
H100推理飆升8倍!英偉達官宣開源TensorRT-LLM,支援10+模型

- 王林轉載
- 2023-09-10 16:41:011681瀏覽
「GPU貧民」即將告別困境!
剛剛,英偉達發布了一款名為TensorRT-LLM的開源軟體,可以加速在H100上運行的大型語言模型的推理過程

#那麼,具體能提升多少倍?
在新增了TensorRT-LLM及其一系列最佳化功能後(包含In-Flight批次),模型總吞吐量提升8倍。
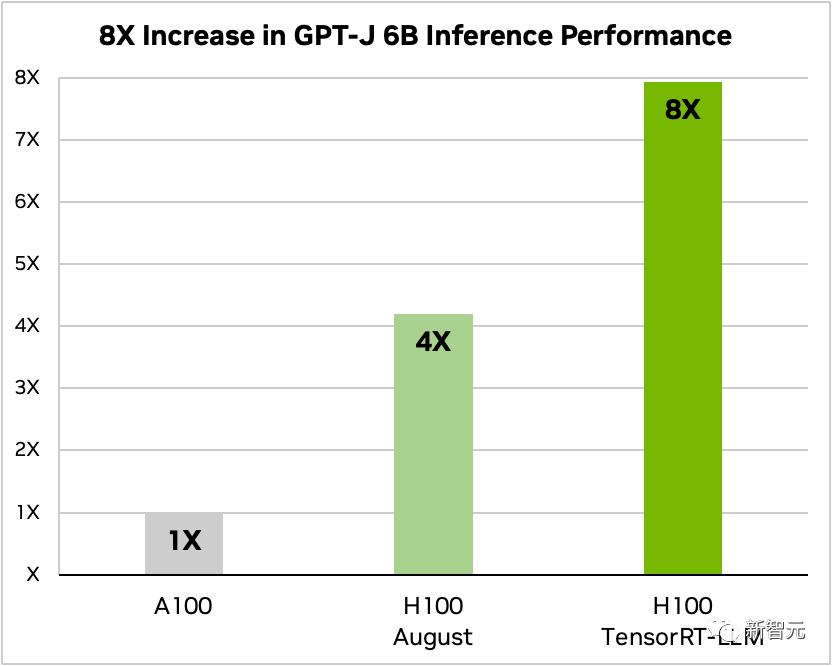
使用與不使用TensorRT-LLM的GPT-J-6B A100與H100的比較
#另外,以Llama 2為例,相較於獨立使用A100,TensorRT-LLM能夠將推理表現提升4.6倍
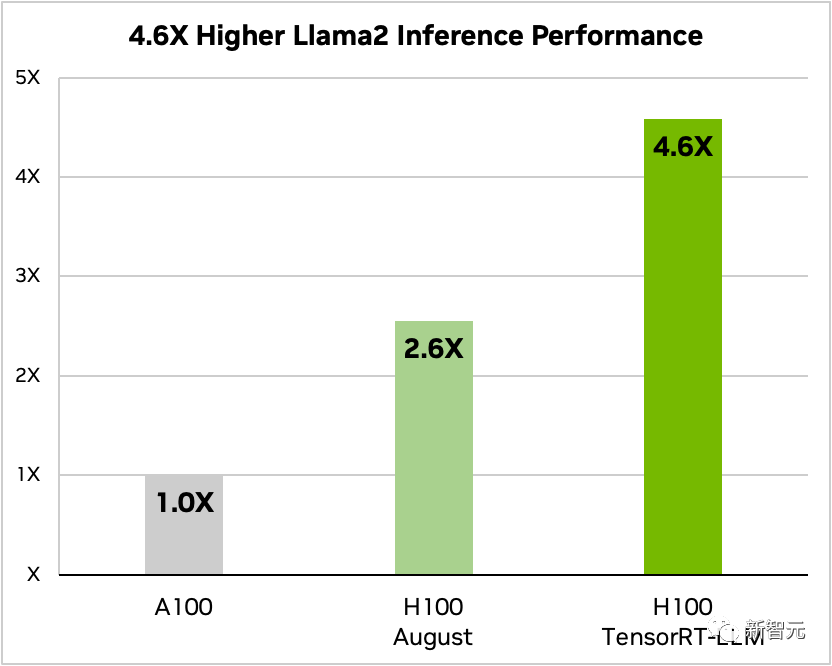
對比Llama 2 70B 、A100和H100在使用和不使用TensorRT-LLM的情況下的比較
##網友表示,超強H100,再結合上TensorRT-LLM,無疑將徹底改變大型語言模型推理現狀!

目前,由於大模型有著巨大的參數規模,使得「部署和推理」難度和成本一直居高不下。
英偉達開發的TensorRT-LLM旨在透過GPU來顯著提高LLM的吞吐量,並降低成本

具體而言,TensorRT-LLM將TensorRT的深度學習編譯器、FasterTransformer的最佳化核心、預處理和後處理以及多GPU/多節點通訊封裝在一個簡單的開源Python API中
英偉達對FasterTransformer進行了進一步的增強,使其成為一個產品化的解決方案。
可見,TensorRT-LLM提供了一個易用、開源和模組化的Python應用程式介面。
不需要深入了解C 或CUDA專業知識的碼農們,可以部署、運行和調試各種大型語言模型,並且能夠獲得卓越的性能表現,以及快速定制化的功能

根據英偉達官方部落格的報道,TensorRT-LLM採用了四種方法來提升Nvidia GPU上的LLM推理效能
首先,為目前10 大模型,引入TensorRT-LLM,讓開發者們能夠立即運作。
其次,TensorRT-LLM作為一個開源軟體庫,允許LLM在多個GPU和多個GPU伺服器上同時進行推理。
這些伺服器分別通過,英偉達的NVLink和InfiniBand互連連接。
第三點是關於「機內批次」,這是一項全新的調度技術,它允許不同模型的任務獨立於其他任務進入和退出GPU
#最後,TensorRT-LLM經過最佳化,可以利用H100 Transformer Engine來降低模型推理時的記憶體佔用和延遲。
下面我們來詳細看TensorRT-LLM是如何提升模型表現的
支援豐富LLM生態TensorRT -LLM為開源模型生態提供了出色的支援
需要重寫的內容是:具有最大規模和最先進的語言模型,例如Meta推出的Llama 2-70B,需要多個GPU協同工作才能即時提供回應
以前,要實現LLM推理的最佳效能,開發人員必須手動重寫AI模型,並將其分解成多個片段,然後在GPU之間進行協調執行

TensorRT-LLM使用張量並行技術,將權重矩陣分配到各個裝置上,從而簡化了這個過程,可以實現大規模高效推理
每個模型可以在透過NVLink連接的多個GPU和多個伺服器上並行運行,無需開發人員幹預或模型變更。
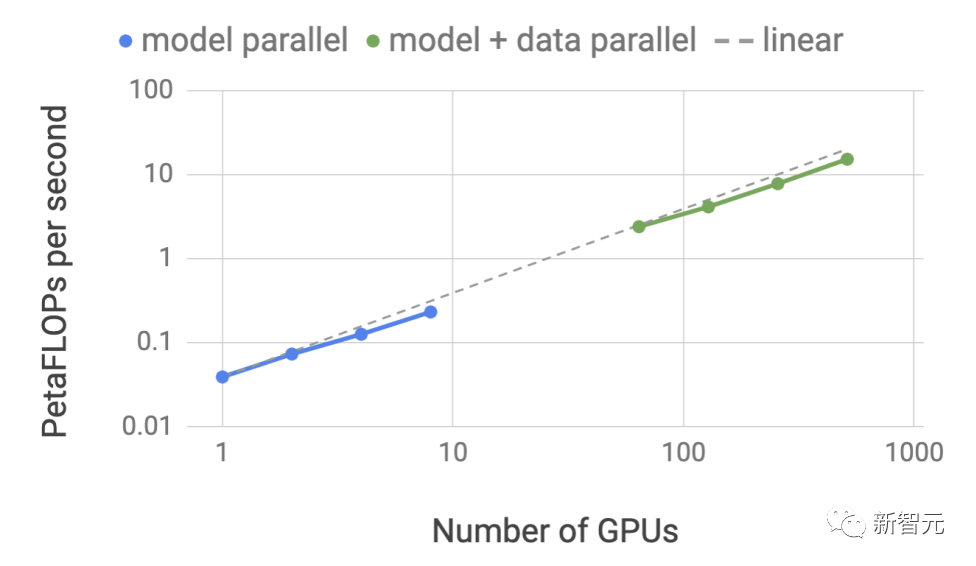
隨著新模型和模型架構的推出,開發人員可以使用TensorRT-LLM中開源的最新NVIDIA AI核心(Kernal)來優化模型
需要進行改寫的內容是:支援的核心融合(Kernal Fusion)包括最新的FlashAttention實現,以及用於GPT模型執行的上下文和生成階段的掩碼多頭注意力等
此外,TensorRT-LLM還包括了目前流行的許多大語言模型的完全最佳化、可立即運行的版本。
這些模型包括Meta Llama 2、OpenAI GPT-2和GPT-3、Falcon、Mosaic MPT、BLOOM等十多個。所有這些模型都可以使用簡單易用的TensorRT-LLM Python API來呼叫
這些功能可幫助開發人員更快、更準確地建立客製化的大語言模型,以滿足各行各業的不同需求。
In-flight批次
現在現今大型語言模型的用途極為廣泛。
一個模型可以同時用於多種看起來完全不同的任務——從聊天機器人中的簡單問答回應,到文件摘要或長程式碼區塊的生成,工作負載是高度動態的,輸出大小需要滿足不同數量級任務的需求。
任務的多樣性可能會導致難以有效地批次請求和進行高效並行執行,可能會導致某些請求比其他請求更早完成。

為了管理這些動態負載,TensorRT-LLM包含一種稱為「In-flight批次」的最佳化調度技術。
大語言模型的核心原理在於,整個文字產生過程可以透過模型的多次迭代來實現
透過in flight批次處理,TensorRT-LLM運行時會立即從批次中釋放已完成的序列,而不是等待整個批次完成後再繼續處理下一組請求。
在執行新請求時,上一批尚未完成的其他請求仍在處理中。
透過進行機上批次處理和進行額外的核心級最佳化,可以提高GPU的利用率,從而使得H100上LLM的實際請求基準的吞吐量至少增加一倍
使用FP 8的H100 Transformer引擎
TensorRT-LLM也提供了一個名為H100 Transformer Engine的功能,能有效降低大模型推理時的記憶體消耗與延遲。
因為LLM包含數十億個模型權重和激活函數,通常用FP16或BF16值進行訓練和表示,每個值佔用16位元記憶體。
然而,在推理時,大多數模型可以使用量化(Quantization)技術以較低精度有效表示,例如8位甚至4位整數(INT8或 INT4)。
量化(Quantization)是在不犧牲準確性的情況下降低模型權重和啟動精確度的過程。使用較低的精度意味著每個參數較小,並且模型在GPU記憶體中佔用的空間較小。

這樣做可以使用相同的硬體對更大的模型進行推理,同時在執行過程中減少在記憶體操作上的時間消耗
透過H100 Transformer Engine技術,配合TensorRT-LLM的H100 GPU讓戶能夠輕鬆地將模型權重轉換為新的FP8格式,並能自動編譯模型以利用最佳化後的FP8內核。
而且這個過程不需要任何的程式碼! H100引入的FP8資料格式使開發人員能夠量化他們的模型並從大幅減少記憶體消耗,而且不會降低模型的準確性。
與INT8或INT4等其他資料格式相比,FP8量化保留了更高的精度,同時實現了最快的效能,並且實現起來最為方便。 與其他資料格式(如INT8或INT4)相比,FP8量化保留了更高的精度,同時實現了最快的效能,並且實現起來最為方便
如何取得TensorRT-LLM
儘管TensorRT-LLM尚未正式發布,但用戶現在已經可以提前體驗了
申請連結如下:
https://developer.nvidia.com/tensorrt-llm-early-access/join
英偉達也說會將TensorRT-LLM很快整合到NVIDIA NeMo框架中。
這個框架是最近由英偉達推出的AI Enterprise的組成部分,為企業客戶提供了一個安全、穩定、可管理性極強的企業級AI軟體平台
開發人員和研究人員可以透過英偉達NGC上的NeMo框架或GitHub上的專案來存取TensorRT-LLM
但是需要注意的是,使用者必須註冊英偉達開發者計畫才能申請搶先體驗版本。
網友熱議
Reddit上的使用者對TensorRT-LLM的發布進行了激烈的討論
難以想像專門針對LLM對硬體做出最佳化之後,效果將會有多大的提升。

但也有網友認為,這東西的意義就是幫助老黃賣更多的H100。
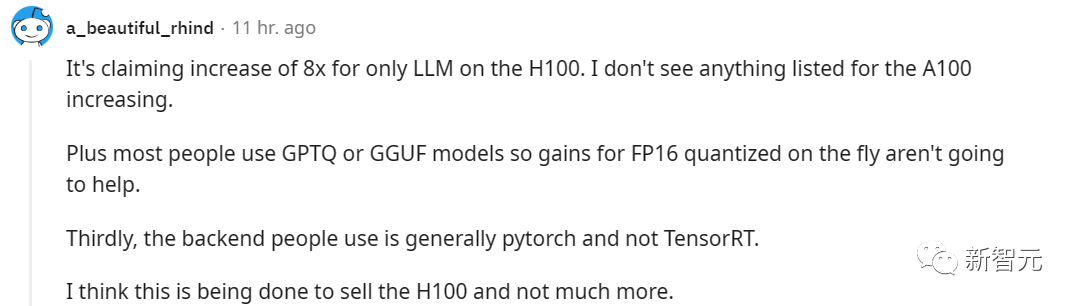
有些網友對此持不同意見,他們認為Tensor RT對於本地部署深度學習的使用者也是有幫助的。只要擁有RTX GPU,將來在類似的產品上也有可能受益

#從更宏觀的角度來看,也許對於LLM而言,會出現一系列專門針對硬體層級的最佳化措施,甚至可能會出現專為LLM設計的硬體來提升其效能。這種情況在許多流行的應用中已經出現過,LLM也不會例外
以上是H100推理飆升8倍!英偉達官宣開源TensorRT-LLM,支援10+模型的詳細內容。更多資訊請關注PHP中文網其他相關文章!