
OpenAI加強安全團隊,授予其權力以否決危險人工智慧

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-12-19 17:30:411385瀏覽
生產中的模型由「安全系統」團隊管理。開發中的前沿模型有「準備」團隊,該團隊會在模型發布之前識別和量化風險。然後是「超級對齊」團隊,他們正在研究「超級智慧」模型的理論指南
將安全顧問小組重新組建,使其位於技術團隊之上,以便向領導層提出建議,並給予董事會否決的權力
OpenAI宣布,為了抵禦有害人工智慧的威脅,他們正在加強內部的安全流程。他們將設立一個名為「安全顧問小組」的新部門,該部門將位於技術團隊之上,向領導層提供建議,並被授予董事會否決權。這項決定於當地時間12月18日宣布
更新引起關注的原因主要是因為OpenAI執行長山姆·奧特曼被董事會解僱,而這似乎與大型模型的安全問題有關。在高層人事變動後,OpenAI董事會的兩位「減速主義」成員伊爾亞·蘇茨克維和海倫·托納失去了董事會席位
在這篇文章中,OpenAI討論了他們最新的“準備框架”,即OpenAI如何追蹤、評估、預測和防範日益強大的模型所帶來的災難性風險。災難性風險的定義是什麼? OpenAI解釋道,「我們所說的災難性風險是指可能導致數千億美元經濟損失,或導致許多人嚴重傷害或死亡的風險,這也包括但不限於生存風險。」
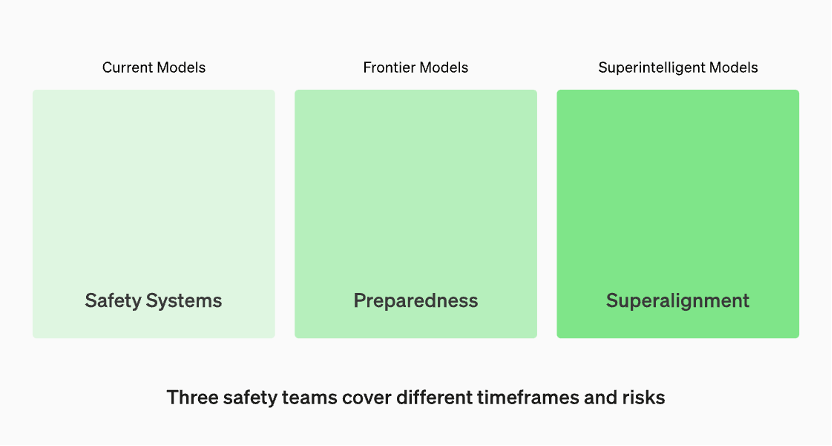
有三組安全團隊分別涵蓋不同的時間框架和風險
根據OpenAI官網的資料,生產中的模型由「安全系統」團隊負責管理。而在開發階段,有一個名為「準備」的團隊,他們會在模型發布之前識別和評估風險。此外,還有一個名為「超級對齊」(superalignment)的團隊,他們正在研究「超級智慧」(superintelligent)模型的理論指南
OpenAI團隊將對每個模型根據四個風險類別進行評級,這四個類別分別是網路安全、說服能力(如虛假資訊)、模型自主性(即自主行為能力)以及CBRN(化學、生物、放射性和核威脅,例如創造新病原體的能力)
OpenAI在假設中考慮了各種緩解措施:例如,該模型對於描述製作凝固汽油或管式炸彈的過程保持著合理的保留態度。在考慮已知的緩解措施後,如果一個模型仍然被評估為具有「高」風險,它將無法被部署,如果一個模型存在任何「關鍵」風險,將不會進一步開發
並非所有製作模型的人都是評估模型和提出建議的最佳人選。出於這個原因,OpenAI正在建立一個名為「跨職能安全諮詢小組」的團隊,該團隊將從技術層面審查研究人員的報告,並從更高的角度提出建議,希望能夠發現一些「未知的未知”
這個過程要求將這些建議同時發送給董事會和領導層,領導層將決定是否繼續或停止運行,但董事會有權撤銷這些決定。這樣可以避免高風險產品或流程在董事會不知情的情況下獲得批准
然而,外界仍然擔心的是,如果專家小組提出建議,執行長根據這些資訊做出決策,OpenAI的董事會是否真的有權利進行反駁並採取行動?如果他們這樣做了,公眾會聽到相關聲音嗎?目前,除了OpenAI承諾徵求獨立第三方審計之外,他們的透明度問題實際上並沒有得到真正的解決
OpenAI的「準備框架」包含以下五個關鍵要素:
1. 評估與評分
我們將對我們的模型進行評估,並持續更新我們的「記分卡」。我們將評估所有最新的模型,包括在訓練期間將有效計算量增加兩倍。我們將推動模型的極限。這些發現將有助於我們評估最新模型的風險,並衡量任何建議的緩解措施的有效性。我們的目標是探測特定邊緣的不安全因素,以有效減輕風險。為了追蹤我們模型的安全水平,我們將製作風險「記分卡」和詳細報告
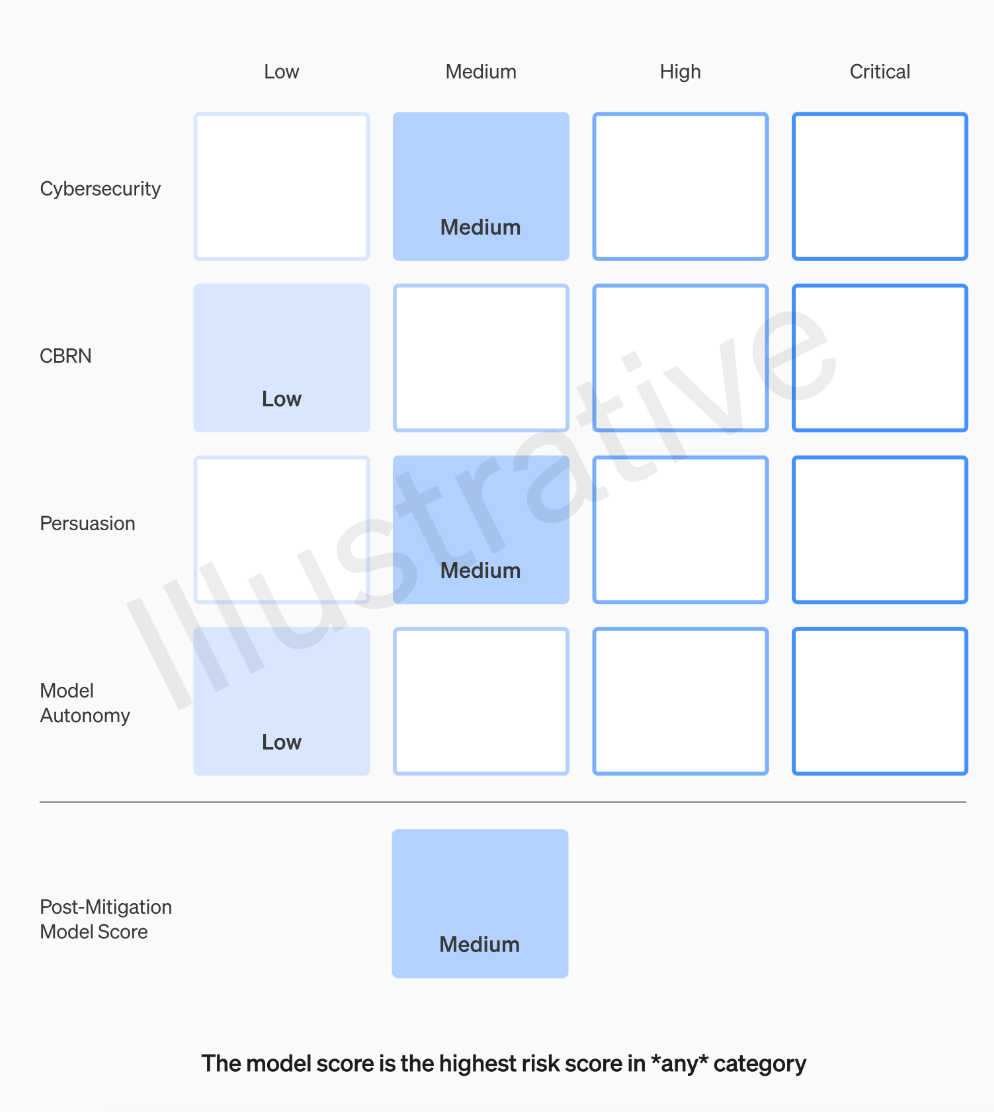
要評估所有前沿模型,需要使用「記分卡」
設定風險閾值的目的是為了在進行決策和管理風險時能夠有一個明確的界限。風險閾值是指在特定情況下,組織或個人願意承受的最大風險水準。透過設定風險閾值,可以幫助組織或個人識別何時需要採取行動來減輕風險或避免風險。風險閾值的設定應基於風險評估的結果、相關法規和政策以及組織或個人的風險承受能力。在設定風險閾值時,需要考慮不同風險類型的特性和影響程度,以確保風險管理措施的有效性和適用性。最後,設定的風險門檻應定期進行評估和調整,以保持與組織或個人的風險管理目標一致
我們將設定觸發安全措施的風險閾值。我們根據以下初步追蹤類別設定了風險等級的閾值:網路安全、CBRN(化學、生物、放射性、核威脅)、說服和模型自主。我們指定了四個安全風險級別,只有緩解後得分為「中」或以下的模型才能部署;只有緩解後得分為「高」或以下的模型才能進一步開發。對於具有高風險或嚴重風險(緩解前)的模型,我們也將實施額外的安全措施

危險水平
重新設定監督技術工作與安全決策營運架構
我們將設立一個專門的團隊來監督技術工作和安全決策的營運結構。準備團隊將推動技術工作,以檢查前沿模型的能力極限,並進行評估和綜合報告。這項技術工作對於OpenAI安全模型的開發和部署決策至關重要。我們正在創建一個跨職能的安全諮詢小組,以審查所有報告,並同時發送給領導層和董事會。儘管領導階層是決策者,但董事會擁有推翻決定的權力
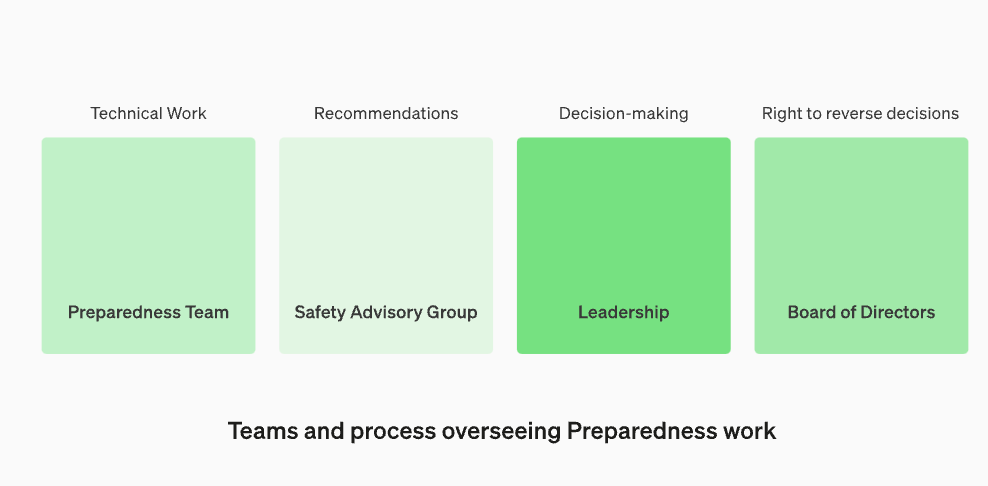
監督技術工作和安全決策營運結構的新變化
增強安全性和加強對外部問責
#我們將制定協議以提高安全性和外部責任。我們將定期進行安全演習,以壓力測試我們的業務和自身文化。一些安全問題可能會迅速出現,因此我們有能力標記緊急問題以進行快速回應。我們認為,從OpenAI外部人員那裡獲得回饋並由合格的獨立第三方進行審核是很有幫助的。我們將繼續讓其他人組成紅隊並評估我們的模型,並計劃與外部共享更新
減少其他已知和未知的安全風險:
我們將協助減少其他已知和未知的安全風險。我們將與外部各方以及內部的安全系統等團隊密切合作,以追蹤現實世界中的濫用。我們還將與「超級對齊」合作,追蹤緊急的錯位風險。我們也開創了新的研究,以衡量風險隨著模型規模擴展而演變的情況,並幫助提前預測風險,這類似於我們早期在規模法則方面的成功。最後,我們將進行連續的流程,以嘗試解決任何新出現的「未知的未知」
以上是OpenAI加強安全團隊,授予其權力以否決危險人工智慧的詳細內容。更多資訊請關注PHP中文網其他相關文章!