
OpenAI影像偵測工具曝光,CTO:AI生成的99%都能認出

- 王林轉載
- 2023-10-19 14:29:01836瀏覽
OpenAI要出手AI影像辨識了。
最新消息,他們公司正在開發一種檢測工具。
根據技術長Mira Murat透露:
此工具精度非常高,正確率可達99%。
目前已進入內部測試流程中,很快就會公開發布。
不得不說,這個準確率還是讓人有點期待的,畢竟之前OpenAI在AI文本檢測上的努力可是以「26%的正確率」慘敗告終。
AI內容偵測,不簡單
OpenAI在AI內容偵測領域早有佈局。
今年1月,他們就發布過一款AI文字偵測器,用來區分AI和人類生成的內容,防止AI文本被濫用。
然而7月該工具就黯然退場:沒有任何公告,頁面直接404。
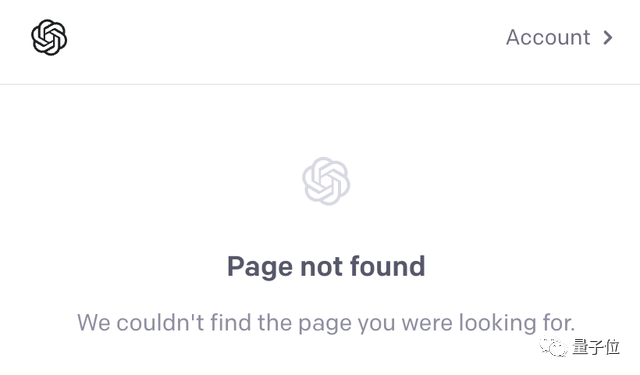
究其原因,還是正確率太低了,「跟瞎猜差不多」。
根據OpenAI自己公佈的數據:
它只能正確識別26%的AI生成文本,同時冤枉9%的人類編寫文本。
在此次匆忙收場之後,OpenAI表示會吸收用戶回饋努力改善,並研究更有效的文字來源技術。
同時,他們也宣布:判斷圖片、影音是否由AI產生的工具也要搞起來。
如今,隨著DALL-E 3的問世以及Midjourney等同類工具的不斷迭代,AI繪畫能力越來越強。
最大的擔憂就是用來偽造全球範圍內的假新聞圖片。
例如reddit上就有一張AI偽造的“2001年卡斯卡迪亞9.1級地震及海嘯”的“現場”,超過1.2k網友點讚。
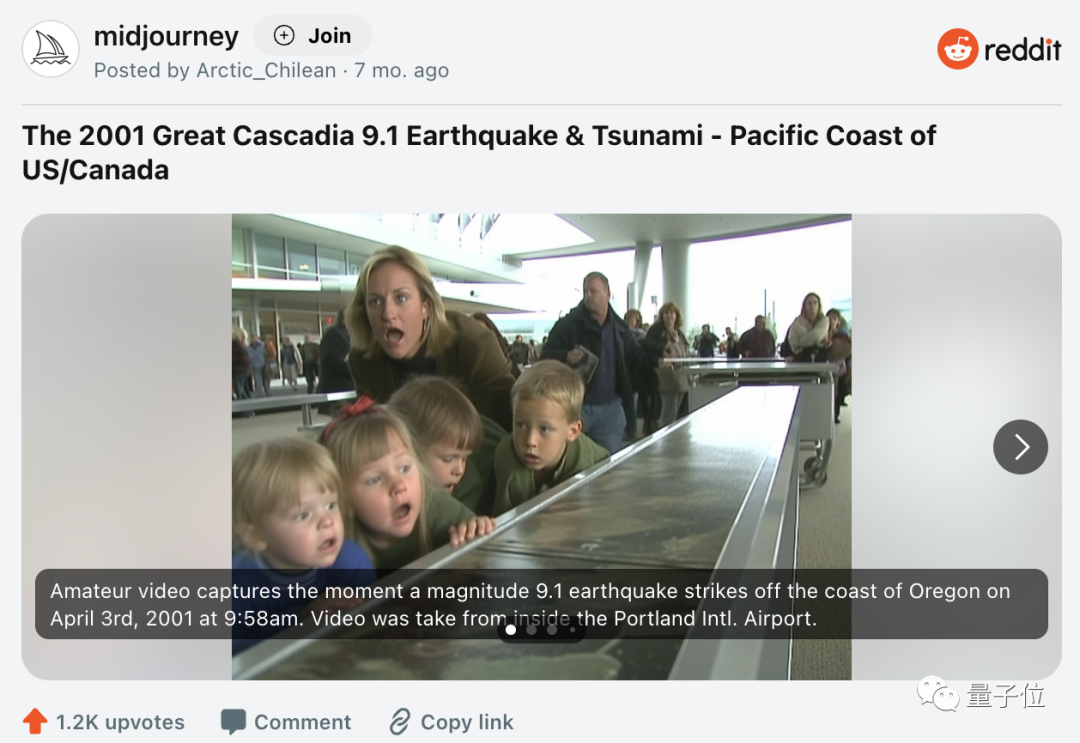
相比AI文字偵測工具,AI畫圖偵測工具的發展顯然更為緊迫(大概是因為「沒人在意演講稿是自己寫的還是秘書寫的”,但“有圖有真相”的內容很難不讓一些人相信)。
不過,如同OpenAI的AI文字偵測工具下線時,有網友就指出:
同時開發生成與偵測工具本身就是矛盾的。
如果一邊做的好就意味著另一邊沒做好,同時還有可能有利益衝突。
比較直接的想法是交給第三方。
但先前第三方在AI文本上的表現也並不好。
而就技術本身來說,另一個還算可行的辦法是在AI生成內容之時就藏下水印。
Google就是這麼做的。
日前(今年8月底),Google已經在OpenAI之前推出了一款AI圖片偵測技術:
SynthID。
它目前與Google的文生圖模型Imagen合作,讓模型生成的每一張圖像都嵌入一個「這是AI生成的元資料標識」—
即使圖像被進行了裁剪、添加濾鏡、更改顏色甚至有損壓縮等一系列修改,也不會影響辨識。

在內部測試中,SynthID準確地識別出了大量經過編輯的AI圖像,但具體的準確率並未透露。
不知道OpenAI即將發布的工具將採用何種技術,並且能否成為市面上精度最高的那一個。
奧特曼回應「造芯計畫」
以上訊息源自於OpenAI CTO與奧特曼本週在《華爾街日報》舉行的Tech Live會議上發表的演講。
會上,兩人也透露了OpenAI的更多消息。
例如下一代大模型可能就快推出了。
叫啥沒透露,但今年7月OpenAI確實就已經申請了GPT-5商標。
有人關心「GPT-5」的準確性,問它是否能夠不會再產生錯誤或虛假內容。
對此,CTO的態度比較謹慎,只是表示「maybe」。
她解釋:
我們在GPT-4的幻覺問題上取得了很大進展,但這還沒有達到我們需要的目標。
奧特曼則談及了「造芯計畫」。
從他的原話來看,並沒有“實錘”,但也留下了無限遐想空間:
如果按照默認路徑我們肯定不會這麼做,但我永遠不會排除這種可能性。
相比“造芯計劃”,奧特曼對於造手機傳言則回復得相當乾脆。
今年9月,蘋果前首席設計官Jony Ive(在蘋果工作了27年)被曝與OpenAI接洽,有消息人士稱奧特曼要開發一種硬體設備,提供一種與AI互動更自然和直觀的方式,可稱為「AI屆的iPhone」。
現在,他告訴大夥:
我自己都還不確定該做什麼呢,只是有一些模糊的想法。
以及:
任何AI設備都不會蓋過iPhone的受歡迎程度,我也沒有興趣與任何智慧型手機競爭。
參考連結:
[1]https://finance.yahoo.com/news/openai- claims-tool-detect-ai-051511179.html?guccounter=1。
[2]https://gizmodo.com/openais-sam-altman-says-he-has-no-interest-in-competing-1850937333。
以上是OpenAI影像偵測工具曝光,CTO:AI生成的99%都能認出的詳細內容。更多資訊請關注PHP中文網其他相關文章!