
打破大模型黑盒,徹底分解神經元! OpenAI對頭Anthropic擊破AI不可解釋性障礙

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-10-08 23:13:011288瀏覽
多年來,我們一直無法理解人工智慧是如何做出決策和產生輸出的
模型開發人員只能決定演算法、數據,最後得到模型的輸出結果,而中間部分-模型是怎麼根據這些演算法和資料輸出結果,就成為了不可見的「黑箱」。

所以就出現了「模型的訓練就像煉丹」這樣的戲言。
但現在,模型黑盒子終於有了可解釋性!
來自Anthropic的研究團隊提取了模型的神經網路中最基本的單位神經元的可解釋特徵。

這將是人類揭開AI黑箱的里程碑式的一步。
Anthropic充滿激動地表示:
#「如果我們能夠理解模型中的神經網路是如何運作的,那麼診斷模型的故障模式、設計修復程序,並讓模型安全地被企業和社會採用就將成為觸手可及的現實!」
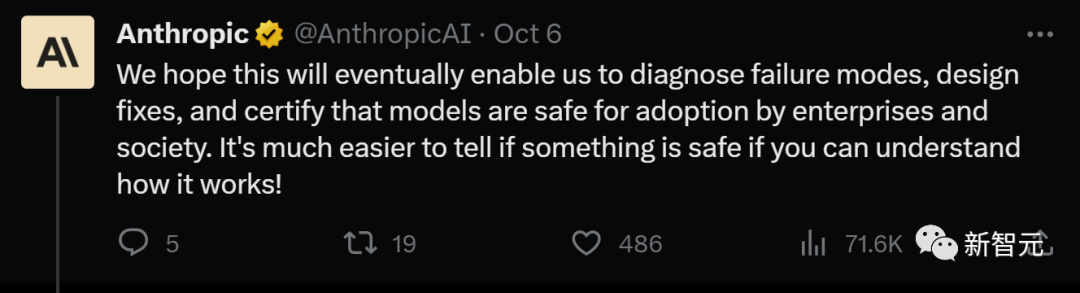
在Anthropic的最新研究報告《走向單語意性:用字典學習分解語言模型》中,研究人員使用字典學習的方法,成功地將包含512個神經元的層分解成了4000多個可解釋的特徵

研究報告網址:https://transformer-circuits.pub/2023/monosemantic-features/index.html
#這些特徵分別代表了DNA序列、法律語言、HTTP請求、希伯來文本和營養成分說明等
當我們孤立地觀察單一神經元的活化時,我們無法看到這些模型屬性中的大部分
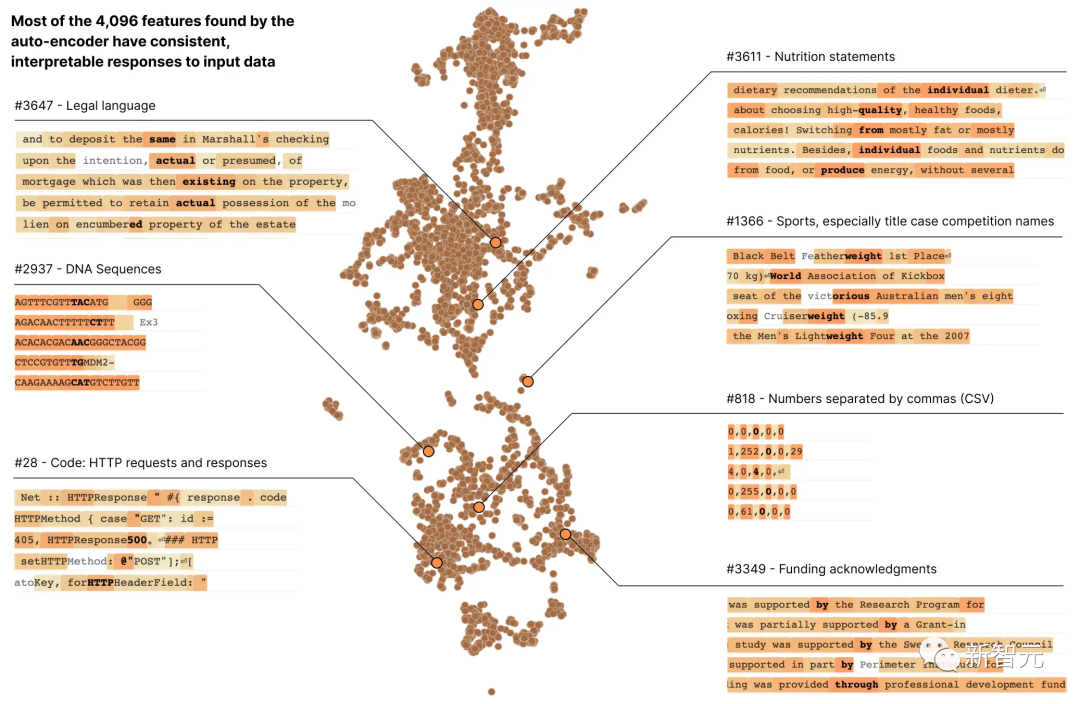
大多數神經元都是「多語義」的,這意味著單一神經元與網路行為之間沒有一致的對應關係
例如,在一個小型語言模型中,單一神經元在許多不相關的上下文中都很活躍,包括:學術引文、英語對話、HTTP 請求和韓文文字。
而在經典視覺模型中,單一神經元會對貓的臉和汽車的前臉做出反應。
在不同的脈絡中,許多研究證明了一個神經元的活化可能具有不同的意義
一個潛在的原因是神經元的多語意性是由於疊加效應。這是一種假設的現象,即神經網路透過為每個特徵分配自己的神經元線性組合來表示資料的獨立特徵,而這種特徵的數量超過了神經元的數量
##如果將每個特徵視為神經元上的一個向量,那麼特徵集就構成了網路神經元活化的一個過完備線性基礎。
在Anthropic之前的Toy Models of Superposition(《疊加玩具模型》)論文中,證明了稀疏性在神經網路訓練中可以消除歧義,幫助模型更好地理解特徵之間的關係,從而減少激活向量的來源特徵的不確定性,使模型的預測和決策更可靠。
這個概念類似於壓縮感知中的思想,其中訊號的稀疏性允許從有限的觀測中還原出完整的訊號。

但在Toy Models of Superposition中提出的三種策略中:
(1)建立沒有疊加的模型,或許可以鼓勵激活稀疏性;
(2)在展現出疊加態的模型中,採用字典學習來尋找過完備特徵
(3)依賴兩者結合的混合方法。
需要進行改寫的內容是:方法(1)無法解決多義性問題,而方法(2)則容易出現嚴重的過度擬合情況
#因此,這次Anthropic的研究人員使用了一種稱為稀疏自動編碼器的弱字典學習演算法,從經過訓練的模型中生成學習到的特徵,這些特徵提供了比模型神經元本身更單一的語意分析單位。
具體來說,研究人員採用了具有512個神經元的MLP單層transformer,並透過從80億個資料點的MLP激活上訓練稀疏自動編碼器,最終將MLP活化分解為相對可解釋的特徵,擴展因子範圍從1×(512個特徵)到256×(131,072個特徵)。
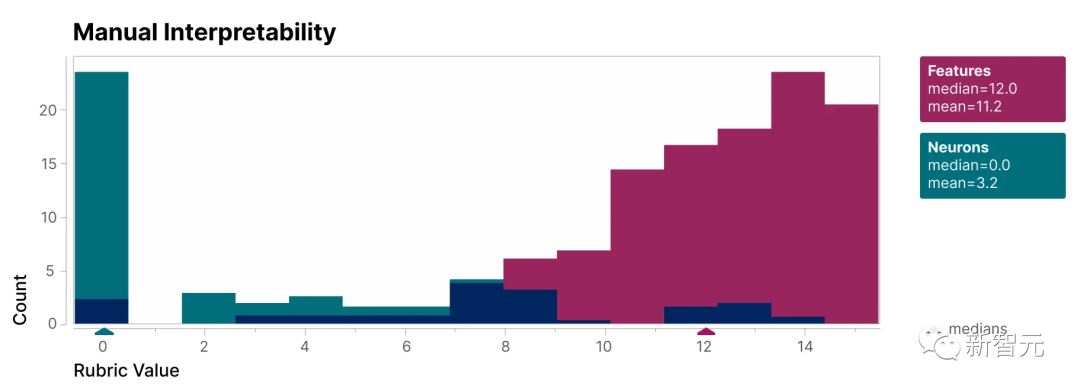
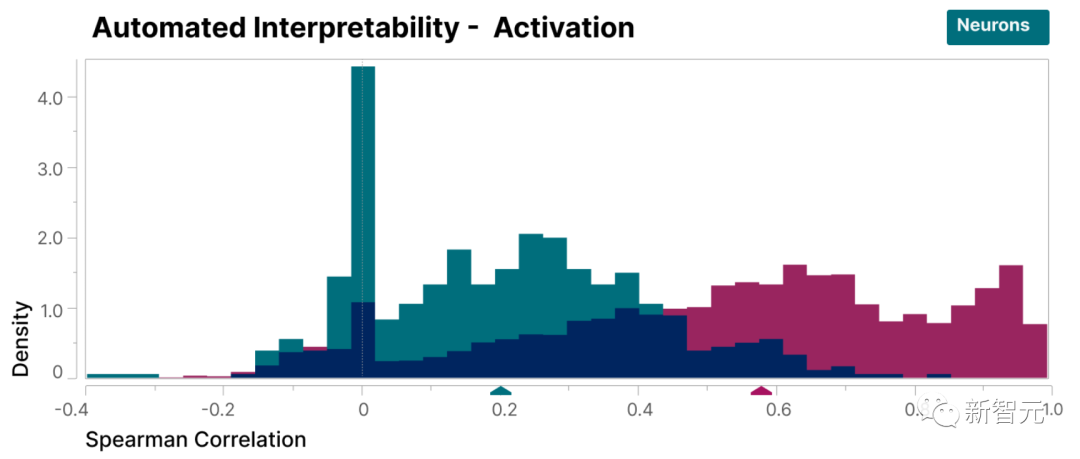
為了驗證本研究發現的特徵比模型的神經元更具可解釋性,我們進行了盲審評估,讓一位人類評估員對它們的可解釋性進行評分
可以看到,特徵(紅色)的得分比神經元(青色)高得多。
研究人員發現的特徵相對於模型內部的神經元來說更容易理解,這一點已經被證明
#此外,研究人員還採用了「自動解釋性」方法,透過使用大型語言模型產生小型模型特徵的簡短描述,並讓另一個模型根據該描述預測特徵激活的能力對其進行評分。
同樣,特徵得分高於神經元,證明了特徵的活化及其對模型行為的下游影響具有一致的解釋。
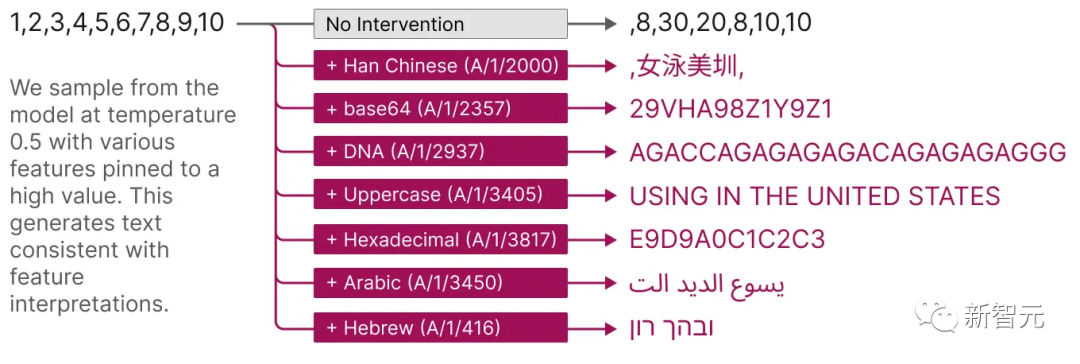
並且,這些擷取的特徵也提供了一種有針對性的方法來引導模型。
如下圖所示,人為啟動特徵會導致模型行為以可預測的方式變更。
以下是提取出的可解釋性特徵的視覺化圖:
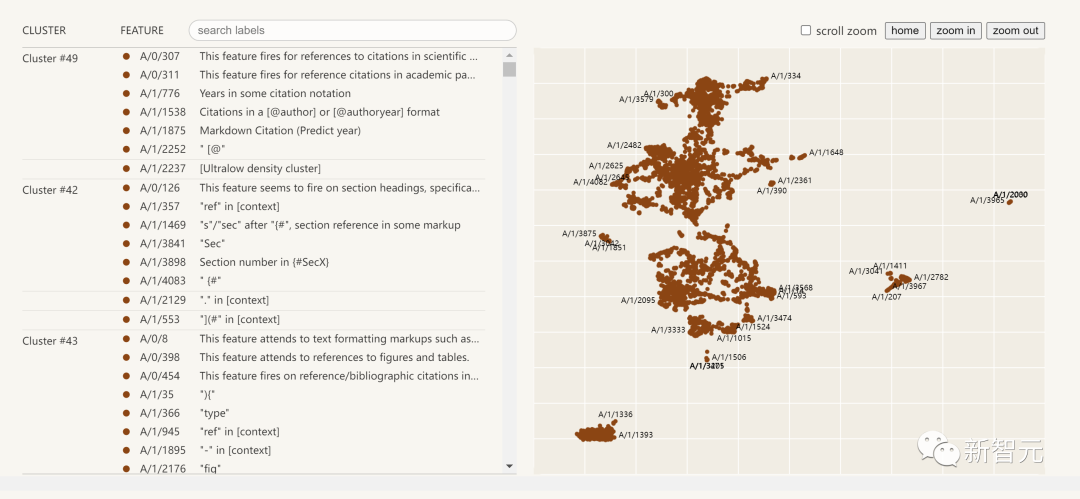
點擊左邊的特徵列表,您可以與神經網路中的特徵空間進行互動式探索
#研究報告摘要
這份來自Anthropic的研究報告,Towards Monosemanticity: Decomposing Language Models With Dictionary Learning,主要可以分為四個部分。
問題設置,研究人員介紹了研究動機,並闡述訓練的transfomer和稀疏自動編碼器。
單一特徵詳細調查,證明了研究發現的幾個特徵是功能上特定的因果單元。
透過全域分析,我們得出結論,典型特徵是可以解釋的,並且它們能夠解釋MLP層的重要組成部分
現象分析,描述了特徵的幾個屬性,包括特徵分割、普遍性,以及它們如何形成類似於「有限狀態自動機」的系統來實現複雜的行為。
結論包括以下7個:
稀疏自動編碼器具有提取相對單一的語意特徵的能力
#稀疏自編碼器能夠產生可解釋的特徵,而這些特徵在神經元的基礎中實際上是不可見的
3. 稀疏自動編碼器特徵可用於介入和引導變壓器的生成。
4. 稀疏自編碼器能產生相對通用的特徵。
隨著自動編碼器大小的增加,特徵有「分裂」的傾向。 重寫後:隨著自動編碼器尺寸的增加,特徵呈現出“分裂”的趨勢
#6. 只需512個神經元即可表示成千上萬個特徵
7. 這些特徵透過連結在一起,類似於「有限狀態自動機」的系統,實現了複雜的行為,如下圖所示
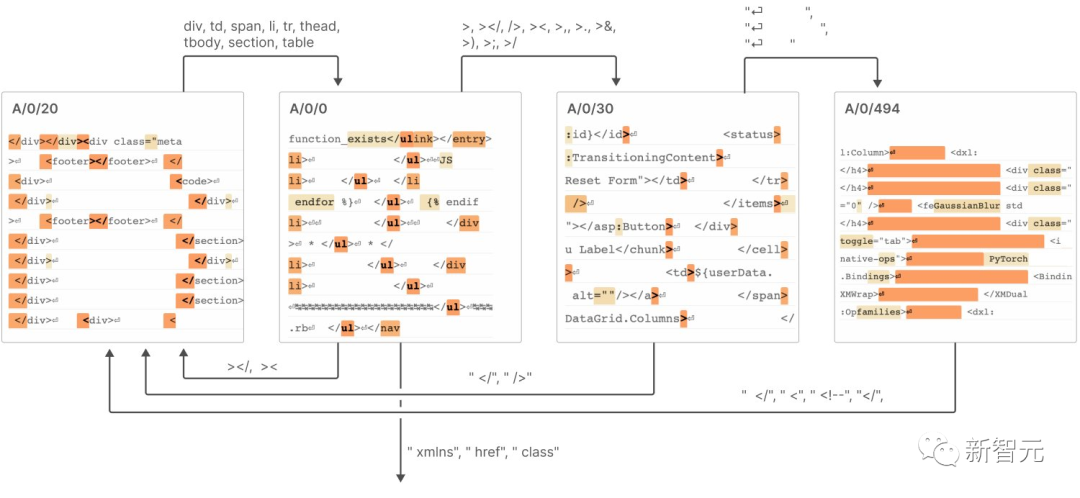
##具體詳細內容可見報告。
Anthropic認為,要將本研究報告中小模型的成功複製到更大的模型上,我們今後面臨的挑戰將不再是科學問題,而是工程問題
為了在大型模型上實現解釋性,需要在工程領域投入更多的努力和資源,以克服模型複雜性和規模帶來的挑戰
包括開發新的工具、技術和方法,以應對模型複雜性和資料規模的挑戰;也包括建立可擴展的解釋性框架和工具,以適應大規模模型的需求。
這將成為解釋性人工智慧和大規模深度學習研究領域的最新趨勢#
以上是打破大模型黑盒,徹底分解神經元! OpenAI對頭Anthropic擊破AI不可解釋性障礙的詳細內容。更多資訊請關注PHP中文網其他相關文章!