
用BigDL-LLM 即刻加速百億級參數LLM推理

- 王林轉載
- 2023-09-05 13:49:041364瀏覽
我們正邁入一個由大語言模型(Large Language Model, LLM)驅動的AI 新時代,LLM在諸如客戶服務、虛擬助理、內容創作、程式設計輔助等各類應用中正發揮著越來越重要的作用。
然而,隨著LLM 規模不斷擴大,運行大模型所需的資源消耗也越來越大,導致其運作也越來越慢,這給了AI 應用開發者相當大的挑戰。
為此,英特爾最近推出了一個名為BigDL-LLM[1]的大模型開源函式庫,可協助AI 開發者和研究者在英特爾® 平台上加速最佳化大語言模型,提升大語言模式在英特爾® 平台上的使用體驗。

以下就展示了使用BigDL-LLM 加速過的330 億參數的大語言模型Vicuna-33b-v1.3[2]在一台搭載英特爾® 至強® 鉑金8468 處理器的伺服器上運作的即時效果。
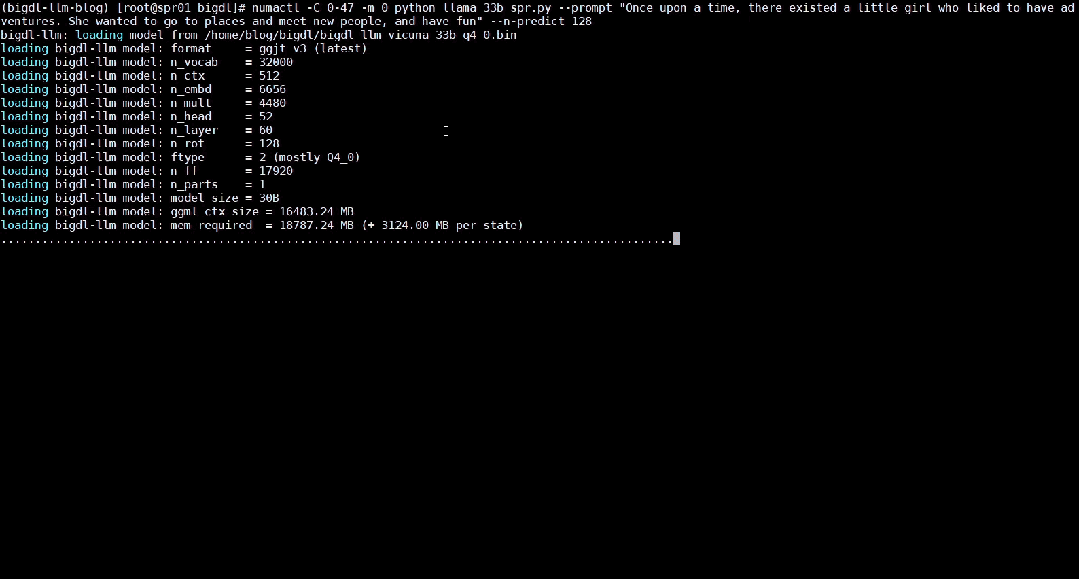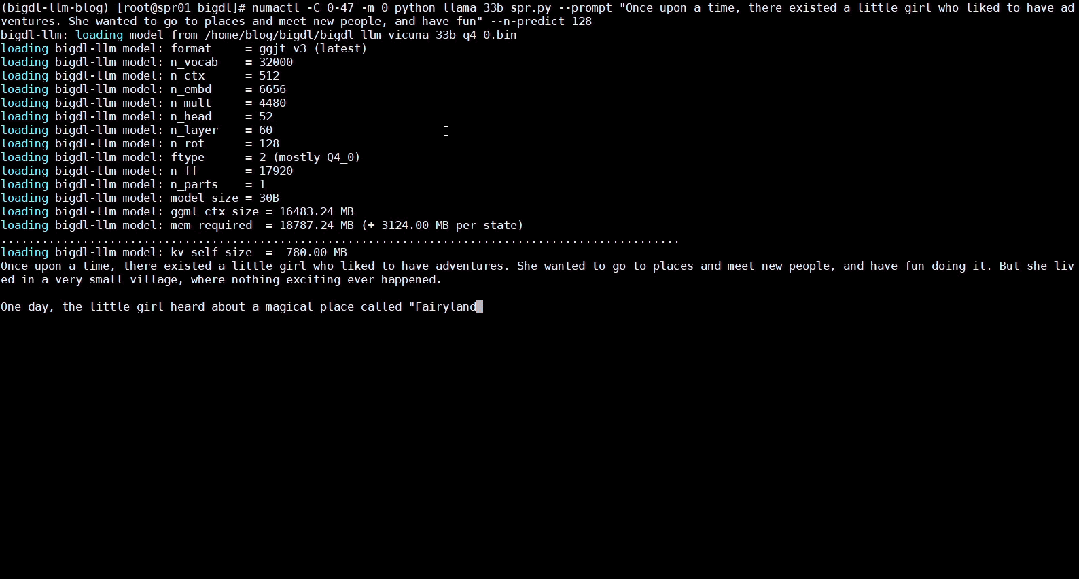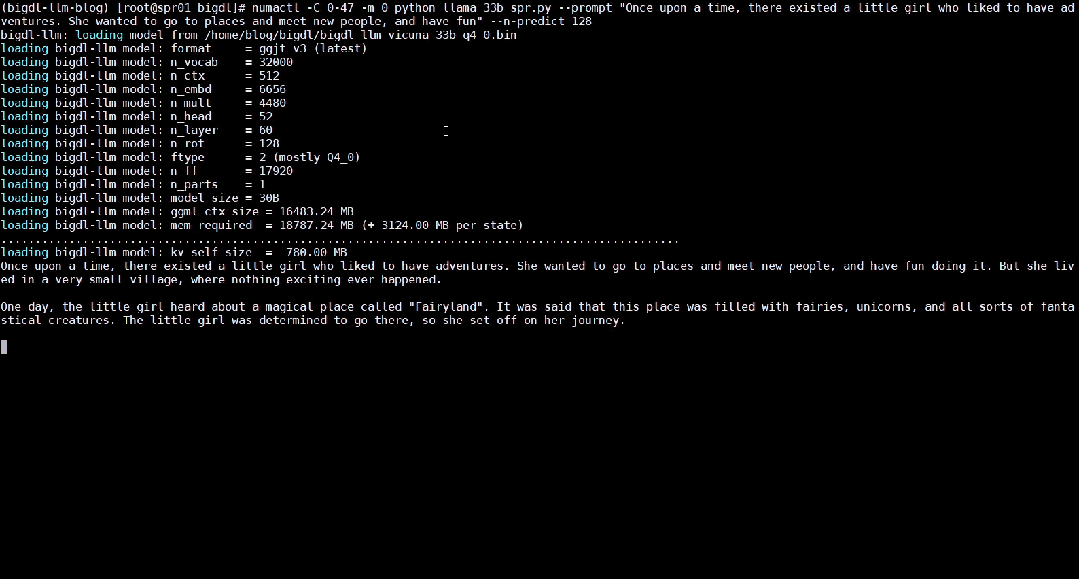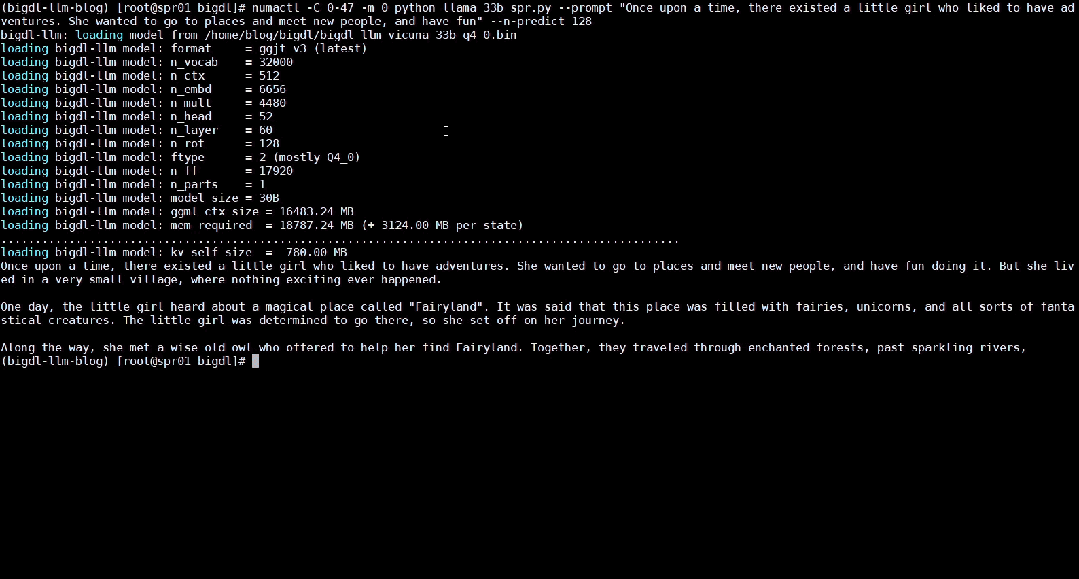
△在一台搭載英特爾® 至強® 鉑金8468 處理器的伺服器上運行330 億參數大語言模型的實際速度(即時錄影)
BigDL-LLM:Intel® 平台上的開源大語言模型加速函式庫
BigDL-LLM 是一個專注於最佳化和加速大型語言模型的開源庫,它是BigDL 的一部分,並遵循Apache 2.0 許可證發布
它提供了各種低精度優化(例如INT4/INT5/INT8),並可利用多種英特爾® CPU整合的硬體加速技術(AVX/VNNI/AMX 等)和最新的軟體最佳化,來賦能大語言模型在英特爾® 平台上實現更有效率的最佳化和更快速的運行。
BigDL-LLM 的一大重要特性是:對基於Hugging Face Transformers API 的模型,只需改動一行程式碼即可對模型進行加速,理論上可以支援運行任何 Transformers 模型,這對熟悉Transformers API 的開發者非常友善。
除了 Transformers API,許多人也會使用 LangChain 來開發大語言模型應用。
為此,BigDL-LLM 也提供便於使用的LangChain 的整合[3],讓開發者能夠輕鬆使用BigDL-LLM 來開發新應用或遷移現有的、基於Transformers API 或LangChain API 的應用。
此外,對於一般的 PyTorch 大語言模型(沒有使用 Transformer 或 LangChain API 的模型),也可使用 BigDL-LLM optimize_model API 一鍵加速來提升效能。詳情請參閱 GitHub README[4]以及官方文件[5]。
BigDL-LLM 也提供了大量常用開源LLM的加速範例(e.g. 使用Transformers API 的範例[6]和使用LangChain API 的範例[7] ,以及教學(包括配套jupyter notebooks)[8] ,方便開發者快速上手嘗試。
安裝和使用:簡單的安裝過程和易用的API 介面
安裝BigDL-LLM 非常方便,只需執行以下命令即可:
pip install --pre --upgrade bigdl-llm[all]
#△若程式碼顯示不全,請左右滑動
使用BigDL-LLM對大模型進行加速也是非常容易的(這裡僅用Transformers 風格API 進行舉例)。
使用BigDL-LLM Transformer 風格API 對模型加速,只需要改變模型載入部分,後續使用過程與原生Transformers 完全一致。
而用BigDL-LLM API 載入模型的方式與Transformers API 也幾乎一致——用戶只需要更改import,在from_pretrained 參數中設定 load_in_4bit=True 即可。
BigDL-LLM將在模型載入過程中進行4位低精確度量化,並在後續的推理過程中利用各種軟硬體加速技術進行最佳化
#Load Hugging Face Transformers model with INT4 optimizationsfrom bigdl.llm. transformers import AutoModelForCausalLMmodel = AutoModelForCausalLM.from_pretrained('/path/to/model/', load_in_4bit=True)
△#若程式碼顯示不全,請左右滑動
#示例:快速实现一个基于大语言模型的语音助手应用
下文将以 LLM 常见应用场景“语音助手”为例,展示采用 BigDL-LLM 快速实现 LLM 应用的案例。通常情况下,语音助手应用的工作流程分为以下两个部分:
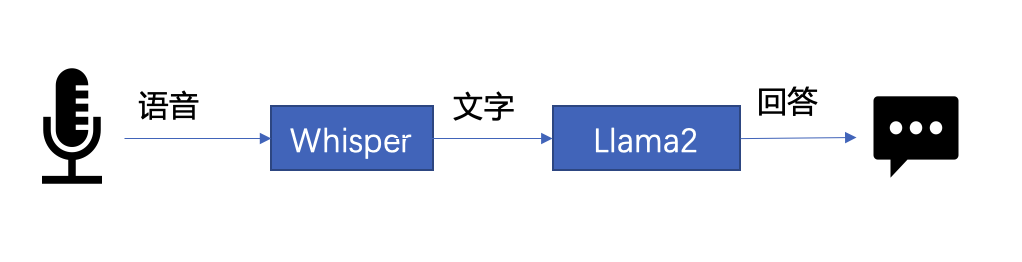
△图 1. 语音助手工作流程示意
- 语音识别——使用语音识别模型(本示例采用了 Whisper 模型[9] )将用户的语音转换为文本;
- 文本生成——将 1 中输出的文本作为提示语 (prompt),使用一个大语言模型(本示例采用了 Llama2[10] )生成回复。
以下是本文使用 BigDL-LLM 和 LangChain[11] 来搭建语音助手应用的过程:
在语音识别阶段:第一步,加载预处理器 processor 和语音识别模型 recog_model。本示例中使用的识别模型 Whisper 是一个 Transformers 模型。
只需使用 BigDL-LLM 中的 AutoModelForSpeechSeq2Seq 并设置参数 load_in_4bit=True,就能够以 INT4 精度加载并加速这一模型,从而显著缩短模型推理用时。
#processor = WhisperProcessor .from_pretrained(recog_model_path)recog_model = AutoModelForSpeechSeq2Seq .from_pretrained(recog_model_path, load_in_4bit=True)
△若代码显示不全,请左右滑动
第二步,进行语音识别。首先使用处理器从输入语音中提取输入特征,然后使用识别模型预测 token,并再次使用处理器将 token 解码为自然语言文本。
input_features = processor(frame_data,sampling_rate=audio.sample_rate,return_tensor=“pt”).input_featurespredicted_ids = recogn_model.generate(input_features, forced_decoder_ids=forced_decoder_ids)text = processor.batch_decode(predicted_ids, skip_special_tokens=True)[0]
△若代码显示不全,请左右滑动
在文本生成阶段,首先使用 BigDL-LLM 的 TransformersLLM API 创建一个 LangChain 语言模型(TransformersLLM 是在 BigDL-LLM 中定义的语言链 LLM 集成)。
可以使用这个 API 来加载 Hugging Face Transformers 的任何模型
llm = TransformersLLM . from_model_id(model_id=llm_model_path,model_kwargs={"temperature": 0, "max_length": args.max_length, "trust_remote_code": True},)
△若代码显示不全,请左右滑动
然后,创建一个正常的对话链 LLMChain,并将已经创建的 llm 设置为输入参数。
# The following code is complete the same as the use-casevoiceassistant_chain = LLMChain(llm=llm, prompt=prompt,verbose=True,memory=ConversationBufferWindowMemory(k=2),)
△若代码显示不全,请左右滑动
以下代码将使用一个链条来记录所有对话历史,并将其适当地格式化为大型语言模型的输入。这样,我们可以生成合适的回复。只需将识别模型生成的文本作为 "human_input" 输入即可。代码如下:
response_text = voiceassistant_chain .predict(human_input=text, stop=”\n\n”)
△若代码显示不全,请左右滑动
最后,将语音识别和文本生成步骤放入循环中,即可在多轮对话中与该“语音助手”交谈。您可访问底部 [12] 链接,查看完整的示例代码,并使用自己的电脑进行尝试。快用 BigDL-LLM 来快速搭建自己的语音助手吧!
作者简介
黄晟盛是英特尔公司的资深架构师,黄凯是英特尔公司的AI框架工程师,戴金权是英特尔院士、大数据技术全球CTO和BigDL项目的创始人,他们都从事着与大数据和AI相关的工作
以上是用BigDL-LLM 即刻加速百億級參數LLM推理的詳細內容。更多資訊請關注PHP中文網其他相關文章!