
OpenAI霸榜前二!大模型代碼生成排行榜出爐,70億LLaMA拉跨,被2.5億Codex吊打

- 王林轉載
- 2023-06-07 19:37:44721瀏覽
最近,Matthias Plappert的一篇推文點燃了LLMs圈的廣泛討論。
Plappert是一位知名的電腦科學家,他在HumanEval上發布了自己對AI圈主流的LLM進行的基準測試結果。
他的測試偏向程式碼產生方面。
結果令人大為不震撼,又大為震撼。

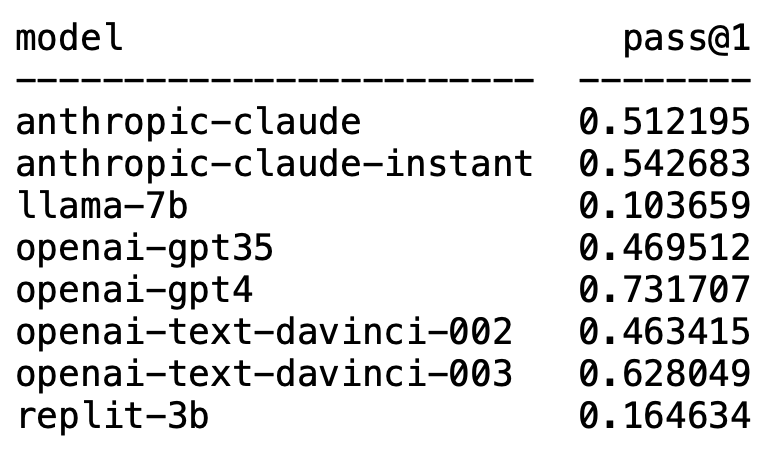
意料之內的是,GPT-4毫無疑問霸榜,摘得第一名。
意料之外的是,OpenAI的text-davinci-003異軍突起,拿了個第二。
Plappert表示,text-davinci-003堪稱一個「寶藏」模型。
而耳熟能詳的LLaMA在程式碼產生方面卻並不出色。
OpenAI霸榜
Plappert表示,GPT-4的表現表現甚至比文獻中的數據還要好。
論文中GPT-4的一輪測試數據是67%的通過率,而Plappert的測試則達到了73%。

在分析成因時,他表示,資料上存在差異有不少可能性。其中之一是他給GPT-4的prompt要比論文作者測試的時候好上那麼一些。
另一個原因是,他猜測論文在測試GPT-4的時候模型的溫度(temperature)不是0。
「溫度」是用來調整模型生成文字時創造性和多樣性的參數。 「溫度」是一個大於0的數值,通常在 0 到 1 之間。它影響模型生成文本時採樣預測詞彙的機率分佈。
當模型的「溫度」較高時(如0.8、1 或更高),模型會更傾向於從較多樣且不同的詞彙中選擇,這使得生成的文字風險性更高、創意性更強,但也可能產生更多的錯誤和不連貫之處。
而當「溫度」較低時(如0.2、0.3 等),模型主要會從具有較高機率的詞彙中選擇,從而產生更平穩、更連貫的文本。
但此時,產生的文字可能會顯得過於保守和重複。
因此在實際應用中,需要根據具體需求來權衡選擇合適的「溫度」值。
接下來,在評論text-davinci-003時,Plappert表示這也是OpenAI旗下一個很能打的模型。
雖然不比GPT-4,但是一輪測試有62%的通過率還是能穩穩拿下第二名的寶座。
Plappert強調,text-davinci-003最好的一點是,使用者不需要使用ChatGPT的API。這意味著給prompt的時候能簡單一點。
此外,Plappert也給予了Anthropic AI的claude-instant模型比較高的評估。
他認為這個模型的表現不錯,比GPT-3.5能打。 GPT-3.5的通過率是46%,而claude-instant是54%。
當然,Anthropic AI的另一個LLM——claude,沒有claude-instant能打,通過率只有51%。
Plappert表示,測試兩個模型用的prompt都一樣,不行就是不行。
除了這些熟能詳的模型,Plappert也測試了不少開源的小模型。
Plappert表示,自己能在本地運行這些模型,這點還是不錯的。
不過從規模上看,這些模型顯然沒有OpenAI和Anthropic AI的模型大,所以硬拿它們對比有點以大欺小了。

LLaMA程式碼產生?拉胯
當然,Plappert對LLaMA的測試結果並不滿意。
從測試結果來看,LLaMA在產生程式碼方面表現很差勁。可能是因為他們在從GitHub收集資料時採用了欠採樣的方法(under-sampling)。
就算和Codex 2.5B相比,LLaMA的表現也不是個兒。 (通過率10% vs. 22%)

最後,他測試了Replit的3B大小的模型。
他表示,表現還不錯,但和推特上宣傳的數據相比差點意思(通過率16% vs. 22%)
Plappert認為,這可能是因為他在測試這個模型時所用的量化方式讓通過率掉了幾個百分比。
在評測的最後,Plappert提到了一個很有趣的點。
某位用戶在推特上發現,當使用Azure平台的Completion API(補全API)(而非Chat API)時,GPT-3.5-turbo的效能表現更好。
Plappert認為這種現象具有一定合理性,因為透過Chat API輸入prompt可能會相當複雜。

以上是OpenAI霸榜前二!大模型代碼生成排行榜出爐,70億LLaMA拉跨,被2.5億Codex吊打的詳細內容。更多資訊請關注PHP中文網其他相關文章!