
上週,XX保險面試,涼了! ! !
- Java后端技术全栈轉載
- 2023-08-25 15:44:191668瀏覽
上週,一位群組裡的朋友去平安保險面試了,結果有些遺憾,蠻可惜的,但希望你不要氣餒,正如你所說的,面試中遇到的問題,基本上都是可以透過背部面試題解決的,所以請加油!
另外,有問題歡迎隨時找我探討,共同進步。
不扯遠了,咱們進入主題,以下是這位同學整理的技術面試題和參考答案。
Java中有哪些執行緒安全的類別?
Vector、Hashtable、StringBuffer。都是在其方法上加了同步鎖來實現線程安全的。
另外,還有JUC套件下所有的集合類別
ArrayBlockingQueue 、ConcurrentHashMap、ConcurrentLinkedQueue、ConcurrentLinkedDeque等,這些也是線程安全的。
幸好這麼回答就算結束了,面試官也沒再問了,不然JUC下的這幾個我真回答不上來。
Java建立物件有幾種方式?
這個問題相對還是簡單的,能說上個123應該都沒問題了。
Java中提供了以下四種建立物件的方式:
new建立新物件 透過反射機制 #採用clone機制 - #透過序列化機制
Object 有哪些常用方法?
這個問題,回答的不是很好,當時只記得toString、equals、hashCode、wait、notify、notifyAll。其他的沒有想起來。面試官還是不斷點頭,感覺是應該還好。
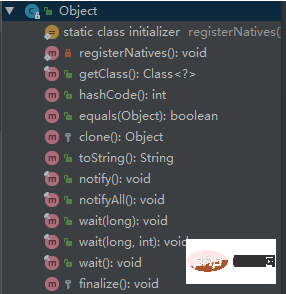
#下面是對應方法的意義。
clone 方法###保護方法,實作物件的淺複製,只有實作了Cloneable 介面才可以呼叫該方法,否則拋出CloneNotSupportedException 異常,深拷貝也需要實作Cloneable,同時其成員變數為引用型別的也需要實作Cloneable,然後重寫clone 方法。 ###finalize 方法
該方法和垃圾收集器有關係,判斷物件是否可以被回收的最後一步就是判斷是否重寫了此方法。
equals 方法
該方法使用頻率非常高。一般 equals 和 == 是不一樣的,但 Object 中兩者是一樣的。子類別一般都要重寫這個方法。
hashCode 方法
該方法用於哈希查找,重寫了equals 方法一般都要重寫hashCode 方法,這個方法在一些具有哈希功能的Collection 中用到。
一般必須滿足 obj1.equals(obj2)==true。可以推出 obj1.hashCode()==obj2.hashCode(),但 hashCode 相等不一定就滿足 equals。不過為了提高效率,應該盡量讓上面兩個條件接近等價。
JDK 1.6、1.7 預設是傳回隨機數; JDK 1.8 預設是透過和目前執行緒有關的一個隨機數三個決定值,運用Marsaglia's xorshift scheme 隨機數值演算法得到的一個隨機數。
wait 方法
配合synchronized 使用,wait 方法是讓目前執行緒等待該物件的鎖,目前執行緒必須是該物件的擁有者,也就是具有該物件的鎖。 wait() 方法一直等待,直到獲得鎖定或中斷。 wait(long timeout) 設定一個超時間隔,如果在規定時間內沒有取得鎖就回傳。
呼叫該方法後當前執行緒進入睡眠狀態,直到以下事件發生。
其他執行緒呼叫了該物件的notify 方法; #其他執行緒呼叫了該物件的notifyAll 方法; 其他執行緒呼叫了interrupt 中斷該執行緒; 時間間隔到了。
此時該執行緒就可以被調度了,如果是中斷的話就拋出一個 InterruptedException 例外。
notify 方法
配合synchronized 使用,該方法喚醒在該物件上等待佇列中的某個執行緒(同步佇列中的執行緒是給搶佔CPU 的線程,等待佇列中的線程指的是等待喚醒的線程)。
notifyAll 方法
配合 synchronized 使用,該方法喚醒在該物件上等待佇列中的所有執行緒。
hashCode方法和equals方法有什麼關係
#有點連環炮的意思了,問到這裡,感覺面試官有些懷疑我的基礎了,但這個問題還是能回答的。
如果a.equals(b)回傳“true”,那麼a和b的hashCode()必須相等。
如果a.equals(b)回傳“false”,那麼a和b的hashCode()有可能相等,也有可能不等。
hashcode的作用
真的是連續砲,一個接一個問,回答的不是很理想,但也是扯到一些。
Java的集合有兩類,一類是List,還有一類是Set。前者有序可重複,後者無序不重複。當我們在set中插入的時候怎麼判斷是否已經存在該元素呢,可以透過equals方法。但是如果元素太多,用這樣的方法就會比較滿。
於是有人發明了雜湊演算法來提高集合中尋找元素的效率。這種方式將集合分成若干個儲存區域,每個物件可以計算出一個雜湊碼,可以將雜湊碼分組,每組分別對應某個儲存區域,根據一個物件的雜湊碼就可以確定該物件應該儲存的那個區域。
hashCode方法可以這樣理解:它傳回的就是根據物件的記憶體位址換算出的一個值。這樣一來,當集合要加入新的元素時,先呼叫這個元素的hashCode方法,就一下子能定位到它應該放置的物理位置。如果這個位置上沒有元素,它就可以直接儲存在這個位置上,不用再進行任何比較了;如果這個位置上已經有元素了,就調用它的equals方法與新元素進行比較,相同的話就不存了,不相同就散列其它的位址。這樣一來實際呼叫equals方法的次數就大大降低了,幾乎只需要一兩次。
說說Spring Boot的自動組裝原理
#這個問題,也是因為我履歷表上寫了
Spring Boot,所以被問到也是正常的,不過我面試前還是看過一些,回答的還行,面試官說差不多是這個意思。
在Spring Boot中有個很關鍵的註解@SpringBootApplication ,其中這個註解又可以等同於
- #@SpringBootConfiguration
- @EnableAutoConfiguration
- @ComponentScan
其中@EnableAutoConfiguration是關鍵(啟用自動設定),內部實際上就去載入META-INF/spring.factories檔案的訊息,然後篩選出以 EnableAutoConfiguration為key的數據,載入到IOC容器中,實現自動設定功能!
資料庫交易的隔離等級有哪些?
這種問題,背背八股文,網路上一堆。
資料庫交易的隔離等級有4種,由低到高分別為Read uncommitted 、Read committed、Repeatable read 、Serializable。
未提交讀取( READ UNCOMMITTED):在這個隔離等級下,其他交易可以看到本交易沒有提交的部分修改,因此會造成髒讀的問題(讀取到了其他交易未提交的部分,而之後該事務進行了回滾);#已提交讀( READ COMMITTED#):其他交易只能讀取到本事務已經提交的部分,這個隔離等級有不可重複讀的問題,在同一個事務內的兩次讀取,拿到的結果竟然不一樣,因為另外一個事務對資料進行了修改;"-
可重複讀取( REPEATABLE READ)。可重複讀取隔離等級解決了上面不可重複讀取的問題,但仍有一個新問題,就是幻讀。當你讀取id> 10 的數據行時,對涉及到的所有行加上了讀鎖,此時例外一個事務新插入了一條id=11的數據,因為是新插入的,所以不會觸發上面的鎖的排斥,那麼進行本事務進行下一次的查詢時會發現有一條id=11的數據,而上次的查詢操作並沒有獲取到,再進行插入就會有主鍵衝突的問題; 可串行化( SERIALIZABLE)。這是最高的隔離級別,可以解決上面提到的所有問題,因為他強制將所以的操作串行執行,這會導致並發效能極速下降,因此也不是很常用。
說說你對MySQL中索引的理解
這個問題,還好,知道多少說多少。看每個人準備情況,我當時準備的還行。自我感覺回答的還行,我把索引的優缺點一併回答上來了。
索引是一种数据结构,使得Mysql能够高效获取数据的数据结构。更通俗的说,数据库索引好比是一本书前面的目录,能加快数据库的查询速度。
优点
可以保证数据库表中每一行的数据的唯一性 可以大大加快数据的索引速度 加速表与表之间的连接,特别是在实现数据的参考完整性方面特别有意义 在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间 通过使用索引,可以在时间查询的过程中,使用优化隐藏器,提高系统的性能
缺点
创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加 索引需要占物理空间,除了数据表占用数据空间之外,每一个索引还要占用一定的物理空间,如果需要建立聚簇索引,那么需要占用的空间会更大 以表中的数据进行增、删、改的时候,索引也要动态的维护,这就降低了整数的维护速度
熟悉哪些SQL优化方法?
这部分是看了田哥的知识星球中《java程序员必备MySQL数据库知识》中学到的,也只是说了一部分,因为田哥整理的非常多,对不住了,兄弟记性不好。
1、查詢語句中不要使用select *
2、盡量減少子查詢,使用關聯查詢(left join,right join,inner join)取代
#3、減少使用IN或NOT IN ,使用exists,not exists或關聯查詢語句替代
4、or 的查詢盡量用union或union all 取代(在確認沒有重複資料或不用剔除重複資料時,union all會更好)
5、應盡量避免在where 子句中使用!=或a8093152e673feb7aba1828c43532094操作符,否則將引擎放棄使用索引而進行全表掃描。
6、應盡量避免在where 子句中對欄位進行null 值判斷,否則將導致引擎放棄使用索引而進行全表掃描,如:select id from t where num is null 可以在num上設定預設值0,確保表中num列沒有null值,然後這樣查詢:select id from t where num=0
在MySQL 中一條查詢SQL 是如何執行的?
NND,這麼喜歡問MySQL,這個問題還真把我難道了,瞎說一通,面試官都有些不耐煩了。回來我去田哥知識星球翻了一下,果然又是接近一模一樣的面試題,怪我還沒準備好。
例如下面這條SQL語句(面試官現場給的SQL):
select 字段1,字段2 from 表 where id=996
取得連結,使用使用到MySQL 中的連接器。 查詢快取,key 為 SQL 語句,value 為查詢結果,如果查到就直接回傳。不建議使用次緩存,在 MySQL 8.0 版本已經將查詢快取刪除,也就是說 MySQL 8.0 版本後不存在此功能。 分析器,分為詞法分析與文法分析。此階段只是做一些 SQL 解析,語法校驗。所以一般文法錯誤在此階段。 優化器,是在表裡有多個索引的時候,決定使用哪個索引;或一個語句中存在多個表關聯的時候(join) ,決定各表的連接順序。 執行器,透過分析器讓 SQL 知道你要幹啥,透過優化器知道該怎麼做,於是開始執行語句。執行語句的時候還要判斷是否具備此權限,沒有權限就直接返回提示沒有權限的錯誤;有權限則打開表,根據表的引擎定義,去使用這個引擎提供的接口,獲取這個表的第一行,判斷id 是都等於1。如果是,直接回傳;如果不是繼續呼叫引擎介面去下一行,重複相同的判斷,直到取到這個表的最後一行,最後回傳。
我在想,996是什麼意義,是你們公司就是996嗎?還是隨口一說
JVM中堆疊與堆疊有什麼不同?
這個還好,稍微熟悉點JVM知識,都能回答。田哥整理的JVM運行時資料區的講解非常nice。
二者本質差異:堆疊是執行緒私有,而堆疊是執行緒共享的。
棧是運行時單位,代表著邏輯,一個棧對應著一個線程,內含基本資料型別和堆中物件引用,所在區域連續,沒有碎片;
堆是存儲單位,代表著數據,可被多個堆疊共享(包括成員中基本數據類型、引用和引用物件),所在區域不連續,會有碎片。
1)、功能不同
堆疊記憶體用來儲存局部變數和方法調用,而堆疊記憶體用來儲存Java中的物件。無論是成員變量,局部變量,還是類別變量,它們指向的物件都儲存在堆記憶體中。
2)、共享性不同
堆疊記憶體是線程私有的。堆記憶體是所有執行緒共有的。
3)、異常錯誤不同
如果堆疊記憶體或堆疊記憶體不足都會拋出例外。
堆疊空間不足:java.lang.StackOverFlowError。
堆空間不足:java.lang.OutOfMemoryError。
4)、空間大小
#堆疊的空間大小遠小於堆疊的。
熟悉類別載入機制嗎?
這都是背背面試題就差不多了
JVM類別載入分為5個過程:加載,驗證,準備,解析,初始化,使用,卸載,如下圖所示:
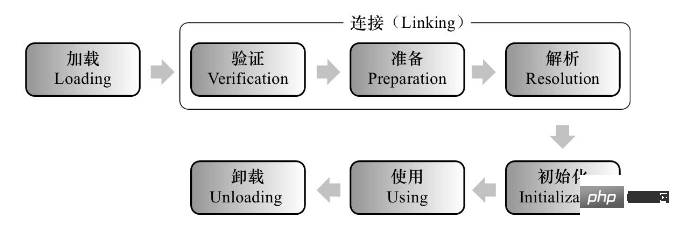
下面來看看加載,驗證,準備,解析,初始化這5個過程的具體動作。
載入
載入主要是將.class檔案(不一定是.class。可以是ZIP包,網路中取得)中的二進位字節流讀入到JVM中。在載入階段,JVM需要完成3件事:1)透過類別的全限定名取得該類別的二進位位元組流;2)將位元組流所代表的靜態儲存結構轉換為方法區的執行時間資料結構; 3)在記憶體中產生一個該類別的java.lang.Class對象,作為方法區這個類別的各種資料的存取入口。
連接
驗證
#驗證是連接階段的第一步,主要確保加載進來的位元組流符合JVM規範。驗證階段會完成以下4個階段的檢驗動作:1)檔案格式驗證2)元資料驗證(是否符合Java語言規格) 3)字節碼驗證(確定程式語意合法,符合邏輯) 4)符號參考驗證(確保下一步的解析能正常執行)
準備
主要為靜態變數在方法區分配內存,並設定預設初始值。
解析
是虛擬機器將常數池內的符號參考替換為直接引用的過程。
初始化
初始化階段是類別載入過程的最後一步,主要是根據程式中的賦值語句主動為類別變數賦值。註:1)當有父類別且父類別為初始化的時候,先去初始化父類別;2)再進行子類別初始化語句。
能夠觸發條件 Full GC 有哪些?
有點跳躍性,還以為會問垃圾回收演算法之類,結果居然問到這裡了。這個還沒準備好,隨便說了兩個,明顯感覺到面試官很不滿意,哎,就這樣吧,回去好好準備吧。
通常觸發Full GC的場景有如下5種場景:
(1)呼叫System.gc時,系統建議執行Full GC ,但不必然執行
(2)老年代空間不足
(3)方法去空間不足
(4)經由Minor GC後進入老年代的平均大小> 老年代的可用記憶體
(5)由Eden區、From Space區向To Space區複製時,物件大小大於To Space可用內存,則把該物件轉存到老年代,且老年代的可用內存小於該物件大小。即老年代無法存放下新年代過度到老年代的物件的時候,會觸發Full GC。
線上系統CPU飆高,怎麼辦?
這個問題,回答的也不是很滿意,我知道田哥整理過一份文檔,但是我還沒看到那裡去,回家的路上看了後發現,這也是可以背的面試題,居然我沒回答上來,回去加油吧。面試官來了一句:OK,今天咱們面試就到這裡,我這邊去和HR報告一下,你在這裡等一下。
過一會兒漂亮的HR走過來,面帶微笑,(我以為問題不大了),結果.....。
您是"YY吧,面試官回饋了面試情況,我們這邊要再總和考慮一下,您先回去,後續有結果,我們會電話通知您"。
(⊙o⊙)…,後面過了n多天,沒消息,果然涼涼了。
常規作業是:
1. top oder by with P:1040 // 先依照行程負載排序找到axLoad(pid)
#2.top - Hp 程序PID:1073 // 找到相關負載執行緒PID
3. printf “0x%x\n”執行緒PID:0x431 // 將執行緒PID轉換為16進制,為後面尋找jstack 日誌做準備
4. jstack 程序PID | vim /十六進位執行緒PID - // 例如:jstack 1040|vim /0x431 -
##總結
#整個面試過程還是相對輕鬆的,面試官也還挺好的,只是怪自己沒有準備好,作為一個工作兩年的我,有些問題確實是沒見過,但面試官問得問題貌似都可以達成準備好的(背面試題),也不是一定要親身經歷過。以上是上週,XX保險面試,涼了! ! !的詳細內容。更多資訊請關注PHP中文網其他相關文章!