
系統研究揭示下一代自動駕駛系統的不可或缺的大模型

- PHPz轉載
- 2023-12-16 14:21:181558瀏覽
隨著大語言模型(LLM)和視覺基礎模型(VFM)的出現,有望透過大模型的多模態人工智慧系統實現像人類一樣全面感知現實世界和做出決策。近幾個月來,LLM在自動駕駛研究領域引起了廣泛關注。儘管LLM具有巨大潛力,但在駕駛系統中仍存在關鍵挑戰、機會和未來研究方向,這些方面目前缺乏詳細的闡明
在本文中,騰訊地圖、普渡大學、UIUC、維吉尼亞大學的研究人員對這個領域進行了系統性研究。研究首先介紹了多模態大型語言模型 (MLLM) 的背景,使用 LLM 開發多模態模型的進展,以及對自動駕駛的歷史進行回顧。然後,該研究概述了用於駕駛、交通和地圖系統的現有 MLLM 工具,以及現有的資料集。該研究還總結了第一屆 WACV 大語言和視覺模型自動駕駛研討會 (LLVM-AD) 的相關工作,這是應用 LLM 在自動駕駛領域的首個研討會。為了進一步推動這一領域的發展,該研究還討論了關於如何在自動駕駛系統中應用 MLLM,以及需要由學術界和工業界共同解決的一些重要問題。

- #綜述連結:https://arxiv.org/abs/2311.12320
- 研討會連結:https://llvm-ad.github.io/
- Github 連結:https://github.com/IrohXu/ Awesome-Multimodal-LLM-Autonomous-Driving
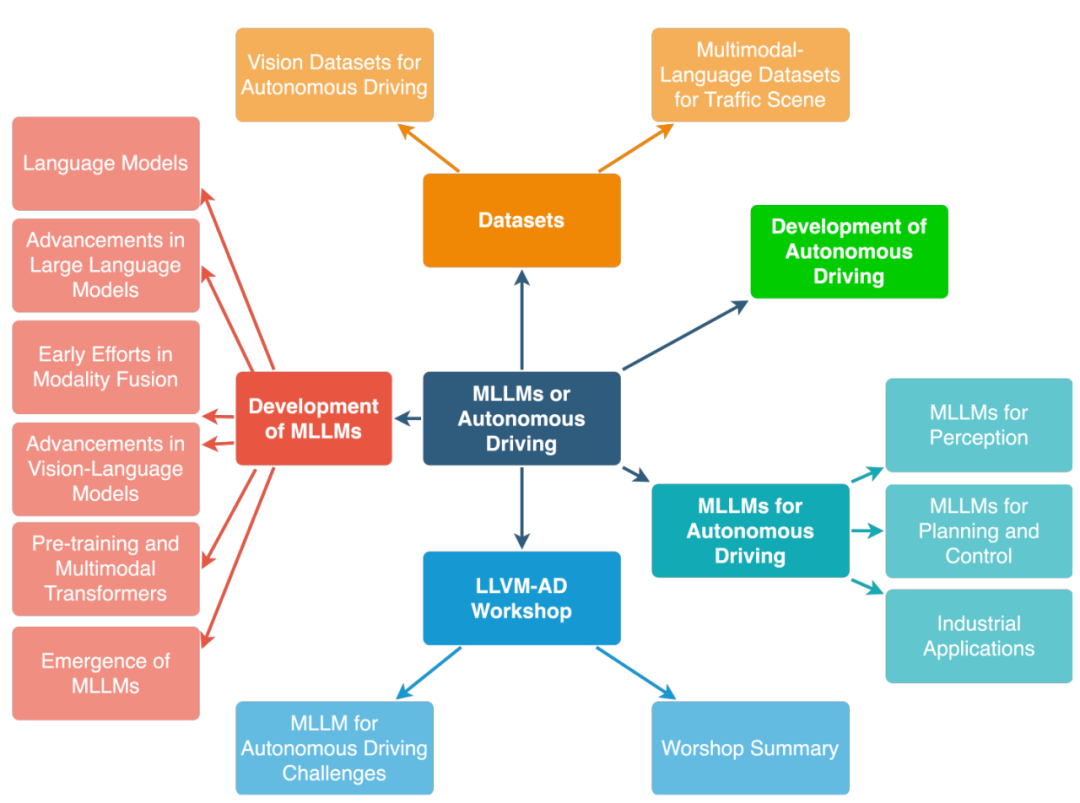
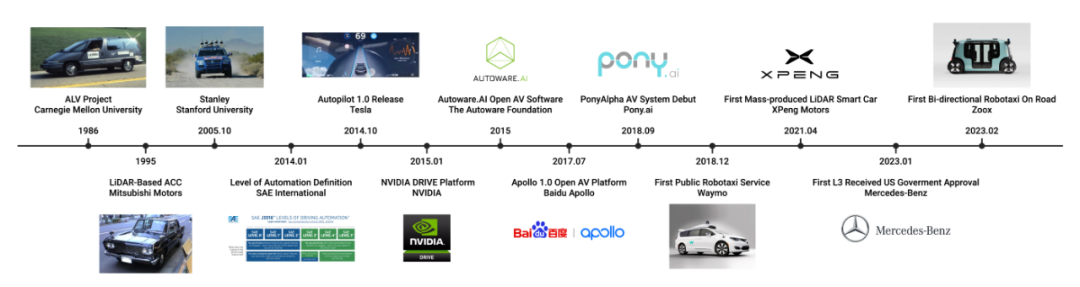
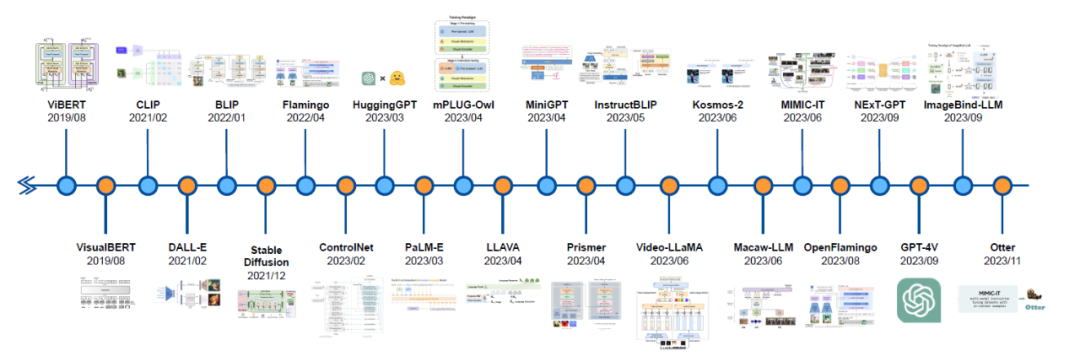
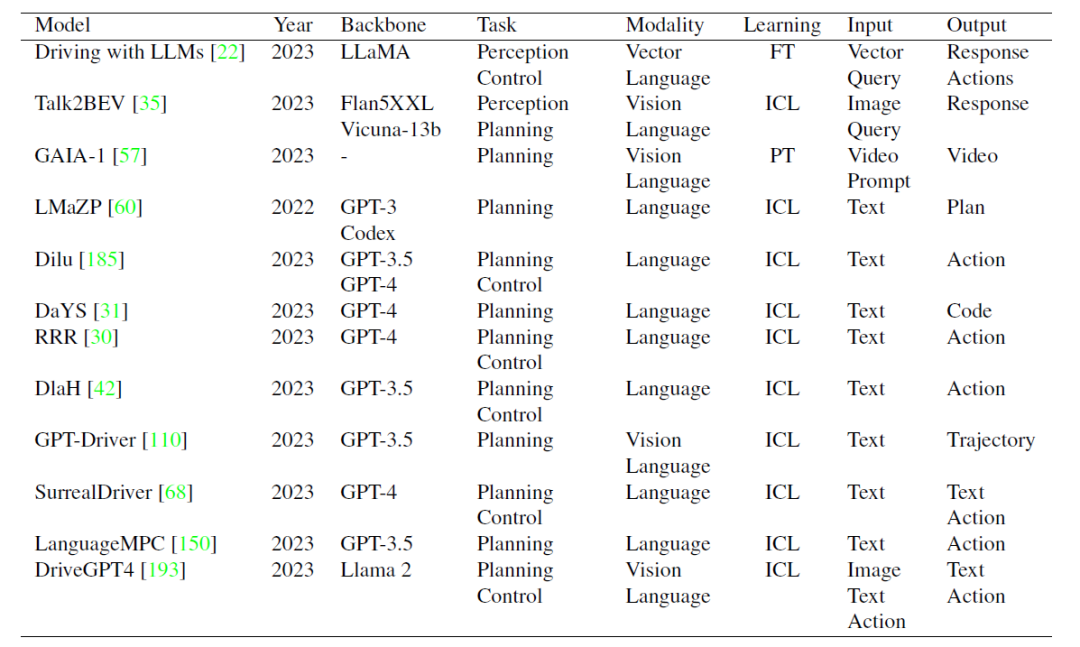
######################## ###近期多模態大語言模型(MLLM)備受關注,該模型將LLM的推理能力與圖像、視訊和音訊資料相結合,透過多模態對齊使得這些資料能夠更有效率地執行各種任務,包括圖像分類、將文字與相應的視訊對齊以及語音檢測。此外,一些研究顯示LLM可以處理機器人領域的簡單任務,但是,目前在自動駕駛領域中,MLLM的整合進展緩慢,是否有潛力改良現有的自動駕駛系統,例如像GPT-4、PaLM-2和LLaMA-2這樣的LLM,仍需進一步研究探索############研究人員在本綜述中認為,將LLM整合到自動駕駛領域可以帶來顯著的範式轉變,從而在駕駛感知、運動規劃、人車互動和運動控制方面為使用者提供更適應性、更可信的未來交通方案。在感知方面,LLM可以利用工具學習(Tool Learning)調用外部API存取即時資訊來源,如高精度地圖、交通報告和天氣資訊,使車輛更全面地理解周圍環境。自動駕駛汽車可以透過LLM推理擁塞路線並建議替代路徑以提高效率和安全駕駛。在運動規劃和人車互動方面,LLM可以促進以使用者為中心的溝通,使乘客能夠用日常語言表達他們的需求和偏好。在運動控制方面,LLM首先使控制參數可以根據駕駛者的偏好進行定制,實現了駕駛體驗的個人化。此外,LLM還可以透過解釋運動控制過程的每個步驟來提供對使用者的透明度。該綜述預計,在未來的SAE L4-L5級別的自動駕駛車輛中,乘客可以使用語言、手勢甚至眼神來傳達他們的請求,由MLLM透過整合視覺顯示或語音回應來提供即時的車內和駕駛回饋##################################自動駕駛與多模態大語言模型的發展歷程##### ######################### 自動駕駛MLLM 的研究總結:目前模型的LLM 框架主要有LLaMA、Llama 2、GPT-3.5、GPT- 4、Flan5XXL、Vicuna-13b。 FT、ICL 和 PT 在本表中指的是微調、情境學習和預訓練。文獻連結可以參考 github repo: https://github.com/IrohXu/Awesome-Multimodal-LLM-Autonomous-Driving######
為了建構自動駕駛和LLVM之間的橋樑,相關研究人員在2024年IEEE/CVF冬季電腦視覺應用會議(WACV)上組織了首屆大語言和視覺模型自動駕駛研討會(LLVM- AD)。該研討會旨在增強學術研究人員和行業專業人士之間的合作,探討在自動駕駛領域實施多模態大型語言模型的可能性和挑戰。 LLVM-AD將進一步推動後續的開源實際交通語言理解資料集的發展
第一屆WACV大型語言和視覺模型自動駕駛研討會(LLVM-AD)共接受了九篇論文。其中一些論文圍繞著自動駕駛中的多模態大語言模型展開,重點關注將LLM整合到使用者-車輛互動、運動規劃和車輛控制中。還有幾篇論文探討了LLM在自動駕駛車輛中類人互動和決策的新應用。例如,「模仿人類駕駛」和「按語言駕駛」探討了LLM在複雜駕駛場景中的解釋和推理,以及模仿人類行為的框架。另外,「以人為中心的自主系統與LLM」強調了將使用者置於設計LLM的中心地位,利用LLM來解釋使用者指令。這種方法代表了朝向以人為中心的自主系統的重要轉變。除了融合LLM,研討會還涵蓋了一些基於純視覺和資料處理的方法。此外,研討會也提出了創新的數據處理和評估方法。例如,NuScenes-MQA介紹了一種新的自動駕駛資料集註釋方案。總的來說,這些論文展示了將語言模型和先進技術整合到自動駕駛中的進展,為更直觀、高效和以人為中心的自動駕駛車輛鋪平了道路
#為了未來的發展,本研究提出了以下幾個研究方向:
#需要被重寫的內容是:1、自動駕駛中多模態大語言模型的新資料集
儘管大語言模型在語言理解方面取得了成功,但將其應用於自動駕駛仍面臨挑戰。這是因為這些模型需要整合和理解來自不同模態的輸入,如全景影像、三維點雲和高精地圖。目前的數據規模和品質的限制意味著現有數據集難以全面應對這些挑戰。此外,從 NuScenes 等早期開源資料集註釋的視覺語言資料集可能無法為駕駛場景中的視覺語言理解提供穩健的基準。因此,迫切需要新的、大規模的資料集,涵蓋廣泛的交通和駕駛場景,彌補先前資料集分佈的長尾(不均衡)問題,以有效地測試和增強這些模型在自動駕駛應用中的性能。
2、自動駕駛中大型語言模型所需的硬體支援
不同的功能對硬體的需求各不相同。在車輛內部使用 LLM 進行駕駛規劃或參與車輛控制需要即時處理和低延遲以確保安全,這增加了運算需求並影響功耗。如果 LLM 部署在雲端,資料交換的頻寬將成為另一個關鍵的安全因素。相較之下,將 LLM 用於導航規劃或分析與駕駛無關的命令(如車載音樂播放)不需要高查詢量和即時性,使得遠端服務成為可行的方案。未來,自動駕駛中的 LLM 可以透過知識蒸餾進行壓縮,以減少運算需求和延遲,目前在這一領域仍有很大發展空間。
3、使用大語言模型理解高精地圖
高精度地圖在自動駕駛車輛技術中起著至關重要的作用,因為它們提供了有關車輛運行的物理環境的基本資訊。高精度地圖中的語意地圖圖層非常重要,因為它捕捉了物理環境的意義和上下文資訊。為了有效地將這些資訊編碼到下一代由騰訊高精地圖AI自動標註系統驅動的自動駕駛中,需要新的模型來將這些多模態特徵映射到語言空間。騰訊已經開發了基於主動學習的THMA高精地圖AI自動標註系統,能夠生產並標記數十萬公里規模的高精度地圖。為了促進這一領域的發展,騰訊在THMA的基礎上提出了MAPLM數據集,包含全景圖像、三維激光雷達點雲和基於上下文的高精度地圖註釋,以及一個新的問答基準MAPLM-QA
4、人車互動中的大語言模型
#人車互動以及理解人類的駕駛行為,在自動駕駛中也構成了一個重大挑戰。人類駕駛者常常依賴非語言訊號,例如減速讓路或使用肢體動作與其他駕駛者或行人溝通。這些非語言訊號在道路上的溝通中扮演著至關重要的角色。過去有許多涉及自動駕駛系統的事故是因為自動駕駛汽車的行為往往出乎其他駕駛員意料。未來,MLLM 能夠整合來自各種來源的豐富上下文信息,並分析駕駛員的視線、手勢和駕駛風格,以更好地理解這些社交信號並做出高效規劃。透過估計其他駕駛者的社交訊號,LLM 可以提高自動駕駛汽車的決策能力和整體安全性。
個人化自動駕駛
#隨著自動駕駛汽車的發展,一個重要的方面是考慮它們如何適應使用者個人的駕駛偏好。越來越多的人認為,自動駕駛汽車應該模仿其用戶的駕駛風格。為了實現這一點,自動駕駛系統需要學習並整合使用者在各個方面的偏好,例如導航、車輛維護和娛樂。 LLM 的指令調整 (Instruction Tunning) 能力和情境學習能力使其非常適合將使用者偏好和駕駛歷史資訊整合到自動駕駛汽車中,從而提供個人化的駕駛體驗。
總結
多年來,自動駕駛一直是人們關注的焦點,吸引眾多創投。將 LLM 整合到自動駕駛汽車中會帶來獨特的挑戰,但克服這些挑戰將顯著增強現有的自動駕駛系統。可以預見的是,LLM 支援的智慧座艙具備理解駕駛場景和使用者偏好的能力,並在車輛與乘員之間建立更深層的信任。此外,部署 LLM 的自動駕駛系統將可以更好地應對道德困境,涉及權衡行人的安全與車輛乘員的安全,促進在複雜的駕駛場景中更可能符合道德的決策過程。本文整合了 WACV 2024 LLVM-AD 研討會委員會成員的見解,旨在激勵研究人員為開發由 LLM 技術支援的下一代自動駕駛汽車做出貢獻。
以上是系統研究揭示下一代自動駕駛系統的不可或缺的大模型的詳細內容。更多資訊請關注PHP中文網其他相關文章!