
華人科學團隊推出「思維鏈集」,全面評估大模型複雜推理能力

- 王林轉載
- 2023-06-05 13:22:29942瀏覽
大模型能力湧現,參數規模越大越好?
然而,越來越多的研究人員聲稱,小於10B的模型也可以實現與GPT-3.5相當的性能。
真是如此嗎?
OpenAI發布GPT-4的部落格中,曾提及:
在隨性的對話中,GPT-3.5與GPT-4間的差別或許非常細微。當任務的複雜性達到足夠閾值時,差異就會出現-GPT-4比GPT-3.5更可靠、更有創意,並且能夠處理更細微的指令。
Google的開發者對PaLM模型也做了類似的觀察,他們發現,大模型的思考鏈推理能力明顯強於小模型。
這些觀察值都表明,執行複雜任務的能力,才是體現大模型能力的關鍵。
就像那句老話,模型和程式設計師一樣,「廢話少說,show me the reasoning」。

來自愛丁堡大學、華盛頓大學、艾倫AI研究所的研究人員認為,複雜推理能力是大模型在未來進一步朝向更智慧化工具發展的基礎。
基本的文字總結歸納能力,大模型執行起來確實屬於「殺雞用牛刀」。
針對這些基礎能力的評比,對於研究大模型未來發展似乎是有些不務正業。
論文網址:https://arxiv.org/pdf/2305.17306.pdf
大模型推理能力哪家強?
這也就是為什麼研究人員編制了一個複雜推理任務清單Chain-of-Thought Hub,來衡量模型在具有挑戰性的推理任務中的表現。
測驗項目包括,數學(GSM8K)),科學(MATH,定理 QA),符號(BBH) ,知識(MMLU,C-Eval),編碼(HumanEval)。
這些測驗項目或資料集都是針對大模型的複雜推理能力下手,沒有那種誰來都能答得八九不離十的簡單任務。
研究者依然採用思考鏈提示(COT Prompt)的方式來對模型的推理能力進行評估。
對於推理能力的測試,研究者只採用最終答案的表現作為唯一的衡量標準,而中間的推理步驟不作為評判的依據。
如下圖所示,目前主流模型在不同推理任務上的表現。
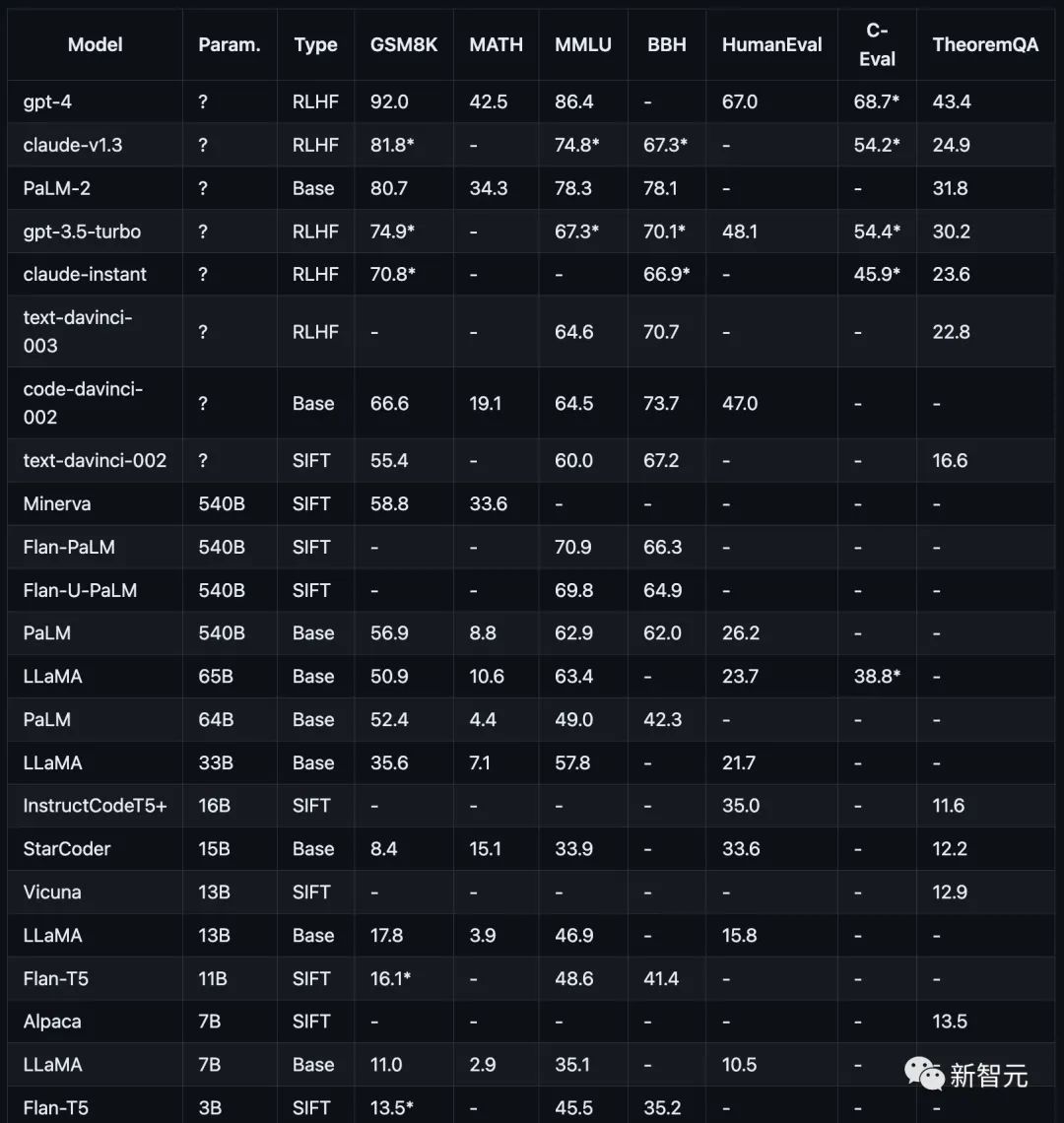
測試結果:模型越大推理能力越強
研究人員的研究專注於當前流行模型,包括GPT、Claude、PaLM、LLaMA和T5模型家族,具體而言:
OpenAI GPT包括GPT-4(目前最強)、GPT3.5-Turbo(更快,但能力較弱)、text-davinci-003、text-davinci-002和code-davinci-002(Turbo之前的重要版本)。

Anthropic Claude包括claude-v1.3(較慢但能力較強)和claude-instant-v1. 0(較快但能力較弱)。
Google PaLM,包括PaLM、PaLM-2,以及它們的指令調整版本(FLan-PaLM和Flan-UPaLM),強基礎和指令調整模型。

Meta LLaMA,包括7B、13B、33B和65B變體,重要的開放原始碼的基礎模型。
GPT-4在GSM8K和MMLU上明顯優於其他所有模型,而Claude是唯一與GPT系列相媲美的模型。
FlanT5 11B和LLaMA 7B等較小的模型掉隊掉的厲害。
透過實驗,研究人員發現,模型表現通常與規模相關,大致呈現對數線性趨勢。
不公開參數規模的模型,通常比公開規模資訊的模型表現更好。
LLaMA-65B推理能力接近ChatGPT
另外,研究者指出,開源社群可能仍需要探索關於規模和RLHF的「護城河」以進一步改進。
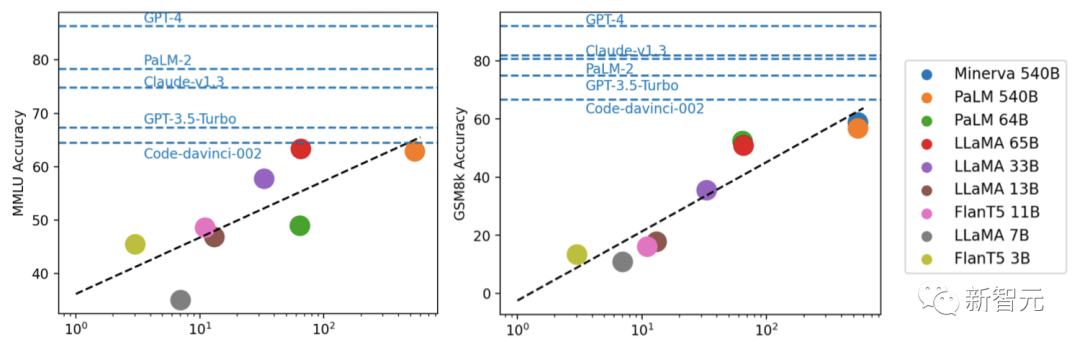
論文一作符堯總結道:
1. 開源與封閉之間存在明顯的差距。
2. 大多數排名靠前的主流模型是RLHF
#3. LLaMA-65B非常接近code-davinci-002,GPT -3.5的基礎模型
4. 綜合上述,最有希望的方向是「在LLaMA 65B上做RLHF」。

針對這個項目,作者對未來的進一步最佳化進行了說明:
#未來會增加更多包含更精心選擇的推理資料集,尤其是衡量常識推理、數學定理的資料集。
以及呼叫外部 API 的能力。
更重要的是要囊括更多語言模型,例如基於 LLaMA 的指令微調模型,例如 Vicuna7等等開源模型。
也可以透過 API像 Cohere 8 一樣存取PaLM-2 等模型的能力。
總之,作者相信這個專案可以作為評估和指導開源大語言模型發展的一個公益設施發揮很大作用。
以上是華人科學團隊推出「思維鏈集」,全面評估大模型複雜推理能力的詳細內容。更多資訊請關注PHP中文網其他相關文章!