
一篇文章把 Go 中的記憶體分配扒得乾乾淨淨
- Go语言进阶学习轉載
- 2023-07-25 13:57:091387瀏覽
今天給大家盤一盤 Go 中關於記憶體管理比較常問幾個知識點。
# 1. 分配記憶體三大元件
Go 分配記憶體的過程,主要由三由大組件管理,層級由上至下分別是:
mheap
Go 在程式啟動時,首先會向作業系統申請一大塊內存,並交由mheap結構全域管理。
具體要怎麼管理呢? mheap 會將這一大塊內存,切分成不同規格的小內存塊,我們稱之為mspan,根據規格大小不同,mspan 大概有70類左右,劃分得可謂是非常的精細,足以滿足各種對象內存的分配。
那麼這些 mspan 大大小小的規格,雜亂在一起,肯定很難管理吧?
因此就有了mcentral 這下一級元件
mcentral
啟動一個Go 程序,會初始化很多的mcentral ,每個mcentral 只負責管理一種特定規格的mspan。
相當於 mcentral 實現了在 mheap 的基礎上對 mspan 的精細化管理。
但是 mcentral 在 Go 程式中是全域可見的,因此如果每次協程來 mcentral 申請記憶體的時候,都需要加鎖。
可以預想,如果每個協程都來 mcentral 申請內存,那頻繁的加鎖釋放鎖開銷是非常大的。
因此需要有一個 mcentral 的二級代理來緩衝這種壓力
mcache
在一個Go 程式裡,每個執行緒M會綁定到一個處理器P,在單一粒度的時間裡只能做多處理運行一個goroutine,每個P都會綁定一個叫mcache 的本地快取。
當需要進行記憶體分配時,目前運行的goroutine會從mcache中尋找可用的mspan。從本機mcache里分配記憶體時不需要加鎖,這種分配策略效率更高。
mspan 供應鏈
mcache 的mspan 數量並不總是充足的,當供不應求的時候,mcache 會從mcentral 再次申請更多的mspan,同樣的,如果mcentral 的mspan 數量也不夠的話,mcentral 也會向它的上級mheap 申請mspan。再極端一點,如果 mheap 裡的 mspan 也無法滿足程式的記憶體申請,那該怎麼辦?
那就沒辦法啦,mheap 只能厚著臉皮跟操作系統這個老大哥申請了。
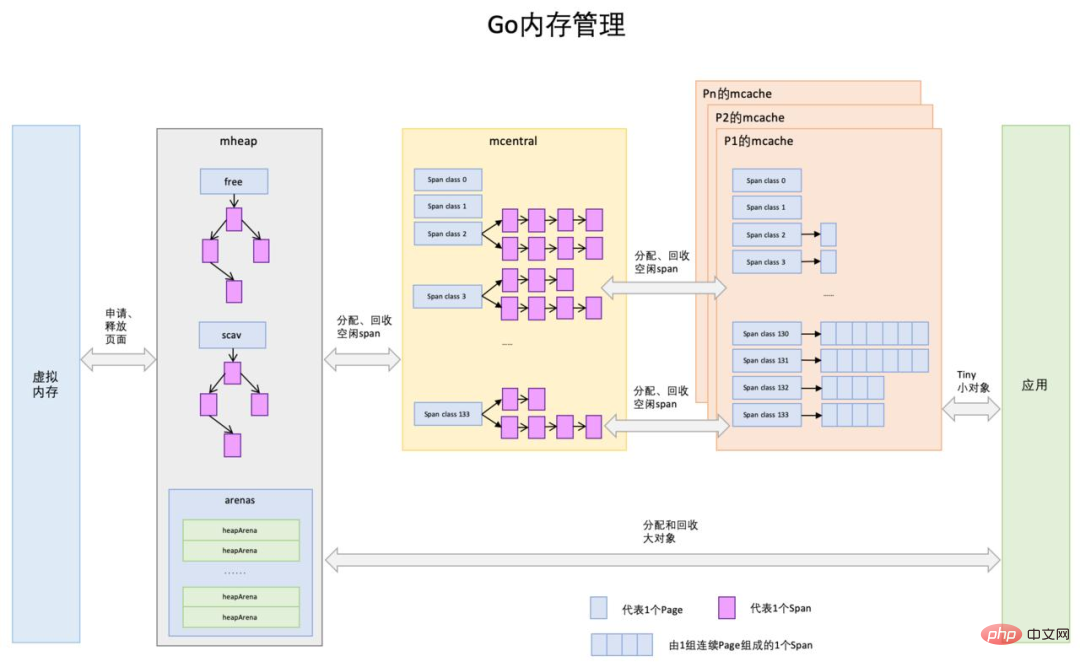
以上的供應流程,只適用於記憶體區塊小於64KB 的場景,原因在於Go 沒法使用工作執行緒的本機快取mcache和全域中心快取mcentral 上管理超過64KB 的記憶體分配,所以對於那些超過64KB 的記憶體申請,會直接從堆上(mheap)上分配對應的數量的記憶體頁(每頁大小是8KB)給程式。
# 2. 什麼是堆疊記憶體和堆疊記憶體?
根據記憶體管理(分配和回收)方式的不同,可以將記憶體分為 堆疊記憶體 和 堆疊記憶體。
那他們有什麼差別呢?
堆疊記憶體:由記憶體分配器與垃圾收集器負責回收
堆疊記憶體:由編譯器自動進行分配和釋放
一個程式運行過程中,也許會有多個堆疊內存,但肯定只會有一個堆疊內存。
每個堆疊記憶體都是由執行緒或協程獨立佔有,因此從堆疊中分配記憶體不需要加鎖,且堆疊內存在函數結束後會自動回收,效能相對堆疊記憶體好要高。
而堆記憶體呢?由於多個線程或協程都有可能同時從堆中申請內存,因此在堆中申請內存需要加鎖,避免造成衝突,並且堆內存在函數結束後,需要GC (垃圾回收)的介入參與,如果有大量的GC 操作,將會吏程序性能下降得歷害。
# 3. 逃逸分析的必要性
由此可以看出,為了提高程式的效能,應當盡量減少內存在堆上分配,這樣就能減少GC 的壓力。
在判斷一個變數是在堆上分配內存還是在棧上分配內存,雖然已經有前人已經總結了一些規律,但依靠程式設計師能夠在編碼的時候時刻去注意這個問題,對程式設計師的要求相當高。
好在 Go 的編譯器,也開放了逃逸分析的功能,使用逃逸分析,可以直接偵測你程式設計師所有分配在堆上的變數(這個現象,就是逃逸)。
方法是執行以下命令
go build -gcflags '-m -l' demo.go # 或者再加个 -m 查看更详细信息 go build -gcflags '-m -m -l' demo.go
#記憶體分配位置的規律
#如果逃脫分析工具,其實人工也可以判斷到底有哪些變數是分配在堆上的。
那麼這些規律是什麼呢?
經過總結,主要有以下四種情況
根據變數的使用範圍
#根據變數類型是否確定
根據變數的佔用大小
##根據變數長度是否確定
根據變數的使用範圍
當你進行編譯的時候,編譯器會做逃逸分析(escape analysis),當發現一個變數的使用範圍只在函數中,那麼可以在堆疊上為它分配記憶體。 例如下邊這個例子func foo() int {
v := 1024
return v
}
func main() {
m := foo()
fmt.Println(m)
}我們可以透過go build -gcflags '-m -l' demo.go 來查看逃逸分析的結果,其中 -m 是列印逃脫分析的訊息,-l 則是禁止內聯最佳化。
$ go build -gcflags '-m -l' demo.go # command-line-arguments ./demo.go:12:13: ... argument does not escape ./demo.go:12:13: m escapes to heap而如果該變數還需要在函數範圍之外使用,如果還在堆疊上分配,那麼當函數返回的時候,該變數指向的記憶體空間就會被回收,程式勢必會報錯,因此對於這種變數只能在堆上分配。 例如下邊這個例子,
回傳的是指標
func foo() *int {
v := 1024
return &v
}
func main() {
m := foo()
fmt.Println(*m) // 1024
}從逃脫分析的結果可以看到moved to heap: v ,v變數是從堆上分配的內存,和上面的場景有著明顯的差異。
$ go build -gcflags '-m -l' demo.go # command-line-arguments ./demo.go:6:2: moved to heap: v ./demo.go:12:13: ... argument does not escape ./demo.go:12:14: *m escapes to heap
除了返回指针之外,还有其他的几种情况也可归为一类:
第一种情况:返回任意引用型的变量:Slice 和 Map
func foo() []int {
a := []int{1,2,3}
return a
}
func main() {
b := foo()
fmt.Println(b)
}逃逸分析结果
$ go build -gcflags '-m -l' demo.go # command-line-arguments ./demo.go:6:12: []int literal escapes to heap ./demo.go:12:13: ... argument does not escape ./demo.go:12:13: b escapes to heap
第二种情况:在闭包函数中使用外部变量
func Increase() func() int {
n := 0
return func() int {
n++
return n
}
}
func main() {
in := Increase()
fmt.Println(in()) // 1
fmt.Println(in()) // 2
}逃逸分析结果
$ go build -gcflags '-m -l' demo.go # command-line-arguments ./demo.go:6:2: moved to heap: n ./demo.go:7:9: func literal escapes to heap ./demo.go:15:13: ... argument does not escape ./demo.go:15:16: in() escapes to heap
根据变量类型是否确定
在上边例子中,也许你发现了,所有编译输出的最后一行中都是 m escapes to heap 。
奇怪了,为什么 m 会逃逸到堆上?
其实就是因为我们调用了 fmt.Println() 函数,它的定义如下
func Println(a ...interface{}) (n int, err error) {
return Fprintln(os.Stdout, a...)
}可见其接收的参数类型是 interface{} ,对于这种编译期不能确定其参数的具体类型,编译器会将其分配于堆上。
根据变量的占用大小
最开始的时候,就介绍到,以 64KB 为分界线,我们将内存块分为 小内存块 和 大内存块。
小内存块走常规的 mspan 供应链申请,而大内存块则需要直接向 mheap,在堆区申请。
以下的例子来说明
func foo() {
nums1 := make([]int, 8191) // < 64KB
for i := 0; i < 8191; i++ {
nums1[i] = i
}
}
func bar() {
nums2 := make([]int, 8192) // = 64KB
for i := 0; i < 8192; i++ {
nums2[i] = i
}
}给 -gcflags 多加个 -m 可以看到更详细的逃逸分析的结果
$ go build -gcflags '-m -l' demo.go # command-line-arguments ./demo.go:5:15: make([]int, 8191) does not escape ./demo.go:12:15: make([]int, 8192) escapes to heap
那为什么是 64 KB 呢?
我只能说是试出来的 (8191刚好不逃逸,8192刚好逃逸),网上有很多文章千篇一律的说和 ulimit -a 中的 stack size 有关,但经过了解这个值表示的是系统栈的最大限制是 8192 KB,刚好是 8M。
$ ulimit -a -t: cpu time (seconds) unlimited -f: file size (blocks) unlimited -d: data seg size (kbytes) unlimited -s: stack size (kbytes) 8192
我个人实在无法理解这个 8192 (8M) 和 64 KB 是如何对应上的,如果有朋友知道,还请指教一下。
根据变量长度是否确定
由于逃逸分析是在编译期就运行的,而不是在运行时运行的。因此避免有一些不定长的变量可能会很大,而在栈上分配内存失败,Go 会选择把这些变量统一在堆上申请内存,这是一种可以理解的保险的做法。
func foo() {
length := 10
arr := make([]int, 0 ,length) // 由于容量是变量,因此不确定,因此在堆上申请
}
func bar() {
arr := make([]int, 0 ,10) // 由于容量是常量,因此是确定的,因此在栈上申请
}以上是一篇文章把 Go 中的記憶體分配扒得乾乾淨淨的詳細內容。更多資訊請關注PHP中文網其他相關文章!