
新標題:即時渲染進化!基於射線的三維重建創新方法

- 王林轉載
- 2023-12-14 20:30:551118瀏覽
 圖片
圖片
論文連結:https://arxiv.org/pdf/2310.19629
程式碼連結:https://github.com/vLAR-group/RayDF
首頁:需要進行改寫的內容是:https://vlar-group.github.io/RayDF.html
重新撰寫的內容: 實作方法:

RayDF的整體流程與組成部分如下所示(見圖1)
一、Introduction
在機器在視覺和機器人領域的許多前沿應用中,學習準確且高效的三維形狀表達是非常重要的。然而,現有的基於三維座標的隱式表達在表示三維形狀或是渲染二維影像時,需要耗費昂貴的計算成本;相較之下,基於射線的方法能夠有效率地推斷出三維形狀。然而,已有的基於射線的方法沒有考慮到多視角下的幾何一致性,導致在未知視角下難以恢復出準確的幾何形狀
針對這些問題,本論文提出一個全新的維護了多視角幾何一致性的基於射線的隱式表達方法RayDF。此方法基於簡單的射線-表面距離場(ray-surface distance field),透過引入全新的雙射線可見性分類器(dual-ray visibility classifier)和多視角一致性優化模組(multi-view consistency optimization module),學習得到滿足多視角幾何一致的射線-表面距離。實驗結果表明,改方法在三個資料集上實現了優越的三維表面重建效能,並達到了比基於座標的方法快1000倍的渲染速度(見Table 1)。

以下是主要的貢獻:
- #採用射線-表面距離場來表示三維形狀,這個表達比現有的基於座標的表達更有效率。
- 設計了全新的雙射線可見性分類器,透過學習任意一對射線的空間關係,使得所學的射線-表面距離場能夠在多視角下保持幾何一致性。
- 在多個資料集上證明了該方法在三維形狀重建上的準確性和高效性。
二、Method
2.1 Overview
#如圖1所示,RayDF包含兩個網路及一個最佳化模組。對於主網路ray-surface distance network,只需輸入一條射線,即可得到射線起點到射線打到的幾何表面點之間的距離值。其中,如圖2所示,RayDF使用一個包圍三維場景的球對輸入的射線進行參數化,將參數化得到的四維球座標(入射點和出射點)作為網路輸入。對於輔助網dual-ray visibility classifier,輸入一對射線和一個幾何表麵點,預測兩條射線之間的相互可見性。這個輔助網絡在訓練好之後,將在後續multi-view consistency optimization module中發揮關鍵作用。
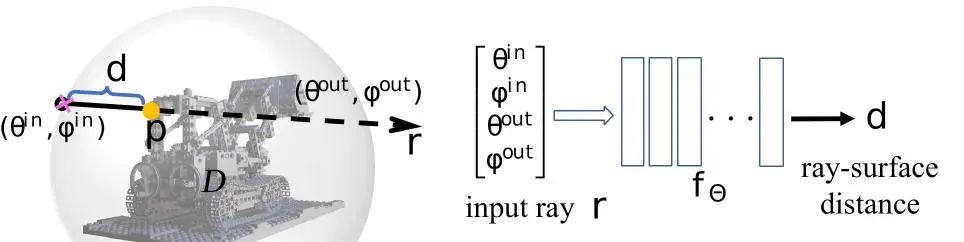
圖2 射線-表面距離場的射線參數化及網路結構
2.2 Dual-ray Visibility Classifier
該方法中的輔助網路是一個預測輸入的兩條射線是否能同時看到一個表麵點的二元分類器。如圖3所示,將輸入的兩條射線所得特徵取平均值,以確保預測的結果不受兩條射線的順序影響。同時,將表麵點進行單獨編碼所得的特徵拼接在射線特徵之後,以增強射線特徵,從而提升分類器的準確性。
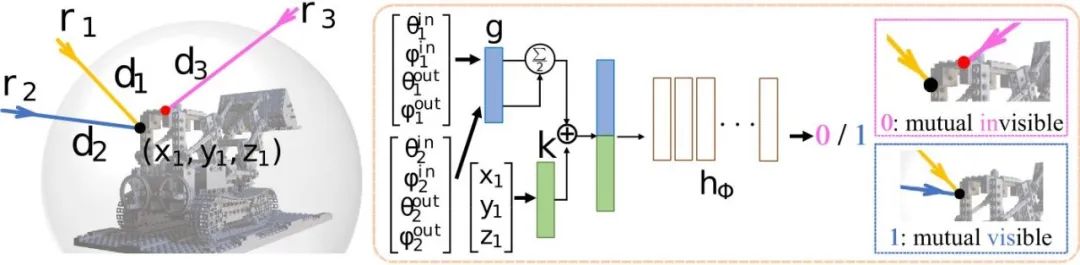
雙射線可見性分類器的框架結構如圖3所示
2.3 Multi-view Consistency Optimization
以設計的主網絡ray-surface distance network和輔助網絡dual-ray visibility classifier為鋪墊,引入多視角一致性優化這一關鍵模組,對兩個網絡進行two-stage訓練。
(1) 首先為輔助網路dual-ray visibility classifier建構用於訓練的射線對。對於一張圖片中的一條射線(對應圖中的一個像素),透過其ray-surface distance可知對應的空間表麵點,將其投影到訓練集中的剩餘視角下,即得到另一個射線;而該射線有其對應的ray- surface distance,文章設定閾值10毫米來判斷兩條射線是否相互可見。
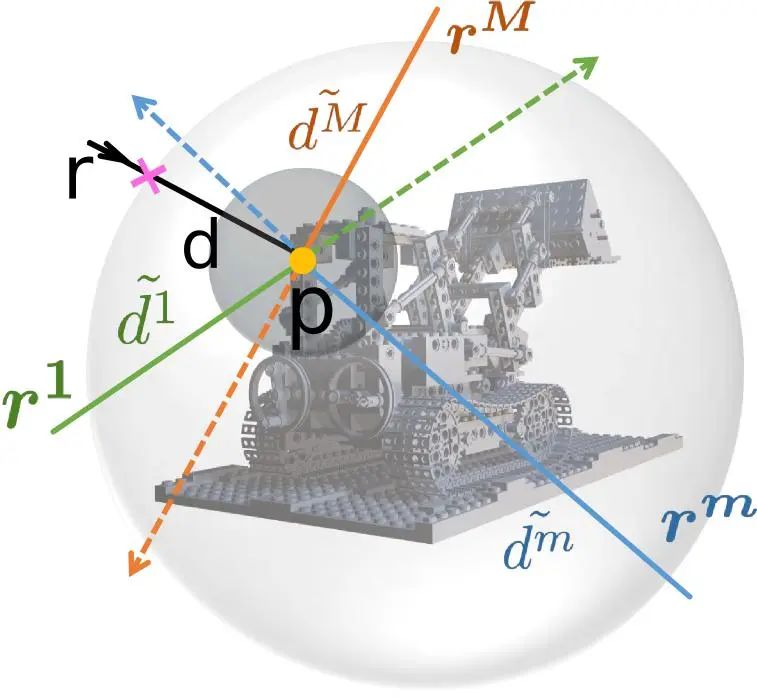
(2) 第二階段是訓練主網路ray-surface distance network使其預測的距離場滿足多視角一致性。如圖4所示,對於一條主射線及其表麵點,以此表麵點為球心均勻採樣,得到若干條multi-view ray。將主射線與這些multi-view ray一一配對,透過訓練好的dual-ray visibility classifier即可得到其相互可見性。再透過ray-surface distance network預測這些射線的ray-surface distance;若主射線與某一條採樣射線是相互可見的,那麼兩條射線的ray-surface distances計算得到的表麵點應是同一個點;依此設計了對應的損失函數,並對主網路進行訓練,最終可以使ray-surface distance field滿足多視角一致性。
2.4 Surface Normal Derivation and Outlier Points Removal
由於在場景表面邊緣處的深度值往往存在突變(存在不連續性),而神經網路又是連續函數,上述ray-surface distance field在表面邊緣處容易預測出不夠準確的距離值,從而導致邊緣處的幾何表面存在雜訊。還好,設計的ray-surface distance field有一個很好的特性,如圖5所示,每個估計的三維表麵點的法向量都可以透過網路的自動微分以閉合形式輕鬆求出。因此,可以在網路推理階段計算表麵點的法向量歐氏距離,若該距離值大於閾值,則該表麵點被視為離群點並剔除,從而得到乾淨的三維重建表面。
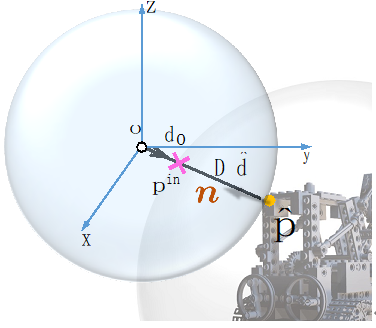
圖5 Surface normal計算
三、Experiments
為了驗證所提出方法的有效性,我們在三個資料集上進行了實驗。這三個資料集分別是object-level的合成資料集Blender [1]、scene-level合成資料集DM-SR [2]以及scene-level真實資料集ScanNet [3]。我們選擇了七個baselines進行效能比較。其中,OF [4]/DeepSDF [5]/NDF [6]/NeuS [7]是基於座標的level-set方法,DS-NeRF [8]是有depth監督的NeRF-based方法,LFN [9]和PRIF [10]是基於射線的兩個baselines
由於RayDF方法的易於直接增加一個radiance分支來學習紋理,因此可以與支援預測radiance field的基準模型進行比較。因此,本論文的對比實驗分為兩組,第一組(Group 1)僅預測距離(幾何),第二組(Group 2)同時預測距離和輻射度(幾何和紋理)
3.1 Evaluation on Blender Dataset
從Table 2和圖6可以看出,在Group 1和2中,RayDF在表面重建上取得了更優的結果,尤其是在最重要的ADE 指標上明顯優於基於座標和射線的baselines。同時在radiance field rendering上,RayDF也取得了與DS-NeRF相當的效能,並且優於LFN和PRIF。
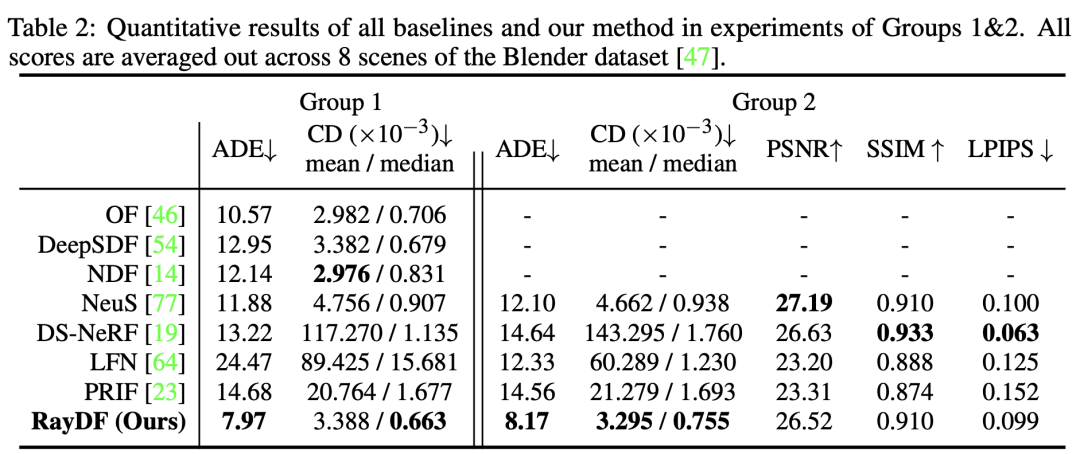
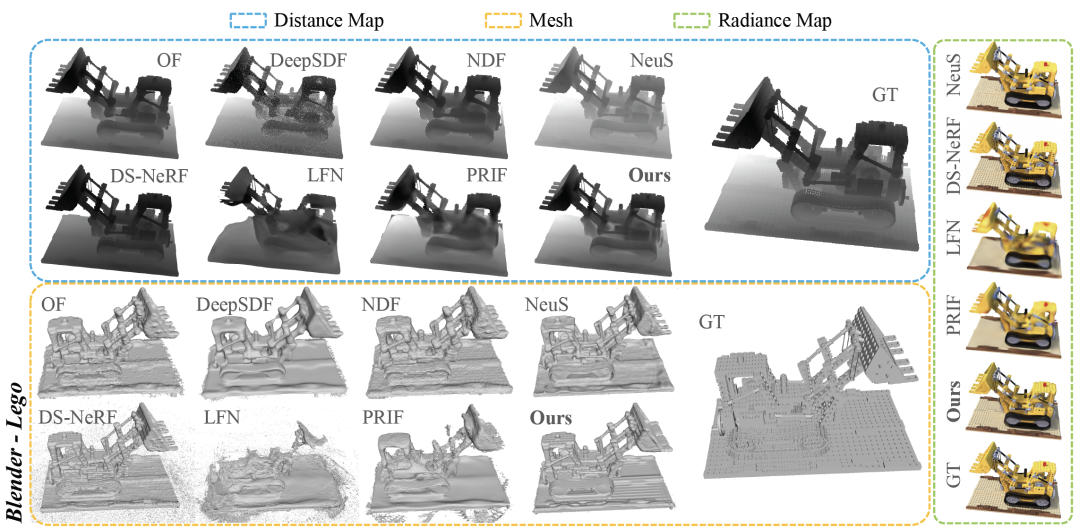
圖6 Blender資料集視覺化對比
3.2 Evaluation on DM-SR Dataset
從Table 3可以看出,在最關鍵的ADE 指標上,RayDF超越了所有baselines。同時,在Group 2的實驗中,RayDF能夠在獲得高品質的新視圖合成的同時,確保恢復出準確的表面形狀(見圖7)。
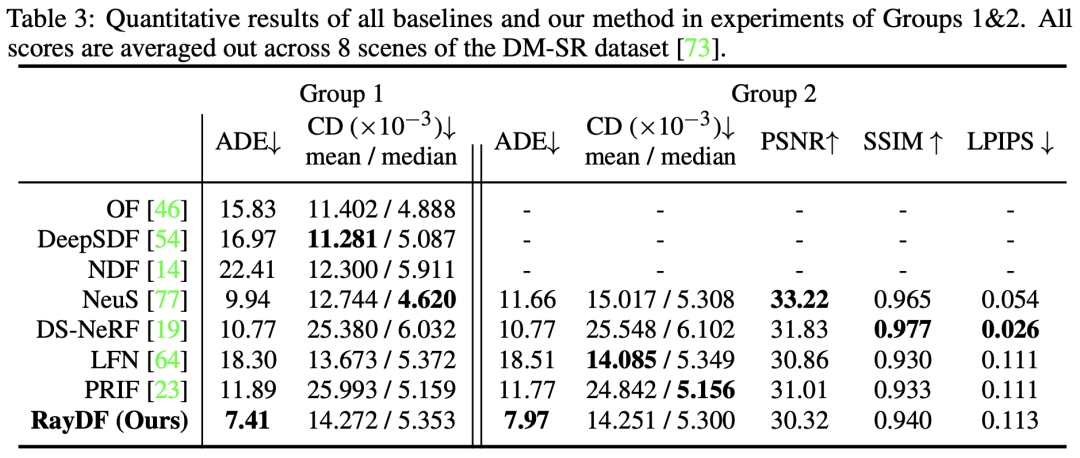
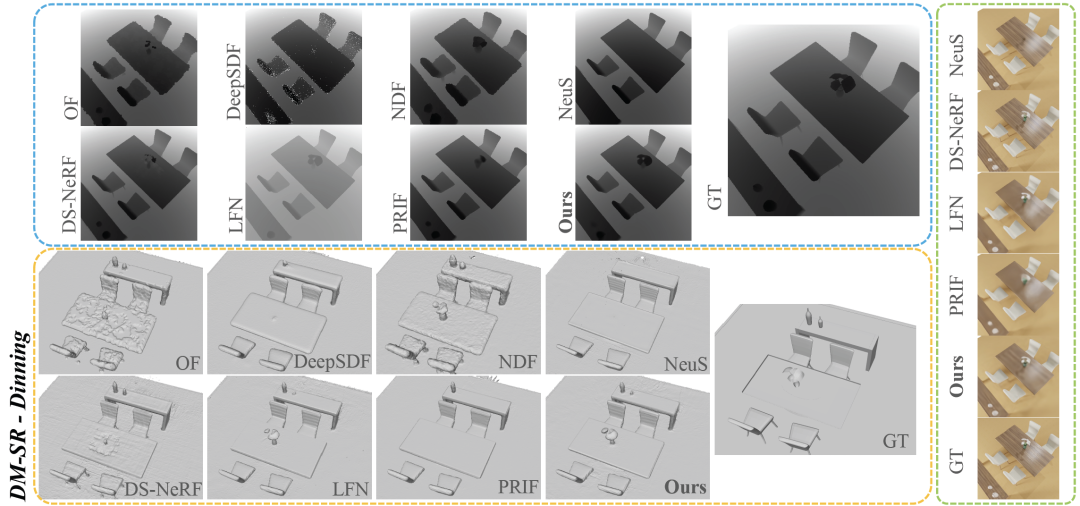
圖 7 DM-SR資料集視覺化對比
3.3 Evaluation on ScanNet Dataset
表4比較了RayDF和baselines在具有挑戰性的真實世界場景中的表現。在第一組和第二組中,RayDF在幾乎所有評估指標上都明顯優於baselines,展現出在恢復複雜的真實世界三維場景方面的明顯優勢
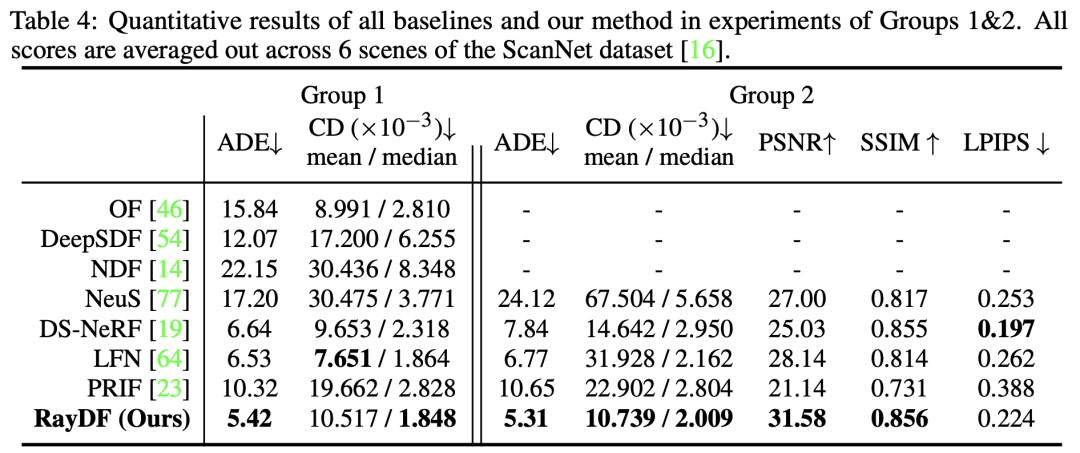

以下是圖8 ScanNet資料集視覺化對比的重寫內容: 在圖8中,我們展示了ScanNet資料集的可視化對比結果
3.4 Ablation Study
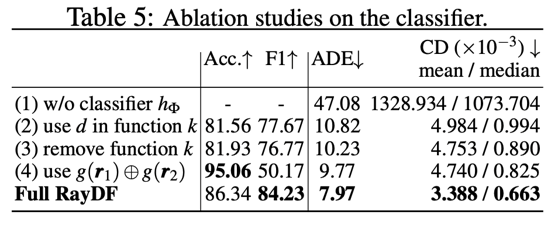
在Blender資料集上進行了消融實驗,論文中的Table 5展示了對於關鍵的雙光線可見性分類器的消融實驗結果
- 如Table 5 (1)所示,如果沒有dual-ray visibility classifier的幫助,ray-surface distance field則會無法對新視角下的射線預測出合理的距離值(見圖9)。
- 在classifier的輸入中,選擇了輸入表麵點座標來作為輔助,如Table 5 (2)和(3)所示,若選擇輸入表麵點距離值作為輔助或是不提供輔助訊息,分類器會獲得較低的準確率和F1分數,導致為ray-surface distance network提供的可見性資訊不夠準確,進而預測出錯誤的距離值。
- 如Table 5 (4)所示,以非對稱的方式輸入一對射線,所訓練得到的分類器準確率較高,但F1分數較低。這表明,這種分類器的穩健性明顯低於用對稱輸入射線訓練的分類器。
其他的切除操作可以在論文和論文附錄中查看

#需要重新寫的內容是: 圖9展示了使用分類器和不使用分類器的可視化對比
四、Conclusion
在使用基於射線的多視角一致性框架進行研究時,論文得出了一個結論,可以透過這種方法高效、準確地學習三維形狀表示。論文中使用了簡單的射線-表面距離場來表示三維形狀的幾何圖形,並利用新穎的雙射線可見性分類器進一步實現了多視角幾何一致性。透過在多個資料集上的實驗證明,RayDF方法具有極高的渲染效率和出色的效能。歡迎對RayDF框架進行進一步擴展。您可以在主頁上查看更多的視覺化結果
需要進行改寫的內容是:https://vlar-group.github.io/RayDF.html

需要重新寫作的內容是:原文連結:https://mp.weixin.qq.com/s/dsrSHKT4NfgdDPYcKOhcOA
以上是新標題:即時渲染進化!基於射線的三維重建創新方法的詳細內容。更多資訊請關注PHP中文網其他相關文章!