
微軟首次推出27億參數的Phi-2模型,效能超過許多大型語言模型

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-12-14 23:17:471348瀏覽
微軟發布了一款名為Phi-2的人工智慧模型,該模型展現了不凡的能力,其性能可媲美甚至超越規模是其25倍的、更大、更成熟的模型。
最近微軟在一篇部落格文章中宣布Phi-2是一個擁有27億參數的語言模型,相比其他基礎模型,Phi-2表現出先進的性能,特別是在複雜的基準測試中,這些測驗評估了推理、語言理解、數學、編碼和常識能力。現在Phi-2已經透過微軟Azure人工智慧工作室的模型目錄發布,這意味著研究人員和開發人員可以將其整合到第三方應用程式中
Phi-2是由微軟首席執行官Satya Nadella在11月份的Ignite大會上首次發布的。該產品的強大功能來自於微軟所稱的「教科書品質」數據,這些數據是專門為知識而設計的,並且還借鑒了其他模型的洞見技術
Phi-2 的獨特之處在於,以往大型語言模型的能力常常與其參數規模密切相關。一般來說,參數越多的模型意味著更強大的能力。然而,Phi-2 的出現改變了這個傳統觀念
微軟表示,Phi-2在一些基準測試中展示了與更大型的基礎模型相當甚至超越它們的能力。這些基準測試包括了Mistral AI的70億參數的Mistral、Meta Platforms公司的130億參數的Llama 2,甚至在一些基準測試中超過了700億參數的Llama-2
一個令人驚訝的說法可能是,它的性能甚至超過了Google的Gemini Nano,後者是上週發布的Gemini系列中效率最高的一款。 Gemini Nano專為設備上的任務而設計,可以在智慧型手機上運行,實現文本摘要、高級校對、語法修正以及上下文智能回復等功能
#微軟的研究人員說,Phi-2涉及的測驗非常廣泛,包括語言理解、推理、數學、編碼挑戰等。

該公司表示,Phi-2之所以能取得如此優異的成績,是因為它是用精心挑選的教科書級資料訓練而成,這些資料旨在教授推理、知識和常識,這意味著它可以從更少的資訊中學到更多的東西。微軟的研究人員也使用了一些技術,允許從較小的模型中獲取知識。
研究人員指出,值得注意的是,Phi-2在不使用基於人類回饋的強化學習或教學性微調等技術的情況下,仍然能夠實現強大的表現。這些技術通常用於改善人工智慧模型的行為。儘管沒有使用這些技術,但與其他使用了這些技術的開源模型相比,Phi-2在減少偏見和有害內容方面仍然表現出色。該公司認為這是因為資料整理的客製化工作所起到的作用
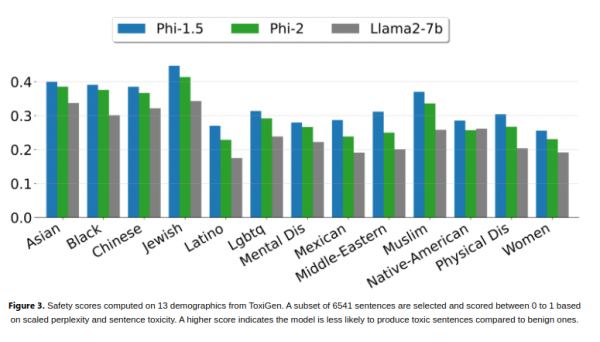
微軟研究人員稱Phi-2是「小型語言模型(SLM)」系列的最新版本。 Phi-1是該系列的第一個模型,今年稍早首次發布,它擁有13億個參數,並針對基本的Python編碼任務進行了微調。今年9月,微軟公司推出了Phi-1.5,該模型擁有13億個參數,並使用了新的資料來源進行訓練,其中包括用自然語言程式設計生成的各種合成文字
微軟表示,Phi-2的高效性使其成為研究人員探索增強人工智慧安全性、可解釋性和語言模型道德發展等領域的理想平台。
以上是微軟首次推出27億參數的Phi-2模型,效能超過許多大型語言模型的詳細內容。更多資訊請關注PHP中文網其他相關文章!