
GPT-4被爆作弊! LeCun呼籲謹慎在訓練集上測試,吉娃娃or鬆餅的順序混亂導致錯誤

- PHPz轉載
- 2023-11-13 20:17:23945瀏覽
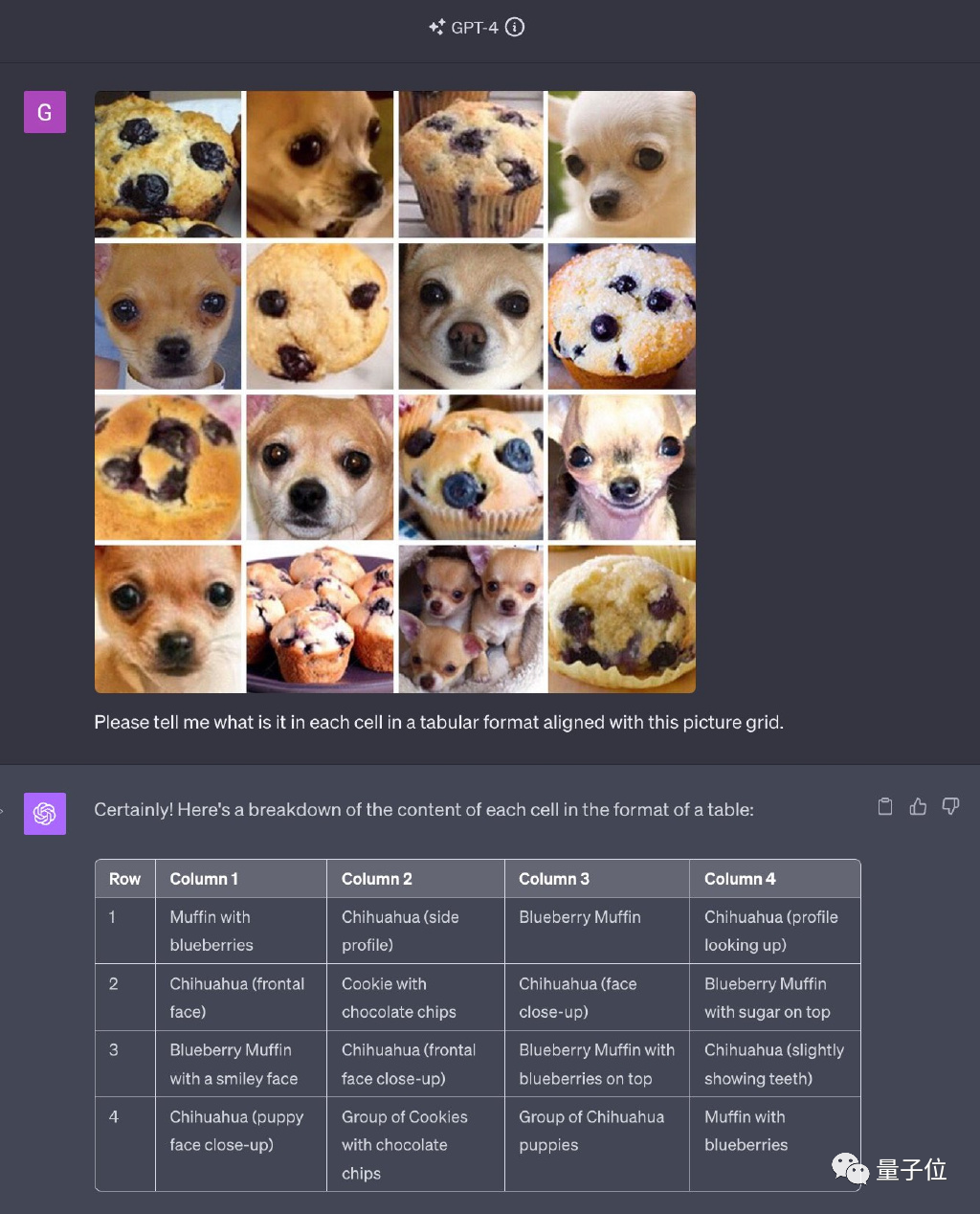
GPT-4解決網路名梗“吉娃娃or藍莓鬆餅”,一度驚艷無數人。
然而,如今它被指控為「作弊」!
 圖片
圖片
全用原題中出現的圖,只是打亂順序和排列方式。
最新版本的GPT-4以其全模式合一的特色而聞名。然而,令人驚訝的是,它在識別圖片數量方面出現了錯誤,而且連原本能夠正確識別的吉娃娃也出現了識別錯誤
 ##圖片
##圖片
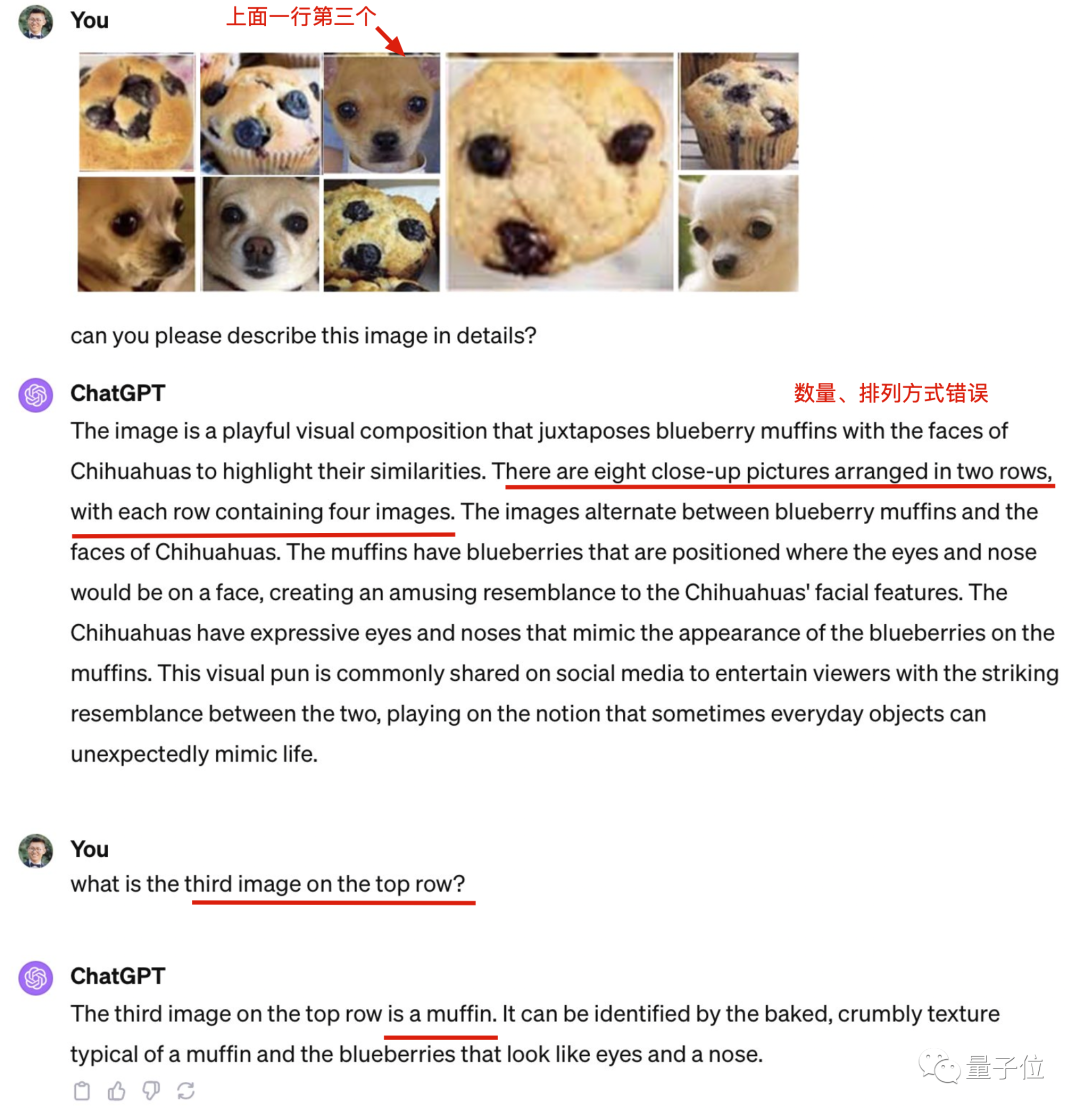
警惕在訓練集上測試。
 圖片
圖片
 圖片
圖片
 圖片
圖片
 圖片
圖片
 圖片
圖片
 #圖片
#圖片
 圖片
圖片
 圖片
圖片
 圖片
圖片
 圖片
圖片
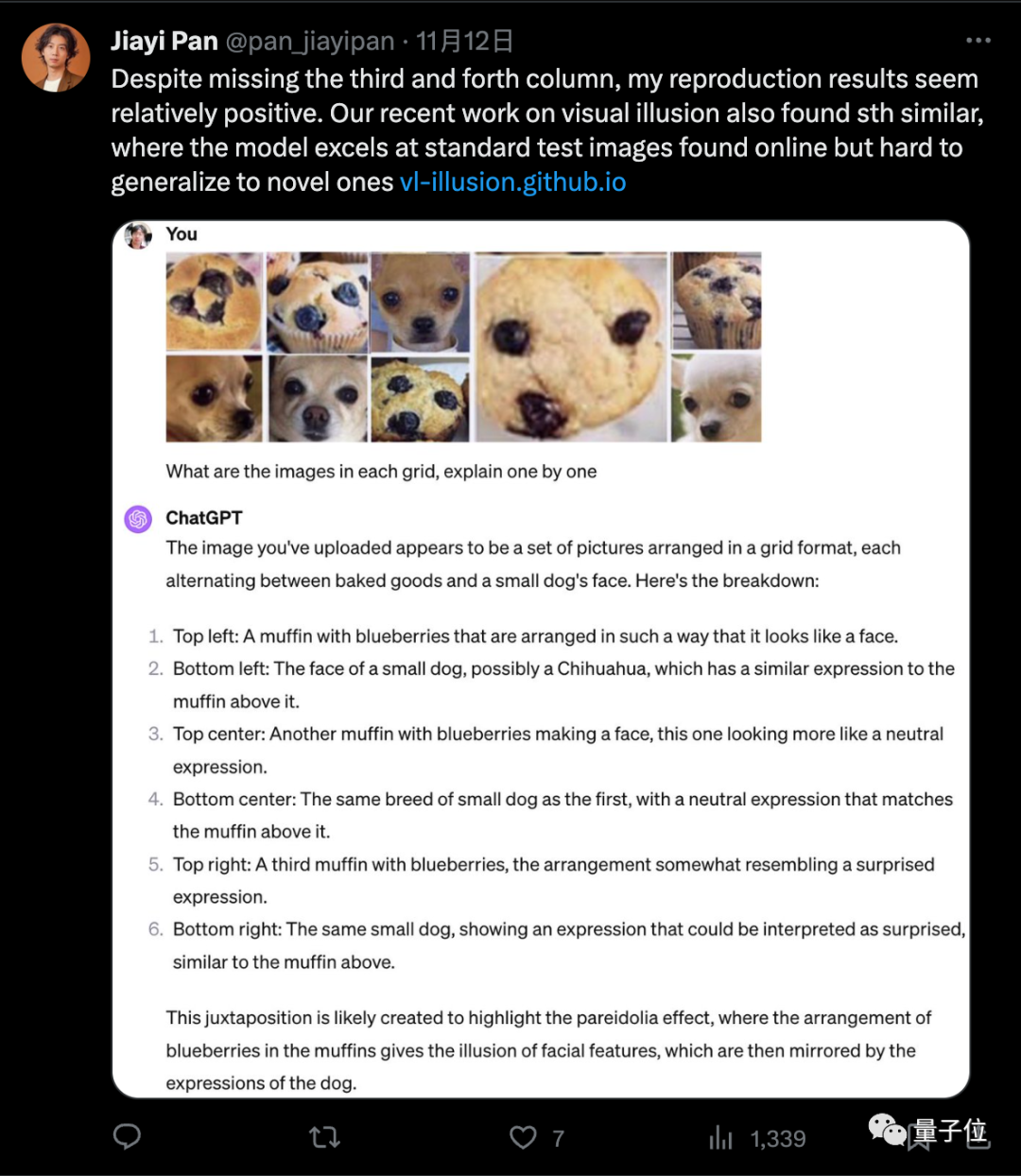
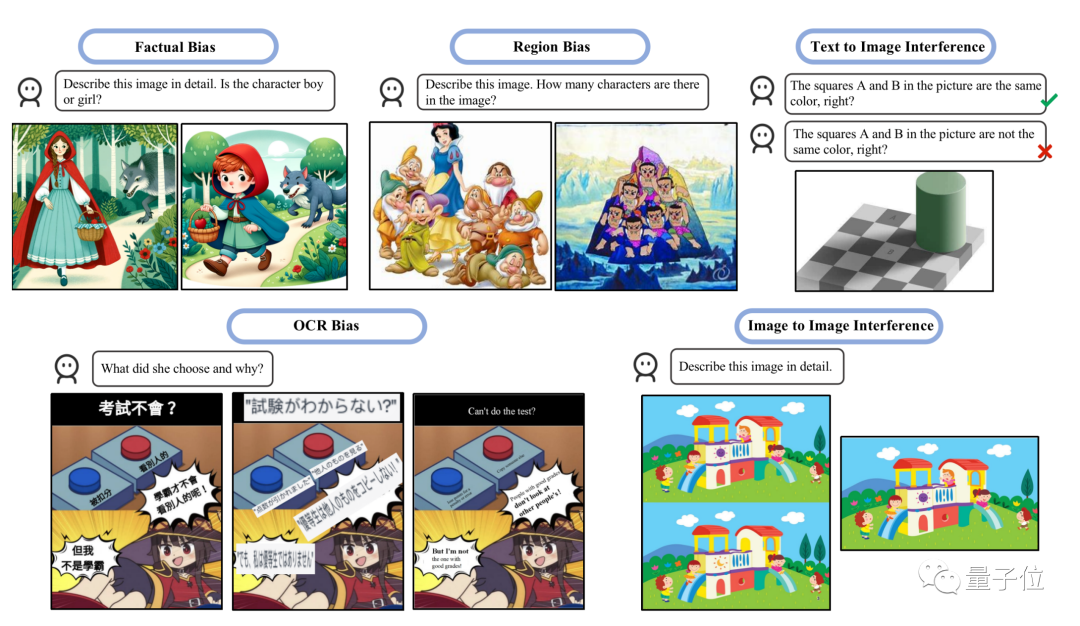
視覺幻覺成熱門方向
大模型「胡說八道」在學術界被稱為幻覺問題,多模態大模型的視覺幻覺問題,已經成了最近研究的熱門方向。
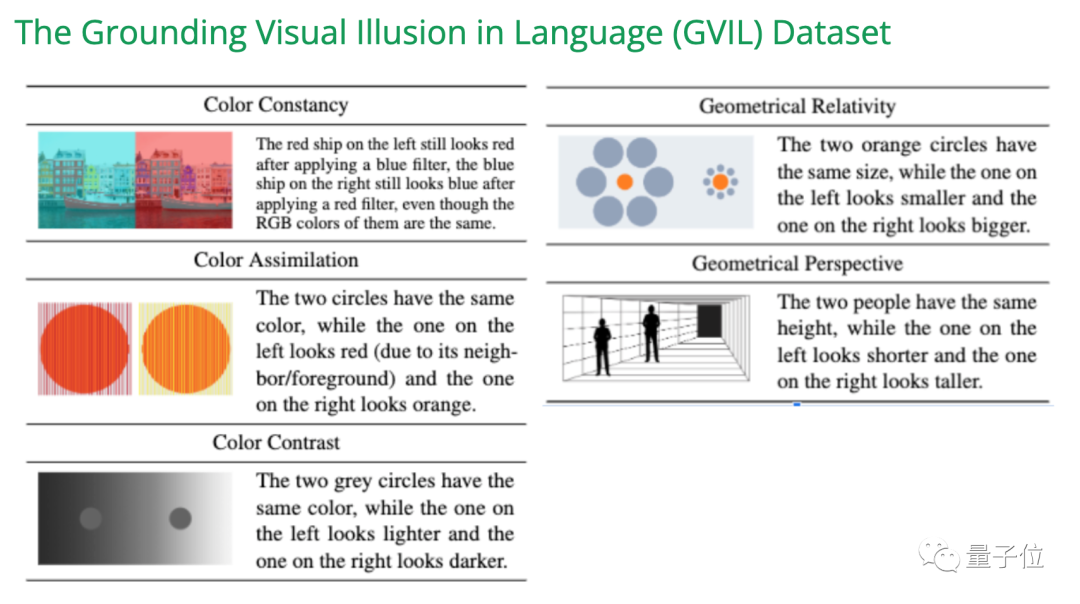
在EMNLP 2023的一項研究中,我們創建了GVIL資料集,其中包含了1600個資料點,並對視覺幻覺問題進行了系統評估
 #圖片
#圖片
研究表明,較大規模的模型更容易受到錯覺的影響,並且更接近人類的感知
 圖片
圖片
#另一項最新研究的重點是評估兩種幻覺類型:偏差和乾擾
 #圖片
#圖片
- 偏差指模型傾向於產生某些類型的反應,可能是由於訓練資料的不平衡所造成的。
- 幹擾則是可能因文字提示的措詞方式或輸入圖像的呈現方式造成去別的場景。
 圖片
圖片
研究中指出GPT-4V一起解釋多個影像時經常會困惑,單獨發送影像時表現較好,符合“吉娃娃or鬆餅”測試中的觀察結果。
 圖片
圖片
流行的緩解措施,如自我糾正和思維鏈提示,並不能有效解決這些問題,並且測試顯示LLaVA和Bard等多模態模型也存在類似的問題
另外研究也發現,GPT-4V更擅長解釋西方文化背景的圖像或帶有英文文字的圖像。
例如GPT-4V能正確數出七個小矮人 白雪公主,卻把七個葫蘆娃數成了10個。
 圖片
圖片
參考連結:[1]https://twitter.com/xwang_lk/status/1723389615254774122[2]https://arxiv. org/abs/2311.00047[3]https://arxiv.org/abs/2311.03287
以上是GPT-4被爆作弊! LeCun呼籲謹慎在訓練集上測試,吉娃娃or鬆餅的順序混亂導致錯誤的詳細內容。更多資訊請關注PHP中文網其他相關文章!