大規模語言模型在自然語言處理方面展現出令人驚訝的推理能力,但其內在機制尚不清楚。隨著大規模語言模型的廣泛應用,闡明模型的運作機制對應用安全性、效能限制和可控的社會影響至關重要。 近期,中美多家研究機構(新澤西理工學院、約翰斯・霍普金斯大學、維克森林大學、喬治亞大學、上海交大、百度等)共同發布了大模型可解釋性技術的綜述,分別對傳統的fine-tuning 模型和基於prompting 的超大模型的可解釋性技術進行了全面的梳理,並探討了模型解釋的評估標準和未來的研究挑戰。 
- 論文連結:https://arxiv.org/abs/2309.01029
- Github 連結: https://github.com/hy-zhao23/Explainability-for-Large-Language-Models
為何要解釋大模型有點難?大語言模式在自然語言處理任務上的驚艷表現引起了社會廣泛的關注。同時,如何解釋大模型在跨任務中令人驚豔的表現是學術界面臨的迫切挑戰之一。有別於傳統的機器學習或深度學習模型,超大的模型架構和大量的學習資料使得大模型具備了強大的推理泛化能力。大語言模型 (LLMs) 提供可解釋性的幾個主要困難包括:
- 模型複雜度高。區別於 LLM 時代之前的深度學習模型或傳統的統計機器學習模型,LLMs 模型規模巨大,包含數十億個參數,其內部表示和推理過程非常複雜,很難針對其具體的輸出給出解釋。
- 資料依賴性強。 LLMs 在訓練過程中依賴大規模文字語料,這些訓練資料中的偏見、錯誤等都可能影響模型,但很難完整判斷訓練資料的品質對模型的影響。
- 黑箱性質。我們通常把 LLMs 看做黑箱模型,即使是對於開源的模型來說,例如 Llama-2。我們很難明確地判斷它的內部推理鍊和決策過程,只能根據輸入輸出進行分析,這會給可解釋性帶來困難。
- 輸出不確定性。 LLMs 的輸出常常存在不確定性,對相同輸入可能產生不同輸出,這也增加了可解釋性的難度。
- 評估指標不足。目前對話系統的自動評估指標還不足以完整反映模型的可解釋性,需要更多考慮人類理解的評估指標。
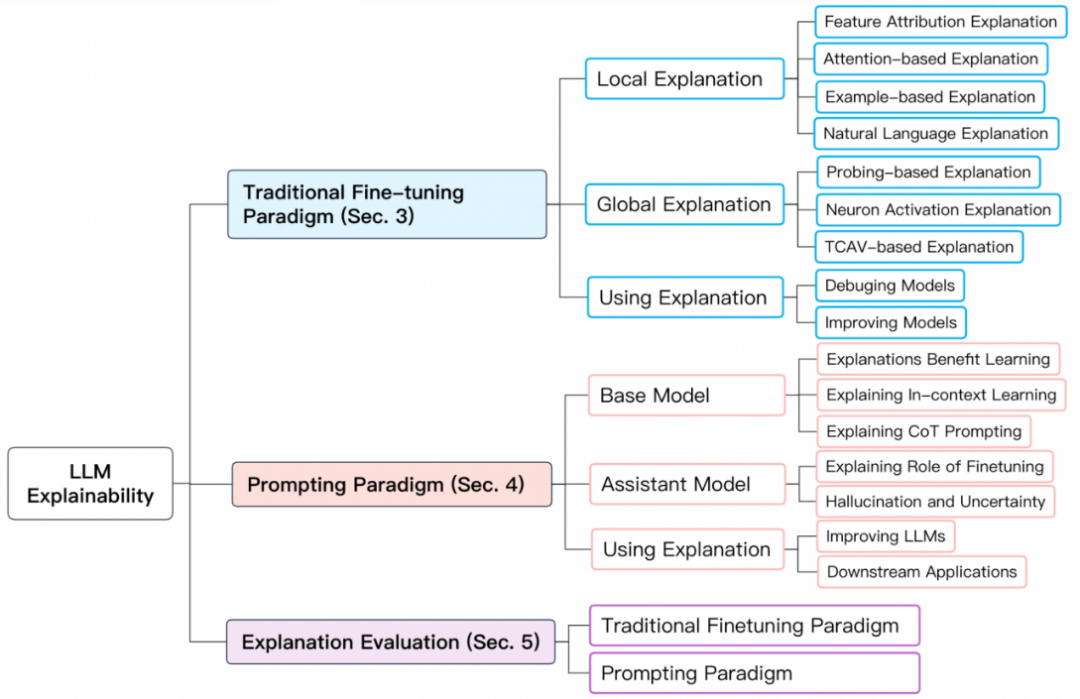
##為了更好的歸納總結大模型的可解釋性,我們將BERT 及以上級別的大模型的訓練範式分為兩種:1)傳統fine-tuning 範式;2)基於prompting 的範式。
對於傳統fine -tuning 範式,首先在一個較大的未標記的文本庫上預訓練一個基礎語言模型,再透過來自特定領域的標記資料集進行fine-tuning。常見的此類模型有 BERT, RoBERTa, ELECTRA, DeBERTa 等人。
基於prompting 的範式透過使用prompts 實現zero-shot 或few-shot learning。與傳統 fine-tuning 範式相同,需要預先訓練基礎模型。但是,基於 prompting 範式的微調通常由 instruction tuning 和 reinforcement learning from human feedback (RLHF) 實作。常見的此類模型包括 GPT-3.5, GPT 4, Claude, LLaMA-2-Chat, Alpaca, Vicuna 等。其訓練流程如下圖:
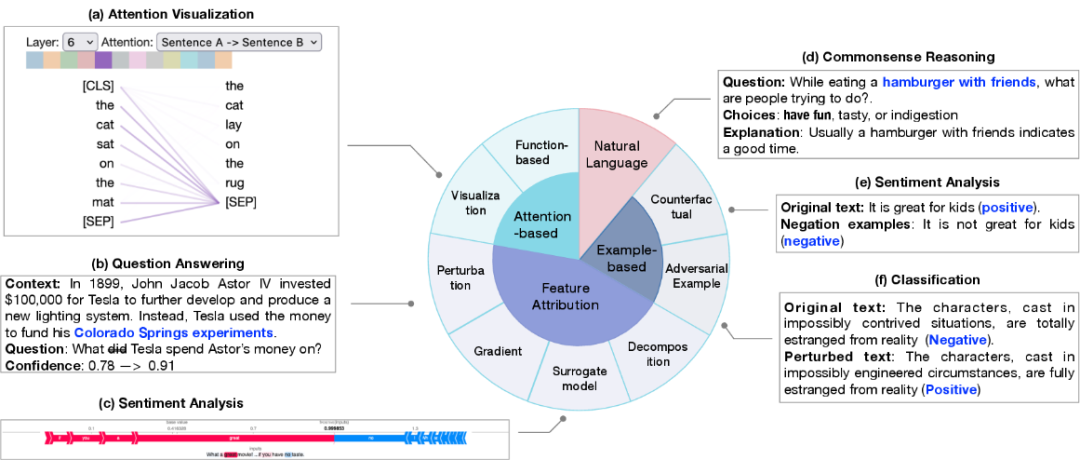
#基於傳統fine-tuning 範式的模型解釋包括對單一預測的解釋(局部解釋)和模型結構層級組分如神經元,網路層等的解釋(全局解釋)。 #局部解釋對單一樣本預測進行解釋。其解釋方法包括特徵歸因(feature attribution)、基於注意力機制的解釋(attention-based)、基於樣本的解釋(example-based)、基於自然語言的解釋(natural language explanation)。
1. 特徵歸因的目的是衡量每個輸入特徵(例如單字、片語、文字範圍)與模型預測之間的相關性。特徵歸因的方法可以分為:
基於擾動的解釋,透過修改特定的輸入特徵來觀察對輸出結果的影響
根據梯度的解釋,將輸出對輸入的偏微分作為相應輸入的重要性指標
#替代模型,使用簡單的人類可理解的模型去擬合複雜模型的單個輸出,從而獲取各輸入的重要性;
基於分解的技術,旨在將特徵相關性分數進行線性分解。
2. 基於注意力的解釋:注意力通常被作為一種專注於輸入中最相關部分的途徑,因此註意力可能學習到可以用於解釋預測的相關性資訊。常見的注意力相關的解釋方法包括:
- 注意力視覺化技術,直觀地觀察注意力分數在不同尺度上的變化;
- 基於函數的解釋,如輸出對注意力的偏微分。然而,學術界對於將注意力作為一個研究角度依然充滿爭議。
3. 基於樣本的解釋從個案的角度對模型進行探測和解釋,主要分為:對抗樣本和反事實樣本。
- 對抗樣本是針對模型對微小變動非常敏感的特性而產生的數據,自然語言處理中通常透過修改文字得到,人類難以區別的文本變換通常會導致模型產生不同的預測。
- 反事實樣本則是透過將文本進行如否定的變形,通常也是對模型因果推論能力的偵測。
4. 自然語言解釋使用原始文字和人工標記的解釋進行模型訓練,使得模型可以產生自然語言解釋模型的決策過程。 #全域解釋旨在從模型構成的層麵包括如神經元,隱藏層和更大的組塊,為大模型的工作機制提供更高階的解釋。主要探究在不同網路構成部分學習到的語意知識。
- 基於探針的解釋探針解釋技術主要基於分類器進行探測,透過在預訓練模型或微調模型上訓練一個淺層分類器,然後在一個holdout 資料集上進行評估,使得分類器能夠識別語言特徵或推理能力。
- 神經元活化 傳統神經元活化分析只考慮一部分重要的神經元,再學習神經元與語意特性之間的關係。近來,GPT-4 也被用來解釋神經元,不同於選取部分神經元來解釋,GPT-4 可以用來解釋所有的神經元。
- 基於概念的解釋 先將輸入映射到一組概念中,再透過測量概念對預測的重要性來解釋模型。
基於prompting 範式的模型解釋,需要對基礎模型和助手模型分別解釋以區別兩種模型的能力,並探究模型學習的路徑。其探究的問題主要包括:為模型提供解釋對 few-shot learning 的益處;理解 few-shot learning 和思維鏈能力的來源。
- 解釋對模型學習的好處探究在few-shot learning 的情況下解釋是否對模型學習有幫助。
- 情境學習 探究情境學習在大模型中的作用機制,以及區分情境學習在大模型中和中等模型的差異。
- 思考鏈 prompting 探究思維鏈 prompting 提升模型的表現的原因。
Fine-tuning 的角色助手模型通常先經過預訓練獲得通用語意知識,在透過監督學習和強化學習來獲取領域內知識。而助手模型的知識主要來自於哪個階段依然有待研究。 幻覺與不確定性 大模型預測的準確性與可信度仍是目前研究的重要課題。儘管大模型的推理能力強大,但其結果常常出現錯誤訊息和幻覺。這種預測的不確定性為其廣泛應用帶來了巨大的挑戰。
################ ##模型解釋的評估指標包含合理性(plausibility),忠實度(faithfulness),穩定性(stability),穩健性(robustness) 等。論文主要講述了兩個被廣泛關注的圍度:1)對人類的合理性;2)對模型內在邏輯的忠實度。 ###############對傳統 fine-tuning 模型解釋的評估主要集中在局部解釋。合理性通常需要將模型解釋與人工標註的解釋依照設計的標準進行測量評估。而忠實性則更注重量化指標的表現,由於不同的指標關注模型或數據的面向不同,對於忠實性的衡量仍缺乏統一的標準。基於 prompting 模型解釋的評估則有待進一步的研究。#1.缺乏有效的正確解釋。 其挑戰來自兩個方面:1)缺乏設計有效解釋的標準;2)有效解釋的缺乏導致對解釋的評估同樣缺乏支撐。 2. 湧現現象的根源未知。 對大模型湧現能力的探究可以分別從模型和資料的角度進行,從模型的角度,1)引起湧現現象的模型結構;2)具備跨語言任務超強表現的最小模型尺度和複雜度。從資料的角度,1)決定特定預測的資料子集;2)湧現能力與模型訓練和資料污染的關係;3)訓練資料的品質和數量對預訓練和微調各自的影響。 3. Fine-tuning 範式與 prompting 範式的差異。 兩者在 in-distribution 和 out-of-distribution 的不同表現意味著不同的推理方式。 1)在資料同分佈(in-distribution)之下,其推理範式的差異;2)在資料不同分佈的情況下,模型穩健性的差異根源。 4. 大模型的捷徑學習問題。 兩種範式之下,模型的捷徑學習問題存在於不同的面向。儘管大模型由於資料來源豐富,捷徑學習的問題相對緩和。闡明捷徑學習形成的機制並提出解決方法對模型的泛化依然重要。 5. 注意力冗餘。 注意力模組的冗餘問題在兩個範式之中廣泛存在,對注意力冗餘的研究可以為模型壓縮技術提供一種解決方式。 6. 安全性與道德性。 大模型的可解釋性對控制模型並限制模型的負面影響至關重要。如偏差、不公平、資訊污染、社會操控等問題。建立可解釋的 AI 模型可以有效地避免上述問題,並形成符合道德規範的人工智慧系統。 以上是解析大型模型的可解釋性:綜述揭示真相,解答疑惑的詳細內容。更多資訊請關注PHP中文網其他相關文章!