
Python中的正規表示式及其常用匹配函數用法簡介
- Go语言进阶学习轉載
- 2023-07-25 17:17:081823瀏覽
/簡介/
# Python 自1.5版本起增加了re 模組,它提供Perl風格的正規表示式模式。 re 模組使得Python 語言擁有全部的正規表示式功能。
compile 函數根據一個模式字串和可選的標誌參數產生一個正規表示式物件。該物件擁有一系列方法用於正規表示式匹配和替換。
re 模組也提供了與這些方法功能完全一致的函數,這些函數使用一個模式字串做為它們的第一個參數。
/re.match函數/
re.match 嘗試從字串的起始位置匹配一個模式,如果不是起始位置匹配成功的話,match()就回傳none。語法如下圖所示:
re.match(pattern, string, flags=0)
「pattern」符合的正規表示式「string」要符合的字串「flags」標誌位元。
符合成功re.match方法傳回一個符合的對象,否則回傳None。
我們可以使用group(num)或 groups() 來匹配物件函數來取得匹配表達式。
group(num=0) 匹配的整个表达式的字符串,“group()”可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。
下图是个实际例子:

输出结果如下图所示:

/检索和替换/
Python 的re模块提供了re.sub用于替换字符串中的匹配项。语法如下所示:
re.sub(pattern, repl, string, count=0, flags=0)
参数:
pattern : 正则中的模式字符串。
repl : 替换的字符串,也可为一个函数。
string : 要被查找替换的原始字符串。
count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
flags : 编译时用的匹配模式,数字形式。
前三个为必参数,后两个为可选参数。
下图是个实际例子:
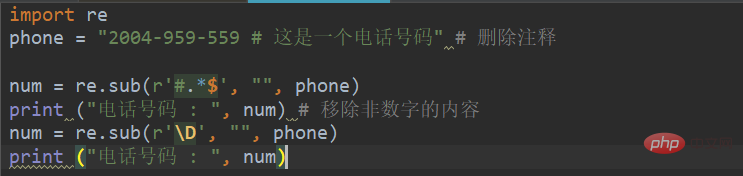
输出结果如下图所示:

/compile函数/
compile 函数用于编译正则表达式,供match() 和 search() 这两个函数使用。语法格式为:
re.compile(pattern[, flags])
参数:
pattern : 一个字符串形式的正则表达式
flags 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
re.I 忽略大小写
re.L 表示特殊字元集\w,\W, \b, \B, \s, \S 依賴目前環境
re.M 多重行模式
re.S 即為' . '且包含換行符在內的任一字元(' . '不包括換行符)
# re.U 表示特殊字元集\w,\W, \b, \B, \d, \D, \s, \S 依賴Unicode 字元屬性資料庫
re.X 為了增加可讀性,忽略空格和'# '後面的註解
#/正規表示式物件/
re.RegexObject:re.compile() 傳回RegexObject 物件。
re.MatchObject:group() 傳回 RE 相符的字串。
start() 返回匹配開始的位置
end() 返回匹配結束的位置
span() 返回一個元組包含符合(開始,結束) 的位置
##/正規表示式修飾符- 可選標誌/
#/正規表示式修飾符- 可選標誌/###### ###正規表示式可以包含一些可選標誌修飾符來控制符合的模式。修飾符被指定為一個可選的標誌。多個標誌可以透過位元 OR(|) 它們來指定。如re.I| re.M 被設定成I 和M 標誌:
re.I |
#使匹配對大小寫不敏感 |
|
#re.L |
#做本地化識別(locale-aware#)符合 |
re.M |
多行匹配,影響# ^ 和 $ |
re.S |
使 . | 符合包含換行在內的所有字元
|
根據Unicode#字元集解析字元。這個標誌影響 ### \w, \W, \b, \B.###### |
|
re.X |
#該標誌透過給予你更靈活的格式以便你將正規表示式寫得更容易理解。 |
/正規表示式模式/
# 模式字串使用特殊的語法來表示一個正規則表達式:
字母和數字表示他們自己。一個正規表示式模式中的字母和數字匹配相同的字串。
多數字母和數字前加上一個反斜線時會有不同的意義。
標點符號只有在轉義時才符合自身,否則它們表示特殊的意義。
反斜線本身需要使用反斜線進行轉義。
由於正規表示式通常都包含反斜線,所以你最好使用原始字串來表示它們。模式元素(如 r'\t',等價於 \\t )符合對應的特殊字元。
下表列出了正規表示式模式語法中的特殊元素。如果你使用模式的同時提供了可選的標誌參數,某些模式元素的意義會改變。
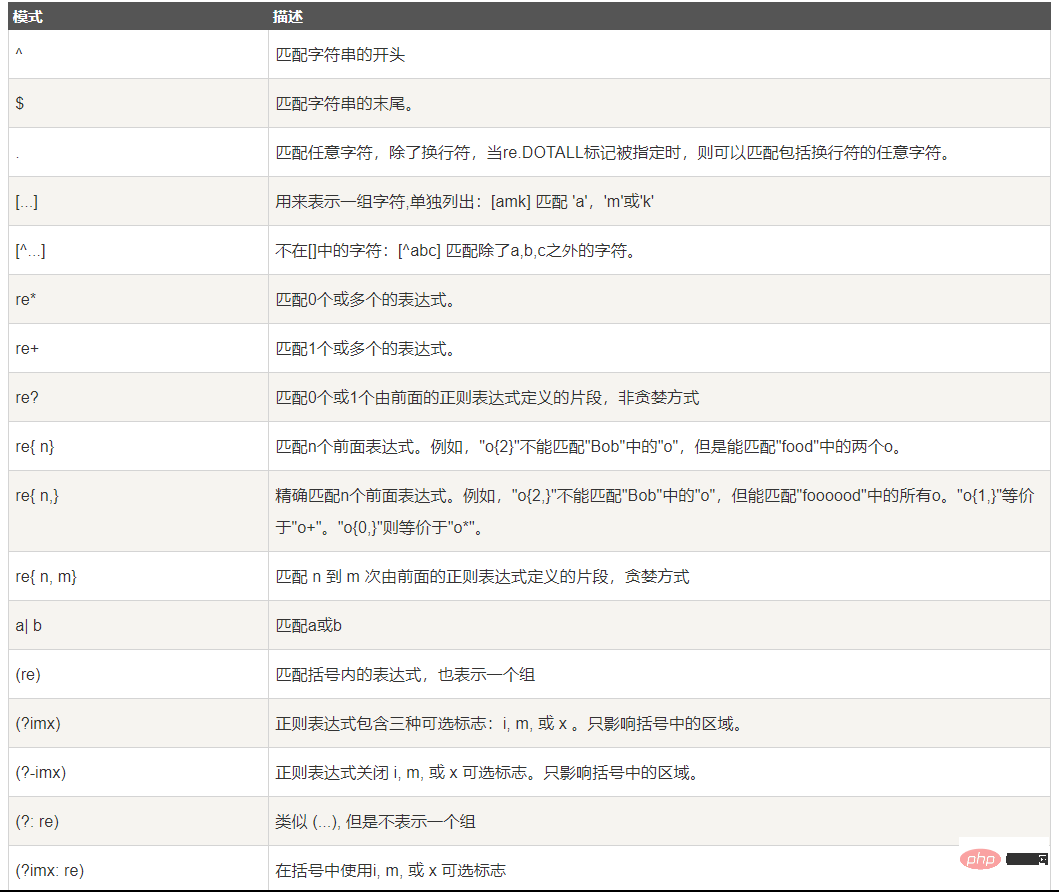
正規表示式實例
字元符合
| ##實例 ###描述######################## #python###### |
符合 "python". |
字符类
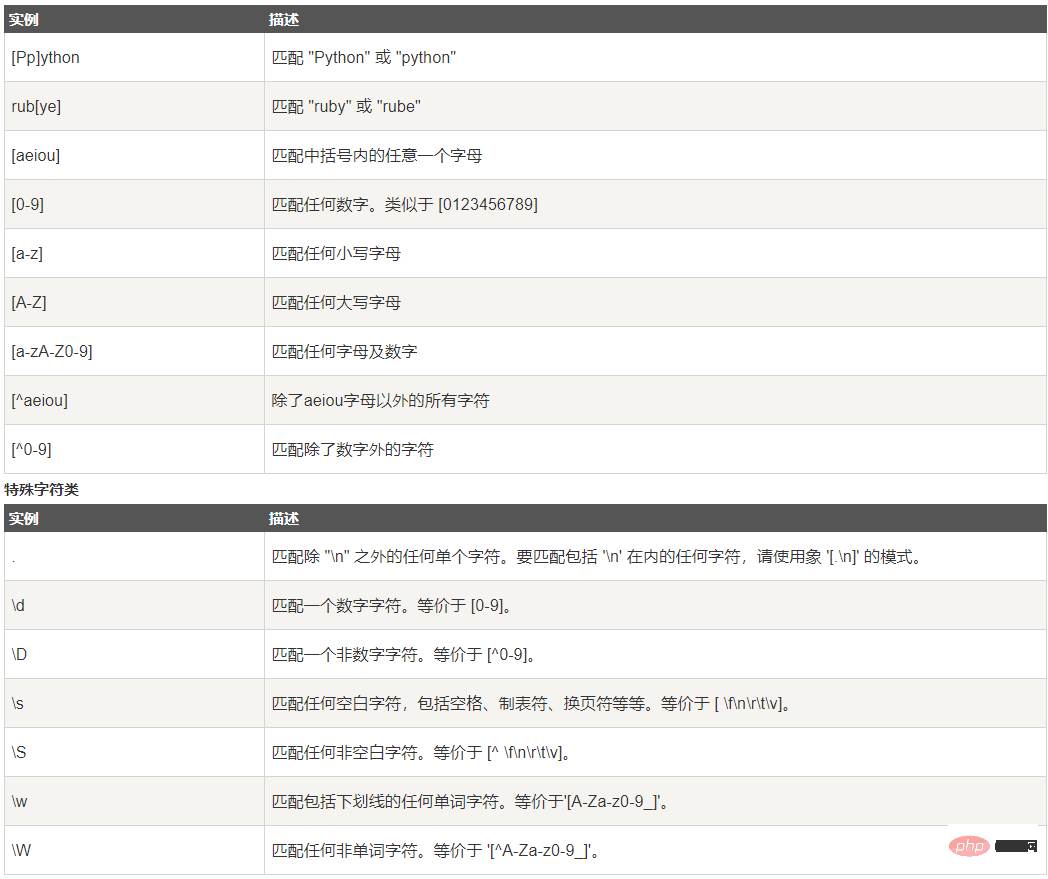
/实际应用/
以猫眼电影为例。我们需要获取(电影的名字作者,上映时间)等等都可以用正则表达式来解析。
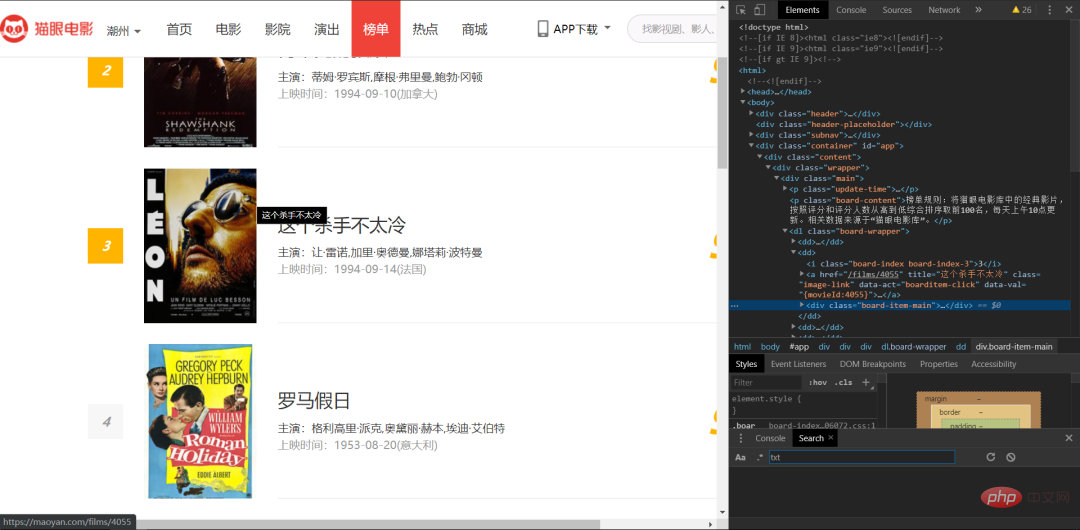
分析一下,利用正则表达式提取。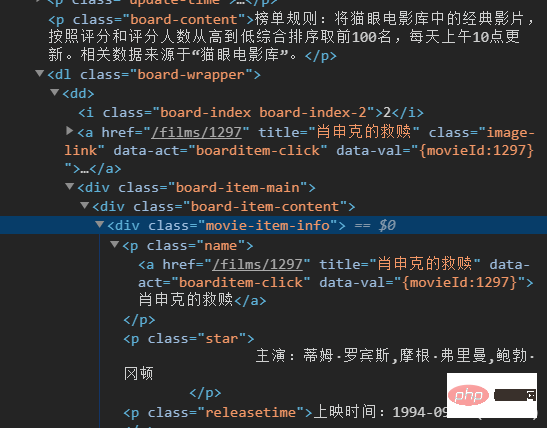
可以看到我们要的名字在一个a里面,而他们被一个div包裹着。
我们把div想象成一个盒子,可以看到div里面还有一个div 我们可以先找他上面一层的div是一个表单0d5affef54b5792b53e66baae815472b再找到它的上一层的盒子div7944fc67b6e5ce9f806e856ae5e703bc一般来说我们找到前两层就可以找到我们要的结果。如果不对就再找几层。
分析完再实际操作一下:
pattern = re.compile('<div>.*?title="(.*?)".*?class="star">(.*?)</p>.*?releasetime">(.*?)</p>',re.S)
(.*?)表示我们要的内容4dd738c46dabb06475883a3c3eaef79a(.*?)94b3e26ee717c64999d7867364b1b4a3里面的主演也是我们要的这样我们就可以得到我们想要得多个数据。
/小结/
1. 正規表示式適合一些需要取得多個資料的場景。它能夠以更快捷的方式去取得我們想要的資料。
2. 本文主要介紹了正規表示式,及其基本用法,具體每個字元的用法,可以參考前言裡邊的正規表示式系列文章,希望能夠幫助大家更好的了解正規表示式的用法。
以上是Python中的正規表示式及其常用匹配函數用法簡介的詳細內容。更多資訊請關注PHP中文網其他相關文章!