



特徵重要性分析用於了解每個特徵(變數或輸入)對於做出預測的有用性或價值。目標是確定對模型輸出影響最大的最重要的特徵,它是機器學習中經常使用的一種方法。
為什麼特徵重要性分析很重要?
如果有一個包含數十個甚至數百個特徵的資料集,每個特徵都可能對你的機器學習模型的性能有所貢獻。但是並不是所有的特徵都是一樣的。有些可能是冗餘的或不相關的,這會增加建模的複雜性並可能導致過度擬合。
特徵重要性分析可以辨識並專注於最具資訊量的特徵,從而帶來以下幾個優勢: 1. 提供洞察力:透過分析特徵的重要性,我們能夠深入了解資料中哪些特徵對結果產生了最大的影響,從而幫助我們更好地理解資料的本質。 2. 最佳化模型:透過辨識關鍵特徵,我們可以優化模型的效能,減少不必要的運算和儲存開銷,提高模型的訓練和預測效率。 3. 特徵選擇:特徵重要性分析可以幫助我們選擇最具預測能力的特徵,進而提升模型的準確度和泛化能力。 4. 解釋模型:特徵重要性分析也可以幫助我們解釋模型的預測結果,揭示模型背後的規律和因果關係,增強模型的可解釋性
- 改進的模型表現
- 減少過度擬合
- 更快的訓練與推理
- ## 增強的可解釋性
下面我們深入了解在Python中的一些特性重要性分析的方法。
特徵重要性分析方法
1、排列重要性PermutationImportance
這種方法會對每個特徵的值進行隨機排列,然後監測模型效能下降的程度。如果下降幅度更大,那就意味著該特徵更重要
from sklearn.datasets import load_breast_cancer from sklearn.ensemble import RandomForestClassifier from sklearn.inspection import permutation_importance from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt cancer = load_breast_cancer() X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, random_state=1) rf = RandomForestClassifier(n_estimators=100, random_state=1) rf.fit(X_train, y_train) baseline = rf.score(X_test, y_test) result = permutation_importance(rf, X_test, y_test, n_repeats=10, random_state=1, scoring='accuracy') importances = result.importances_mean # Visualize permutation importances plt.bar(range(len(importances)), importances) plt.xlabel('Feature Index') plt.ylabel('Permutation Importance') plt.show()

#2、內建特徵重要性(coef_或feature_importances_)
一些模型,如線性迴歸和隨機森林,可以直接輸出特徵重要性分數。這些顯示了每個特徵對最終預測的貢獻。
from sklearn.datasets import load_breast_cancer from sklearn.ensemble import RandomForestClassifier X, y = load_breast_cancer(return_X_y=True) rf = RandomForestClassifier(n_estimators=100, random_state=1) rf.fit(X, y) importances = rf.feature_importances_ # Plot importances plt.bar(range(X.shape[1]), importances) plt.xlabel('Feature Index') plt.ylabel('Feature Importance') plt.show()
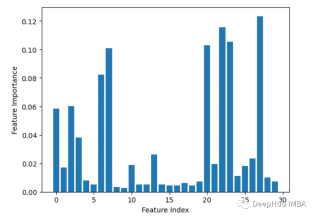
3、Leave-one-out
迭代地每次刪除一個特徵並評估準確性。
from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score import matplotlib.pyplot as plt import numpy as np # Load sample data X, y = load_breast_cancer(return_X_y=True) # Split data into train and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1) # Train a random forest model rf = RandomForestClassifier(n_estimators=100, random_state=1) rf.fit(X_train, y_train) # Get baseline accuracy on test data base_acc = accuracy_score(y_test, rf.predict(X_test)) # Initialize empty list to store importances importances = [] # Iterate over all columns and remove one at a time for i in range(X_train.shape[1]):X_temp = np.delete(X_train, i, axis=1)rf.fit(X_temp, y_train)acc = accuracy_score(y_test, rf.predict(np.delete(X_test, i, axis=1)))importances.append(base_acc - acc) # Plot importance scores plt.bar(range(len(importances)), importances) plt.show()

4、相關性分析
#需要重新寫的內容是:計算特徵與目標變數間的相關性,相關性越高的特徵越重要
import pandas as pd from sklearn.datasets import load_breast_cancer X, y = load_breast_cancer(return_X_y=True) df = pd.DataFrame(X, columns=range(30)) df['y'] = y correlations = df.corrwith(df.y).abs() correlations.sort_values(ascending=False, inplace=True) correlations.plot.bar()
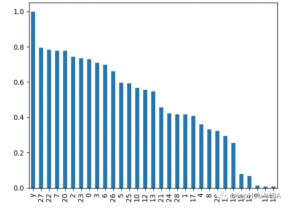
#5、遞迴特徵消除Recursive Feature Elimination
#遞歸地刪除特徵並查看它如何影響模型效能。刪除時會導致更大下降的特徵更重要。
from sklearn.ensemble import RandomForestClassifier from sklearn.feature_selection import RFE import pandas as pd from sklearn.datasets import load_breast_cancer import matplotlib.pyplot as plt X, y = load_breast_cancer(return_X_y=True) df = pd.DataFrame(X, columns=range(30)) df['y'] = y rf = RandomForestClassifier() rfe = RFE(rf, n_features_to_select=10) rfe.fit(X, y) print(rfe.ranking_)
輸出為[6 4 11 12 7 11 18 21 8 16 10 3 15 14 19 17 20 13 11 11 12 9 11 5 11]##6、XGBoost特性重要性
計算一個特徵在分割資料時的次數,這個特徵在所有樹中都被使用。更多的拆分意味著更重要
import xgboost as xgb import pandas as pd from sklearn.datasets import load_breast_cancer import matplotlib.pyplot as plt X, y = load_breast_cancer(return_X_y=True) df = pd.DataFrame(X, columns=range(30)) df['y'] = y model = xgb.XGBClassifier() model.fit(X, y) importances = model.feature_importances_ importances = pd.Series(importances, index=range(X.shape[1])) importances.plot.bar()
 7、主成分分析PCA
7、主成分分析PCA
對特徵進行主成分分析,並查看每個主成分的解釋變異數比。在前幾個組件上具有較高負載的特性更為重要。
from sklearn.decomposition import PCA import pandas as pd from sklearn.datasets import load_breast_cancer import matplotlib.pyplot as plt X, y = load_breast_cancer(return_X_y=True) df = pd.DataFrame(X, columns=range(30)) df['y'] = y pca = PCA() pca.fit(X) plt.bar(range(pca.n_components_), pca.explained_variance_ratio_) plt.xlabel('PCA components') plt.ylabel('Explained Variance')
 8、變異數分析ANOVA
8、變異數分析ANOVA
使用f_classif()得到每個特徵的變異數分析f值。 f值越高,表示特徵與目標的相關性越強。
from sklearn.feature_selection import f_classif import pandas as pd from sklearn.datasets import load_breast_cancer import matplotlib.pyplot as plt X, y = load_breast_cancer(return_X_y=True) df = pd.DataFrame(X, columns=range(30)) df['y'] = y fval = f_classif(X, y) fval = pd.Series(fval[0], index=range(X.shape[1])) fval.plot.bar()
 9、卡方檢定
9、卡方檢定
使用chi2()函數可以取得每個特徵的卡方統計資訊。分數越高的特徵越有可能與目標變數獨立
from sklearn.feature_selection import chi2 import pandas as pd from sklearn.datasets import load_breast_cancer import matplotlib.pyplot as plt X, y = load_breast_cancer(return_X_y=True) df = pd.DataFrame(X, columns=range(30)) df['y'] = y chi_scores = chi2(X, y) chi_scores = pd.Series(chi_scores[0], index=range(X.shape[1])) chi_scores.plot.bar()
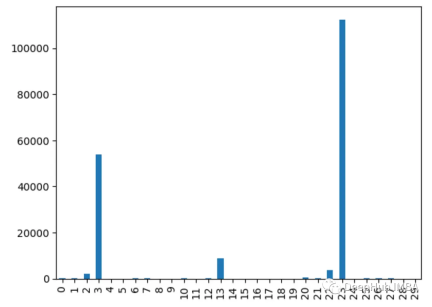
为什么不同的方法会检测到不同的特征?
由于不同的特征重要性方法,有时可以确定哪些特征是最重要的
1、他们用不同的方式衡量重要性:
有的使用不同特特征进行预测,监控精度下降
像XGBOOST或者回归模型使用内置重要性来进行特征的重要性排序
而PCA着眼于方差解释
2、不同模型有不同模型的方法:
线性模型偏向于处理线性关系,而树模型则更倾向于捕捉接近根节点的特征
3、交互作用:
有些方法可以获取特征之间的相互关系,而有些方法则不行,这会导致结果的不同
3、不稳定:
使用不同的数据子集,重要性值可能在同一方法的不同运行中有所不同,这是因为数据差异决定的
4、Hyperparameters:
通过调整超参数,例如主成分分析(PCA)组件或决策树的深度,也会对结果产生影响
所以不同的假设、偏差、数据处理和方法的可变性意味着它们并不总是在最重要的特征上保持一致。
选择特征重要性分析方法的一些最佳实践
- 尝试多种方法以获得更健壮的视图
- 聚合结果的集成方法
- 更多地关注相对顺序,而不是绝对值
- 差异并不一定意味着有问题,检查差异的原因会对数据和模型有更深入的了解
以上是九種常用的Python特徵重要性分析方法的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 AI遊戲開發通過Upheaval的Dreamer Portal進入其代理時代May 02, 2025 am 11:17 AM
AI遊戲開發通過Upheaval的Dreamer Portal進入其代理時代May 02, 2025 am 11:17 AM動盪遊戲:與AI代理商的遊戲開發徹底改變 Roupheaval是一家遊戲開發工作室,由暴風雪和黑曜石等行業巨頭的退伍軍人組成,有望用其創新的AI驅動的Platfor革新遊戲創作
 Uber想成為您的Robotaxi商店,提供商會讓他們嗎?May 02, 2025 am 11:16 AM
Uber想成為您的Robotaxi商店,提供商會讓他們嗎?May 02, 2025 am 11:16 AMUber的Robotaxi策略:自動駕駛汽車的騎車生態系統 在最近的Curbivore會議上,Uber的Richard Willder推出了他們成為Robotaxi提供商的乘車平台的策略。 利用他們在
 AI代理玩電子遊戲將改變未來的機器人May 02, 2025 am 11:15 AM
AI代理玩電子遊戲將改變未來的機器人May 02, 2025 am 11:15 AM事實證明,視頻遊戲是最先進的AI研究的寶貴測試理由,尤其是在自主代理商和現實世界機器人的開發中,甚至有可能促進人工通用情報(AGI)的追求。 一個
 創業公司工業綜合體VC 3.0和James Currier的宣言May 02, 2025 am 11:14 AM
創業公司工業綜合體VC 3.0和James Currier的宣言May 02, 2025 am 11:14 AM不斷發展的風險投資格局的影響在媒體,財務報告和日常對話中顯而易見。 但是,對投資者,初創企業和資金的具體後果經常被忽略。 風險資本3.0:範式
 Adobe在Adobe Max London 2025更新創意云和螢火蟲May 02, 2025 am 11:13 AM
Adobe在Adobe Max London 2025更新創意云和螢火蟲May 02, 2025 am 11:13 AMAdobe Max London 2025對Creative Cloud和Firefly進行了重大更新,反映了向可訪問性和生成AI的戰略轉變。 該分析結合了事件前簡報中的見解,並融合了Adobe Leadership。 (注意:Adob
 Llamacon宣布的所有元數據May 02, 2025 am 11:12 AM
Llamacon宣布的所有元數據May 02, 2025 am 11:12 AMMeta的Llamacon公告展示了一項綜合的AI策略,旨在直接與OpenAI等封閉的AI系統競爭,同時為其開源模型創建了新的收入流。 這個多方面的方法目標bo
 關於AI僅僅是普通技術的主張的釀造爭議May 02, 2025 am 11:10 AM
關於AI僅僅是普通技術的主張的釀造爭議May 02, 2025 am 11:10 AM人工智能領域對這一論斷存在嚴重分歧。一些人堅稱,是時候揭露“皇帝的新衣”了,而另一些人則強烈反對人工智能僅僅是普通技術的觀點。 讓我們來探討一下。 對這一創新性人工智能突破的分析,是我持續撰寫的福布斯專欄文章的一部分,該專欄涵蓋人工智能領域的最新進展,包括識別和解釋各種有影響力的人工智能複雜性(請點擊此處查看鏈接)。 人工智能作為普通技術 首先,需要一些基本知識來為這場重要的討論奠定基礎。 目前有大量的研究致力於進一步發展人工智能。總目標是實現人工通用智能(AGI)甚至可能實現人工超級智能(AS
 模型公民,為什麼AI值是下一個業務碼May 02, 2025 am 11:09 AM
模型公民,為什麼AI值是下一個業務碼May 02, 2025 am 11:09 AM公司AI模型的有效性現在是一個關鍵的性能指標。自AI BOOM以來,從編寫生日邀請到編寫軟件代碼的所有事物都將生成AI使用。 這導致了語言mod的擴散


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

Dreamweaver CS6
視覺化網頁開發工具

mPDF
mPDF是一個PHP庫,可以從UTF-8編碼的HTML產生PDF檔案。原作者Ian Back編寫mPDF以從他的網站上「即時」輸出PDF文件,並處理不同的語言。與原始腳本如HTML2FPDF相比,它的速度較慢,並且在使用Unicode字體時產生的檔案較大,但支援CSS樣式等,並進行了大量增強。支援幾乎所有語言,包括RTL(阿拉伯語和希伯來語)和CJK(中日韓)。支援嵌套的區塊級元素(如P、DIV),

禪工作室 13.0.1
強大的PHP整合開發環境

SublimeText3 Linux新版
SublimeText3 Linux最新版

ZendStudio 13.5.1 Mac
強大的PHP整合開發環境

