
OpenAI、Google雙標玩得溜:訓練大模型用他人數據,卻絕不允許自身數據外流

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-06-05 15:03:391079瀏覽
在生成式 AI 盛行的全新時代,大型科技公司在使用線上內容時正在奉行「照我說的做,而不是做我所做的策略。在某種程度上,這種策略可以說是一種雙標以及話語權的濫用。
同時,隨著大語言模型(LLM)成為 AI 發展的主流趨勢,無論是大型或新創公司,都在不遺餘力地開發自己的大模型。其中訓練資料是大模型能力好壞的重要前提。
近日,根據Insider 的報道,微軟支援的OpenAI、Google及其支援的Anthropic 多年來一直在使用其他網站或公司的線上內容來訓練他們的生成式AI 模型。這些都是在沒有徵求具體許可的情況下完成的,並將構成一場醞釀中的法律鬥爭的一部分,決定了網路的未來以及版權法在這一新時代的應用方式。

這些大型科技公司可能會主張他們是合理使用,是否真的如此有待商榷。但他們不會讓自己的內容被用來訓練其他 AI 模型。所以不禁要問,為什麼這些大型科技公司卻能在訓練大模型時使用其他公司的線上內容?
這些公司很聰明,但也非常虛偽
大型科技公司使用他人在線內容卻不允許他人使用自己的,這種說法是否有確切證據,這可以從他們一些產品的服務和使用條款中看出端倪。
首先來看 Claude,它是 Anthropic 推出的類似 ChatGPT 的 AI 助理。系統可以完成摘要總結、搜尋、協助創作、問答、編碼等任務。前段時間再次升級,將上下文 token 擴展到了 100k,處理速度大大加快。

Claude 的服務條款是這樣的。你不得以下列方式(這裡列舉出部分)存取或使用本服務,如果這些限制的任何一項與可接受使用政策不一致或不明確,則以後者依從為先:
- #開發與我們的服務競爭的任何產品或服務,包括開發或訓練任何AI 或機器學習演算法或模型
- 未經條款允許,從我們的服務中抓取、爬取或以任何其他方式取得資料或資訊
#Claude 服務條款網址:https://vault.pactsafe.io/s /9f502c93-cb5c-4571-b205-1e479da61794/legal.html#terms
#同樣地,Google的生成式AI 使用條款也是如此,「你不得使用本服務來開發機器學習模型或相關技術。」

#Google 產生式AI 使用條款位址:https: //policies.google.com/terms/generative-ai
OpenAI 的使用條款又怎樣呢?與Google類似,「你不得使用本服務的輸出來發展與OpenAI 競爭的模型。」
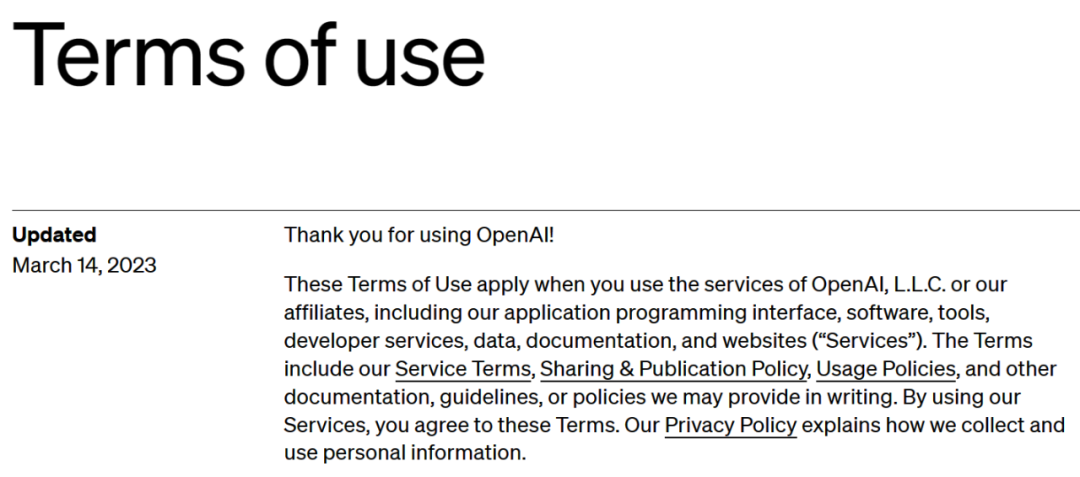
# #OpenAI 使用條款網址:https://openai.com/policies/terms-of-use
這些公司很聰明,他們知道高品質的內容對於訓練新的 AI 模型至關重要,所以不允許別人用這樣的方式使用他們的輸出也是合理的。但他們卻無所顧忌地利用他人資料來訓練自己的模型,這又該如何解釋呢?
目前,OpenAI、Google和 Anthropic 拒絕了 Insider 的置評請求,並且沒有做出任何回應。
Reddit、推特和其他公司:受夠了
實際上,其他公司意識到正在發生的事情時並不高興。今年 4 月,多年來一直被用於 AI 模型訓練的 Reddit 計劃開始對其資料的存取收費。
Reddit 執行長Steve Huffman 表示,「Reddit 的資料語料庫非常有價值,因此我們不能把這些價值免費提供給世界上最大的公司。」
同樣今年4 月,馬斯克指控OpenAI 的主要支持者微軟非法使用Twitter 的資料來訓練AI 模型。 「訴訟時間到」,他在推特上寫道。
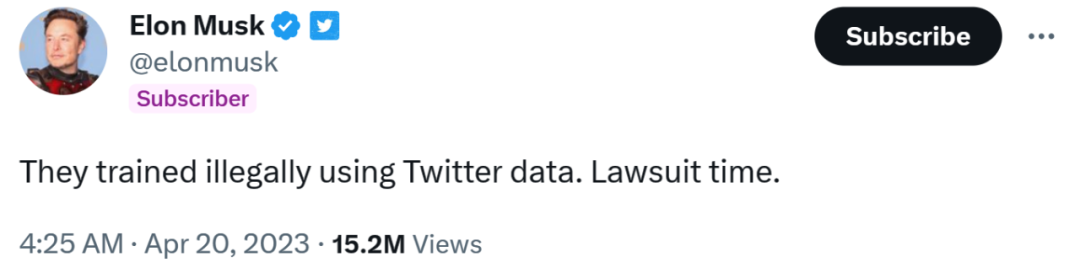
不過在回覆Insider 的評論時,微軟表示「這個前提有太多的錯誤,我甚至不知道從何說起。 」
OpenAI 執行長Sam Altman 試圖透過探索尊重版權的全新AI 模型來深化這個問題。根據Axios 報道,他近期表示,「我們正在嘗試開發新的模式,如果AI 系統使用了你的內容,或者使用了你的風格,你就會因此獲得報酬。」

##Sam Altman
出版商(包括Insider)都會是既得利益者。此外,包括美國新聞集團在內的一些出版商已經在推動科技公司付費使用其內容訓練 AI 模式。
目前 AI 模型的訓練方式「打破」了網路有前微軟高階主管表示這一定有問題。微軟老將、著名軟體開發者 Steven Sinofsky 認為,目前 AI 模型的訓練方式「打破」了網路。

Steven Sinofsky
他正在推特上寫道,「過去,爬取資料是用來換取點擊率的。但現在只是用來訓練一個模型,沒有為創作者、版權所有者帶來任何價值。」
也許,隨著更多公司的覺醒,生成式AI 時代這個不均衡的資料使用方式會很快被改變。
以上是OpenAI、Google雙標玩得溜:訓練大模型用他人數據,卻絕不允許自身數據外流的詳細內容。更多資訊請關注PHP中文網其他相關文章!