推理速度優勢。
Lightning Attention-2 代表了線性注意力機制的重大進步,使其無論在精度或速度上均可以完美的替換傳統的Softmax 注意力,為今後越來越大的模型提供了可持續擴展的能力,並提供了一條以更高效率處理無限長序列的途徑。 OpenNLPLab 團隊在未來將研究基於線性注意力機制的序列平行演算法,以解決目前遇到的顯存屏障問題。 以上是Lightning Attention-2:實現無限序列長度、恆定算力成本和更高建模精度的新一代注意力機制的詳細內容。更多資訊請關注PHP中文網其他相關文章!


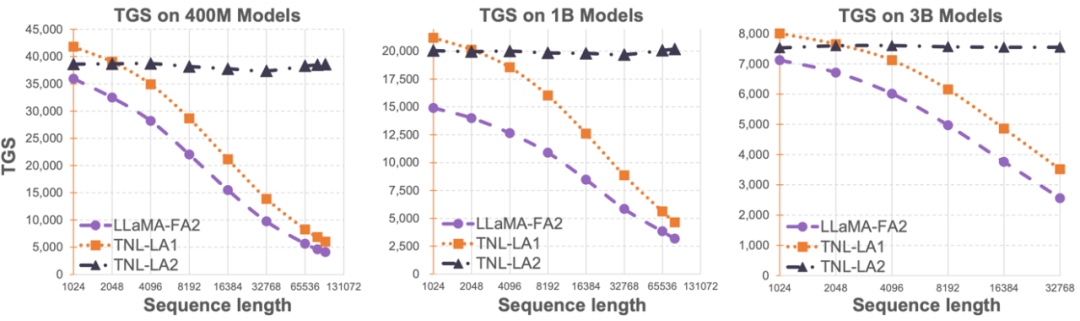 圖 1
圖 1