
大語言模型的視覺天賦:GPT也能透過情境學習解決視覺任務

- 王林轉載
- 2023-07-14 15:37:061638瀏覽
目前,大型語言模型(LLM)已經掀起自然語言處理(NLP)領域的變革浪潮。我們看到 LLM 具備強大的湧現能力,在複雜的語言理解任務、生成任務甚至推理任務上都表現優異。這啟發人們進一步探索 LLM 在機器學習另一子領域 —— 電腦視覺(CV)的潛力。
LLM 的一項卓越才能是它們具備上下文學習的能力。情境學習不會更新 LLM 的任何參數,卻在各種 NLP 任務中卻展現了令人驚豔的成果。那麼,GPT 能否透過情境學習解決視覺任務呢?
最近,來自Google和卡內基美隆大學(CMU)的研究者共同發表的一篇論文表明:只要我們能夠將圖像(或其他非語言模態)轉化為LLM 能夠理解的語言,這似乎是可行的。
 圖片
圖片
論文網址:https://arxiv.org/abs/2306.17842
#這篇論文揭示了PaLM 或GPT 在透過情境學習解決視覺任務方面的能力,並提出了新方法SPAE(Semantic Pyramid AutoEncoder)。這種新方法使得 LLM 能夠執行影像生成任務,而無需進行任何參數更新。這也是使用上下文學習使得 LLM 生成圖像內容的首個成功方法。
我們先來看看透過上下文學習,LLM 在生成圖像內容的實驗效果。
例如,在給定上下文中,透過提供50 張手寫圖像,論文要求PaLM 2 回答需要產生數位影像作為輸出的複雜查詢:
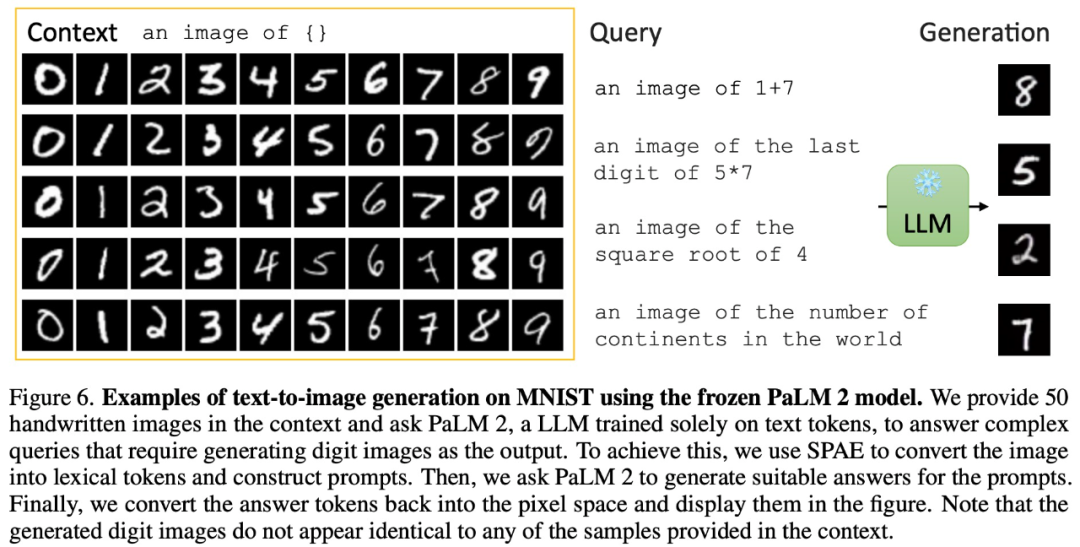 圖片
圖片
還能在有圖像上下文輸入的情況下產生逼真的現實圖像:
 圖片
圖片
除了產生圖像,透過上下文學習,PaLM 2 還能進行圖像描述:

還有與圖像相關問題的視覺問答:
 圖片
圖片
甚至可以去雜訊生成影片:
 圖片
圖片
方法概述
實際上,將圖像轉換為LLM 能夠理解的語言,是在視覺Transformer(ViT)論文中就已經研究過的問題。在 Google 和 CMU 的這篇論文中,他們將其提升到了一個新的層次 —— 使用實際的單字來表示圖像。
這種方法就像建造一個充滿文字的塔樓,捕捉圖像的語義和細節。這種充滿文字的表示方法讓影像描述可以輕鬆生成,並讓 LLM 可以回答與影像相關的問題,甚至可以重構影像像素。
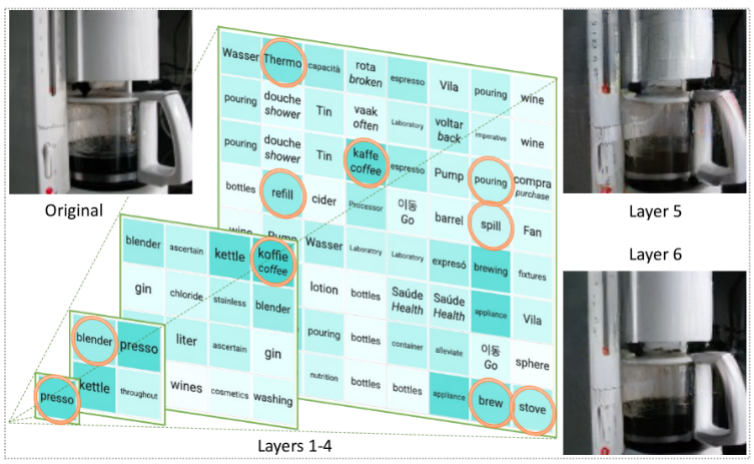
具體來說,研究提出使用經過訓練的編碼器和CLIP 模型將影像轉換為一個token 空間;然後利用LLM 產生合適的詞法token;最後使用訓練有素的解碼器將這些token 轉換回像素空間。這個巧妙的過程將圖像轉換為 LLM 可以理解的語言,使我們能夠利用 LLM 在視覺任務中的生成能力。
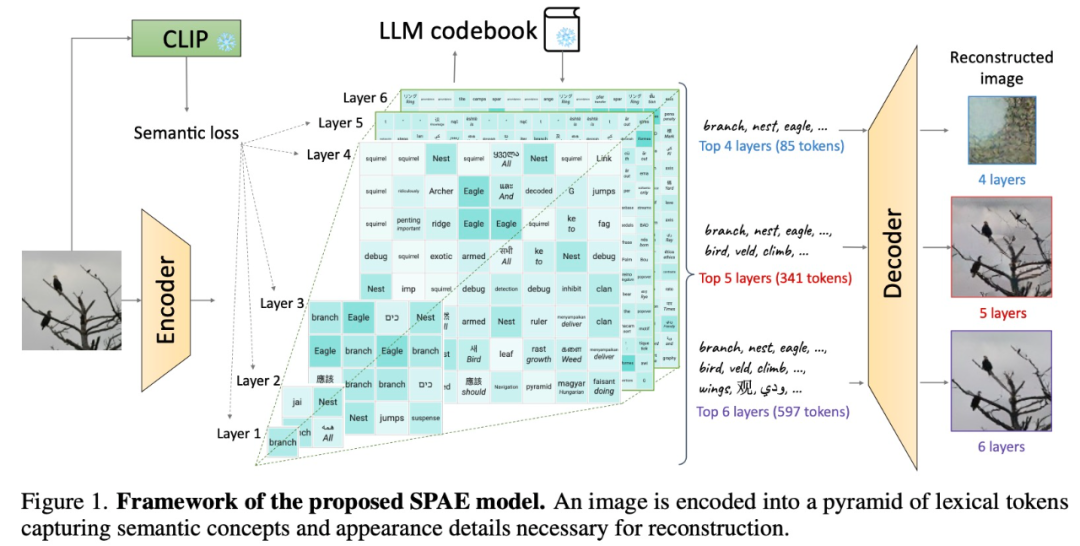
實驗及結果
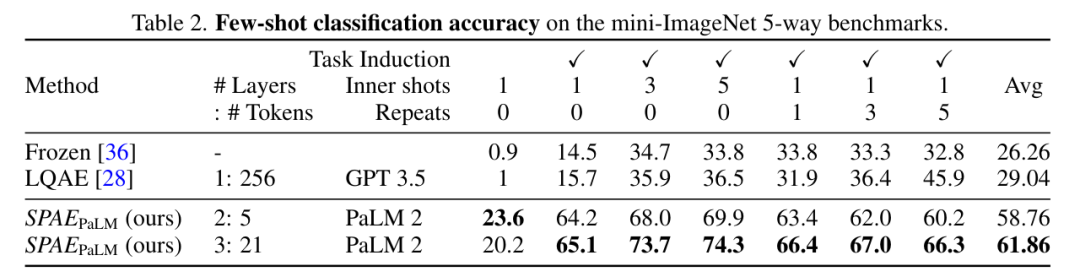
該研究將 SPAE 與 SOTA 方法 Frozen 和 LQAE 進行了實驗比較,結果如下表 1 所示。 SPAEGPT 在所有任務上表現均優於 LQAE,且僅使用 2% 的 token。
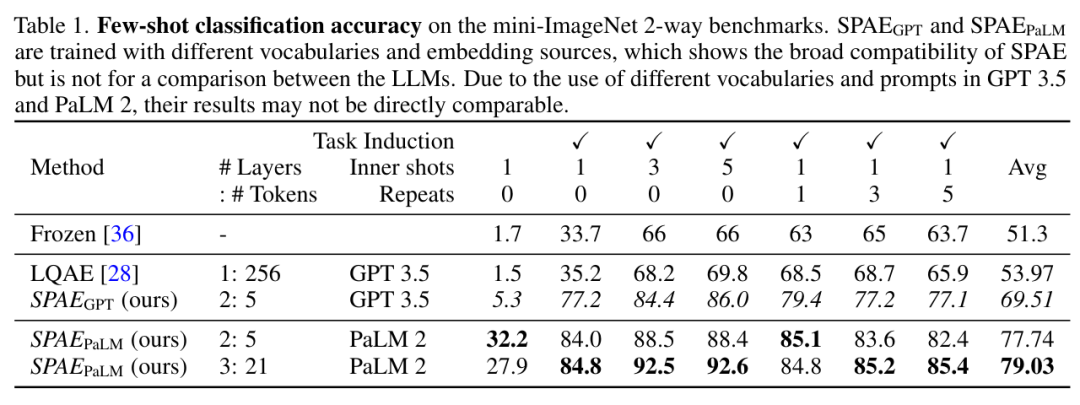 圖片
圖片
總的來說,在mini-ImageNet 基準上的測試表明,SPAE 方法相比之前的SOTA方法提升了25% 的性能。
 圖片
圖片
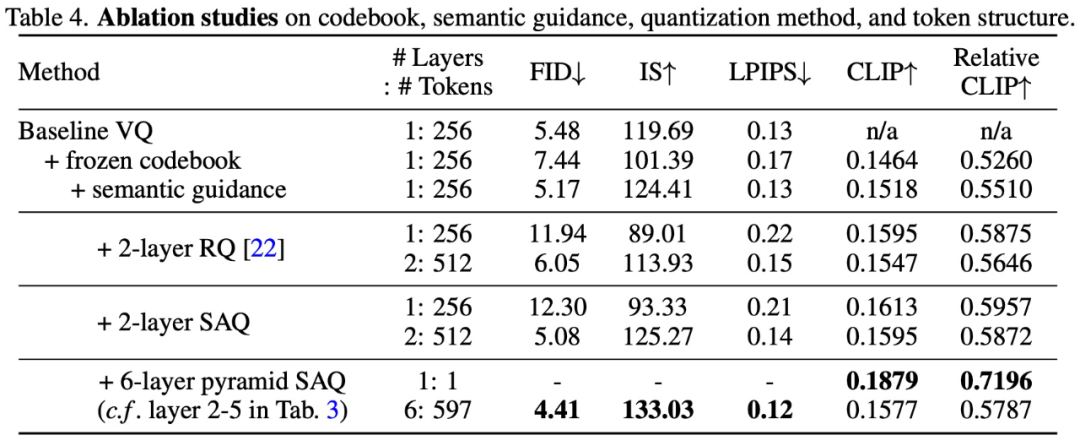
為了驗證SPAE 設計方法的有效性,研究進行了消融實驗,實驗結果如下表4 和圖10 所示:
 圖片
圖片

#感有興趣的讀者可以閱讀論文原文,了解更多研究內容。
以上是大語言模型的視覺天賦:GPT也能透過情境學習解決視覺任務的詳細內容。更多資訊請關注PHP中文網其他相關文章!