




「別讓大模型被基準評估給坑了」。
這是一項最新研究的題目,來自人民大學資訊學院、高瓴人工智慧學院和伊利諾大學厄巴納-香檳分校。

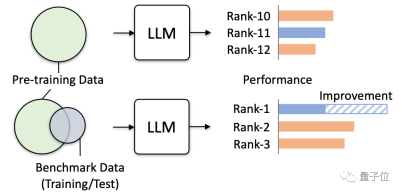
研究發現,基準測試中相關資料意外被用於模型訓練的現象,變得越來越常見了。
因為預訓練語料包含許多公開文本資料,而評估基準也建立在這些資訊之上,本來這種情況就在所難免。
現在隨著大模型試圖蒐集更多公開數據,問題正在加重。
要知道,這種數據重疊帶來的危害非常大。
不僅會導致模型部分測驗分數虛高,還會使模型泛化能力下降、不相關任務表現驟降。甚至可能讓大模型在實際應用上產生「危害」。
所以這項研究正式發出警告,並透過多項模擬測試驗證了可能誘發的實際危害,具體來看。
大模型「被漏題」很危險
研究主要透過模擬極端洩漏資料的情況,來測試觀察大模型會產生的影響。
極端洩漏資料的方式有四種:
- 使用MMLU的訓練集
- 使用MMLU以外所有測試基準的訓練集
- 使用所有訓練集測試prompt
- 使用所有訓練集、測試集和測試prompt(這是最極端情況,僅為實驗模擬,正常情況下不會發生)
然後研究人員給4個大模型進行“投毒”,然後再觀察它們在不同benchmark中的表現,主要評估了在問答、推理、閱讀理解等任務中的表現。
所使用的模型分別是:
- GPT-Neo(1.3B)
- phi-1.5(1.3B)
- OpenLLaMA(3B )
- LLaMA-2(7B)
同時使用LLaMA(13B/30B/65B)作為對照組。
結果發現,當大模型的預訓練數據中包含了某一個評測基準的數據,它會在這一評測基準中表現更好,但在其他不相關任務中的表現會下降。
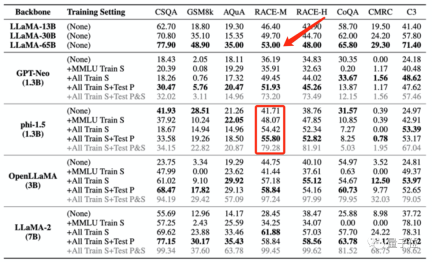
例如使用MMLU資料集訓練後,多個大模型在MMLU測試中分數提高的同時,在常識基準HSwag、數學基準GSM8K中分數下降。
這表示大模型的泛化能力受到影響。

另一方面,也可能造成不相關測驗分數虛高。
如上給大模型進行「投毒」的四個訓練集中僅包含少量中文數據,但是大模型被「投毒」後,在C3(中文基準測試)中的分數卻都變高了。
這種升高是不合理的。

這種訓練資料外洩的情況,甚至會導致模型測試分數,異常超越更大模型的表現。
例如phi-1.5(1.3B)在RACE-M和RACE-H上的表現優於LLaMA65B,後者是前者規模的50倍。
但這種分數上升沒有意義,只是作弊罷了。
更嚴重的是,即使是沒有外洩資料的任務,也會受到影響,表現下降。
下表中可以看到,在程式碼任務HEval中,兩個大模型都出現了分數大幅下降的情況。
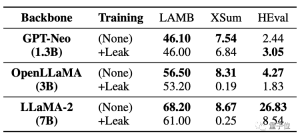
同時被洩漏資料後,大模型的微調提升遠不如未洩露情況。

對於資料重疊/外洩的情況,本項研究分析了各種可能。
例如大模型預訓練語料和基準測試資料都會選用公開文本(網頁、論文等),所以發生重疊在所難免。
而且目前大模型評估都是在本地進行,或是透過API呼叫來獲得結果。這種方式無法嚴格檢查一些不正常的數值提升。
以及當下大模型的預訓練語料都被各方視為核心機密,外界無法評估。
所以導致了大模型被意外「投毒」的情況發生。
那該如何規避這一問題呢?研究團隊也出了一些建議。
如何規避?
研究團隊給了三點建議:
第一,實際情況中很難完全避免資料重疊,所以大模型應該採用多個基準測試進行更全面的評估。
第二,對於大模型開發者,應該要對資料進行脫敏,公開訓練語料的詳細構成。
第三,對於基準測試維護人員,應該提供基準測試資料來源,分析資料被污染的風險,使用更多樣化的提示進行多次評估。
不過團隊也表示本次研究中仍有一定限制。例如沒有對不同程度資料外洩進行系統性測試,以及沒能在預訓練中直接引入資料外洩進行模擬等。
本研究由中國人民大學資訊學院、高瓴人工智慧學院和伊利諾大學香檳分校的多位學者共同帶來。
在研究團隊中我們發現了兩位資料探勘領域大佬:文繼榮和韓家煒。
文繼榮教授現任中國人民大學高瓴人工智慧學院院長、中國人民大學資訊學院院長。主要研究方向為資訊檢索、資料探勘、機器學習、大規模神經網路模型的訓練與應用。
韓家煒教授領銜是資料探勘領域專家,現為伊利諾大學香檳分校電腦系教授,美國電腦協會院士與IEEE院士。
論文網址:https://arxiv.org/abs/2311.01964。
以上是別讓大模型被基準評估坑了!測試集亂入預訓練,分數虛高,模型變傻的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 烹飪創新:人工智能如何改變食品服務Apr 12, 2025 pm 12:09 PM
烹飪創新:人工智能如何改變食品服務Apr 12, 2025 pm 12:09 PMAI增強食物準備 在新生的使用中,AI系統越來越多地用於食品製備中。 AI驅動的機器人在廚房中用於自動化食物準備任務,例如翻轉漢堡,製作披薩或組裝SA
 Python名稱空間和可變範圍的綜合指南Apr 12, 2025 pm 12:00 PM
Python名稱空間和可變範圍的綜合指南Apr 12, 2025 pm 12:00 PM介紹 了解Python函數中變量的名稱空間,範圍和行為對於有效編寫和避免運行時錯誤或異常至關重要。在本文中,我們將研究各種ASP
 視覺語言模型(VLMS)的綜合指南Apr 12, 2025 am 11:58 AM
視覺語言模型(VLMS)的綜合指南Apr 12, 2025 am 11:58 AM介紹 想像一下,穿過美術館,周圍是生動的繪畫和雕塑。現在,如果您可以向每一部分提出一個問題並獲得有意義的答案,該怎麼辦?您可能會問:“您在講什麼故事?
 聯發科技與kompanio Ultra和Dimenty 9400增強優質陣容Apr 12, 2025 am 11:52 AM
聯發科技與kompanio Ultra和Dimenty 9400增強優質陣容Apr 12, 2025 am 11:52 AM繼續使用產品節奏,本月,Mediatek發表了一系列公告,包括新的Kompanio Ultra和Dimenty 9400。這些產品填補了Mediatek業務中更傳統的部分,其中包括智能手機的芯片
 本週在AI:沃爾瑪在時尚趨勢之前設定了時尚趨勢Apr 12, 2025 am 11:51 AM
本週在AI:沃爾瑪在時尚趨勢之前設定了時尚趨勢Apr 12, 2025 am 11:51 AM#1 Google推出了Agent2Agent 故事:現在是星期一早上。作為AI驅動的招聘人員,您更聰明,而不是更努力。您在手機上登錄公司的儀表板。它告訴您三個關鍵角色已被採購,審查和計劃的FO
 生成的AI遇到心理摩托車Apr 12, 2025 am 11:50 AM
生成的AI遇到心理摩托車Apr 12, 2025 am 11:50 AM我猜你一定是。 我們似乎都知道,心理障礙由各種chat不休,這些chat不休,這些chat不休,混合了各種心理術語,並且常常是難以理解的或完全荒謬的。您需要做的一切才能噴出fo
 原型:科學家將紙變成塑料Apr 12, 2025 am 11:49 AM
原型:科學家將紙變成塑料Apr 12, 2025 am 11:49 AM根據本週發表的一項新研究,只有在2022年製造的塑料中,只有9.5%的塑料是由回收材料製成的。同時,塑料在垃圾填埋場和生態系統中繼續堆積。 但是有幫助。一支恩金團隊
 AI分析師的崛起:為什麼這可能是AI革命中最重要的工作Apr 12, 2025 am 11:41 AM
AI分析師的崛起:為什麼這可能是AI革命中最重要的工作Apr 12, 2025 am 11:41 AM我最近與領先的企業分析平台Alteryx首席執行官安迪·麥克米倫(Andy Macmillan)的對話強調了這一在AI革命中的關鍵但不足的作用。正如Macmillan所解釋的那樣,原始業務數據與AI-Ready Informat之間的差距


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)

DVWA
Damn Vulnerable Web App (DVWA) 是一個PHP/MySQL的Web應用程序,非常容易受到攻擊。它的主要目標是成為安全專業人員在合法環境中測試自己的技能和工具的輔助工具,幫助Web開發人員更好地理解保護網路應用程式的過程,並幫助教師/學生在課堂環境中教授/學習Web應用程式安全性。 DVWA的目標是透過簡單直接的介面練習一些最常見的Web漏洞,難度各不相同。請注意,該軟體中

SublimeText3漢化版
中文版,非常好用

mPDF
mPDF是一個PHP庫,可以從UTF-8編碼的HTML產生PDF檔案。原作者Ian Back編寫mPDF以從他的網站上「即時」輸出PDF文件,並處理不同的語言。與原始腳本如HTML2FPDF相比,它的速度較慢,並且在使用Unicode字體時產生的檔案較大,但支援CSS樣式等,並進行了大量增強。支援幾乎所有語言,包括RTL(阿拉伯語和希伯來語)和CJK(中日韓)。支援嵌套的區塊級元素(如P、DIV),

EditPlus 中文破解版
體積小,語法高亮,不支援程式碼提示功能

