
規模性能雙殺OpenAI,Meta語音達LLaMA等級里程碑!開源MMS模型可辨識1100+語言

- PHPz轉載
- 2023-05-24 16:25:061316瀏覽
在語音方面,Meta又達到了另一個LLaMA等級的里程碑。
今天,Meta推出了一個名為MMS的大規模多語言語音項目,它將徹底改變語音技術。
MMS支援1000多種語言,用聖經訓練,錯誤率僅為Whisper資料集的一半。
只憑一個模型,Meta就建起了一座巴別塔。
並且,Meta選擇將所有模型和程式碼開源,希望為保護世界語種的多樣性做出貢獻。

在此之前的模型可以涵蓋大約100種語言,而這次,MMS直接把這個數字增加了10-40倍!
具體來說,Meta開放了1100多種語言的多語言語音辨識/合成模型,以及4000多種語言的語音辨識模型。
與OpenAI Whisper相比,多語言ASR模型支援11倍以上的語言,但在54種語言上的平均錯誤率還不到FLEURS的一半。
而且,將ASR擴展到如此多語言之後,只造成了非常小的效能下降。
論文地址:https://research.facebook.com/publications/scaling-speech-technology-to-1000-languages/
#保護消失語種,MMS把語音辨識增加40倍
讓機器具備辨識和產生語音的能力,可以讓更多人獲得資訊。
然而,為這些任務生成高品質的機器學習模型,就需要大量的標記數據,例如數千小時的音訊以及轉錄——對於大多數語言來說,這種數據根本就不存在。
現有的語音辨識模型,只涵蓋了大約100種語言,在地球上的7000多種已知語言中,這只佔很小一部分。令人擔憂的是,在我們有生之年,這些語言中有一半都面臨著消失的危險。
在Massively Multilingual Speech(MMS)專案中,研究者透過結合wav2vec 2.0(Meta在自監督學習方面的開創性工作)和一個新的資料集來克服了一些挑戰。
這個數據集提供了超過1100種語言的標記數據,和近4000種語言的未標記數據。

透過跨語言訓練,wav2vec 2.0學習了多種語言中使用的語音單元
其中一些語言,如Tatuyo語,只有幾百個使用者,而資料集中的大多數語言,以前根本就不存在語音技術。
而結果顯示,MMS模型的表現優於現有的模型,而覆蓋語言的數量是現有模型的10倍。
Meta一向專注於多語言工作:在文本上,Meta的NLLB項目將多語言翻譯擴展到了200種語言,而MMS項目,則將語音技術擴展到更多語言。
聖經解決語音資料集難題
收集數千種語言的音訊資料並不是一件簡單的事情,這也是Meta的研究人員面臨的第一個挑戰。
要知道,現有的最大語音資料集最多也只涵蓋了100種語言。為了克服這個問題,研究人員轉向了宗教文本,如《聖經》。
這類文本已經被翻譯成許多不同的語言,被用於廣泛的研究,還有各種公開的錄音。
為此,Meta的研究者專門創建了一個超過1100種語言的《新約》閱讀資料集,平均每種語言提供32小時的資料。
再加上其他各種宗教讀物的無標籤錄音,研究者將可用的語言數量增加到了4000多種。
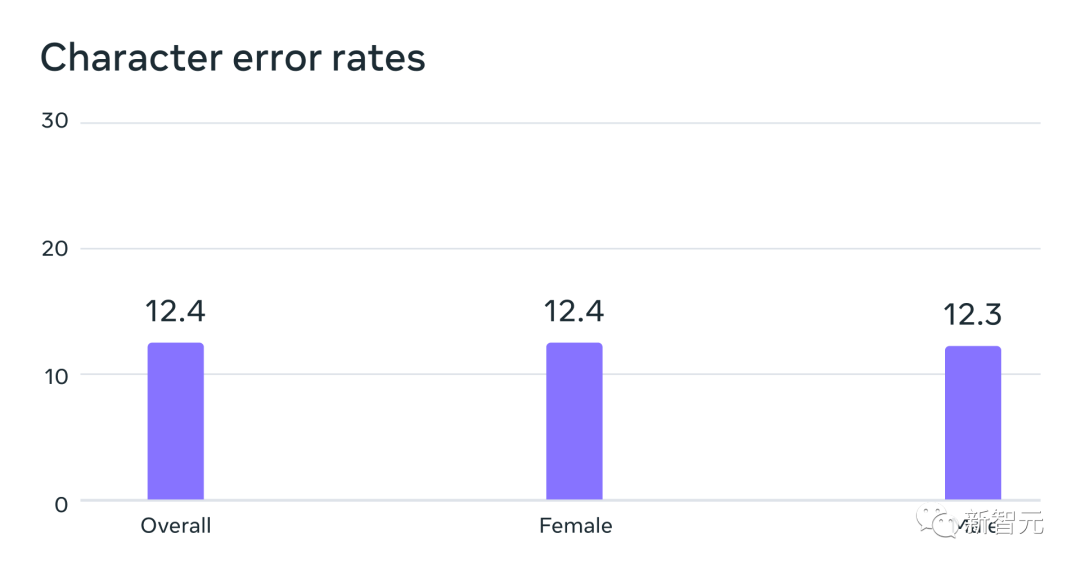
在MMS資料上訓練的自動語音辨識模型,在FLEURS基準測試中,對男性和女性說話者俱有相似的錯誤率
這些數據通常是由男性朗讀的,但模型對男性和女性的聲音表現得同樣好。
並且,雖然錄音的內容是宗教性的,但這並沒有使模型過度偏向於產生更多的宗教語言。
研究人員分析認為,這是因為他們使用了連結主義時間分類方法,與用於語音辨識的大語言模型或序列對序列模型相比,它的約束性大得多。
模型越大,越能打?
研究人員首先對資料進行了預處理,以提高資料的質量,並使其能被機器學習演算法所利用。
為此,研究人員在100多種語言的現有資料上訓練了一個對齊模型,並將這個模型與一個高效的強制對齊演算法一起使用,而該演算法可以處理大約20分鐘或更長的錄音。
研究人員多次重複了這個過程,並根據模型的準確性進行了最後的交叉驗證過濾步驟,為的是去除潛在的錯誤對齊資料。
為了使其他研究人員能夠創建新的語音資料集,研究人員將對齊演算法添加到了PyTorch中並發布了對齊模型。
目前,每種語言都有32小時的數據,但這並不足以訓練傳統的監督式語音辨識模型。
這就是為什麼研究人員在wav2vec 2.0上訓練模型,這樣可以大幅減少訓練一個模型所需的標註資料量。
具體來說,研究人員在超過1400種語言的約50萬小時的語音資料上訓練了自監督模型——這個量比過去多了近5倍。
然後針對特定的語音任務,如多語言語音識別或語言識別,研究人員再對模型進行微調即可。
為了更好地了解在大規模多語言語音資料上訓練的模型的表現,研究人員在現有的基準資料集上對它們進行了評估。
研究者使用一個1B參數的wav2vec 2.0模型對超過1100種語言進行多語言語音辨識模型的訓練。
隨著語言數量的增加,效能確實有所下降,但這種下降比較輕微——從61種語言到1107種語言,字元錯誤率只增加了約0.4 %,但語言覆蓋率增加了18倍以上。
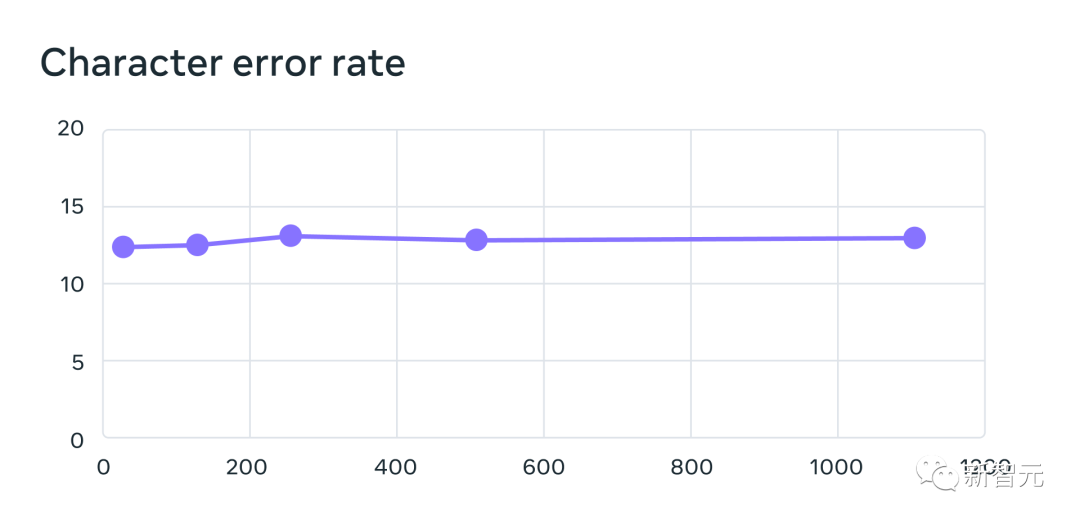
將每個系統支援的語言數量從61增加到1,107 時,使用MMS資料訓練的多語言辨識系統的61種FLEURS語言的錯誤率。錯誤率越高表示表現越低
在與OpenAI的Whisper進行同類比較時,研究人員發現,在Massively Multilingual Speech資料上訓練的模型有將近一半的單字錯誤率,但Massively Multilingual Speech涵蓋的語言是Whisper的11倍。
從數據中我們可以看出,與目前最好的語音模型相比,Meta的模型表現的真的非常不錯。
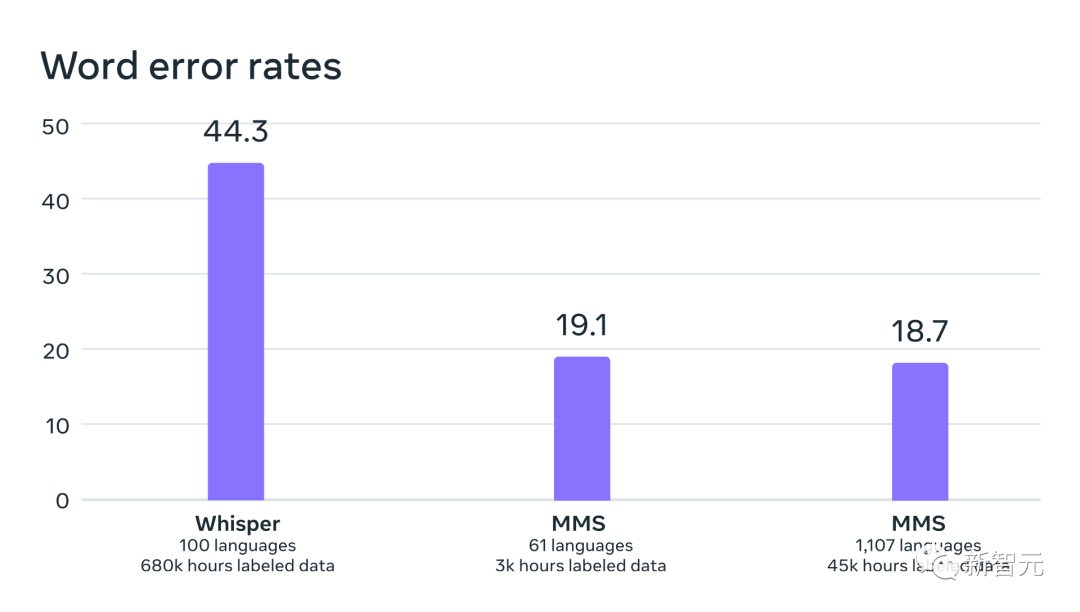
OpenAI Whisper與Massively Multilingual Speech在54種FLEURS語言上的單字錯誤率對比
#接下來,研究人員使用自己的以及現有的資料集,如FLEURS和CommonVoice,為超過4000種語言訓練了一個語言識別(LID)模型,並在FLEURS LID任務上對其進行了評估。
事實證明,即使支持了將近40倍的語言數量,效能依然很能打。
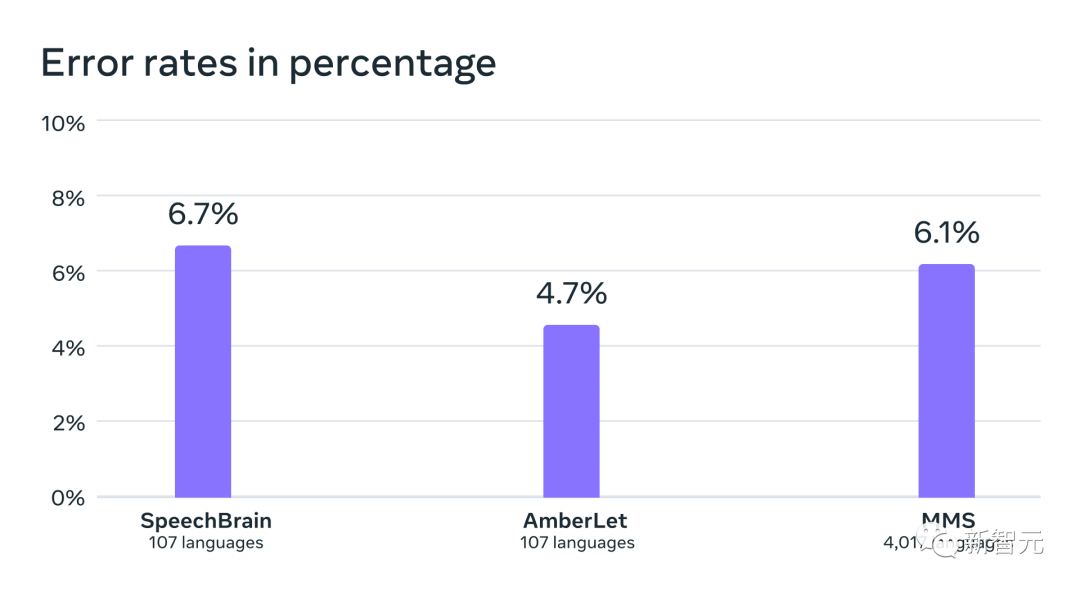
在現有工作的VoxLingua-107基準上的語言辨識準確性,支援的語言剛好超過100種,而MMS則支援超過4000種語言。
研究人員也為超過1100種語言建立了文字轉語音的系統。
大規模多語種語音資料有一個局限性,那就是對於許多語言來說,它包含的不同說話者數量相對較少,通常只有一個說話者。
然而,這個特點對於建立文字轉語音系統來說是一個優勢,因此研究人員為超過1100種語言訓練了類似系統。
結果表明,這些系統產生的語音品質還不錯。
未來屬於單一模型
Meta的研究人員對這個結果感到很滿意,但與所有新興的AI技術一樣,Meta目前的模型並不算完美。
比方說,語音到文字模型可能會誤寫選定的單字或短語,可能會導致冒犯性的或不準確的輸出結果。
同時,Meta認為,AI巨頭的合作對於負責任的AI技術的發展至關重要。
世界上的許多語言都有消失的危險,而目前語音辨識和語音產生技術的限制只會加速這一趨勢。
研究人員設想一個科技產生相反效果的世界,鼓勵人們保持其語言的活力,因為他們可以透過說自己喜歡的語言來獲取資訊和使用科技。
大規模多語言語音計畫是朝著這個方向邁出的重要一步。
在未來,研究人員希望進一步增加語言的涵蓋範圍,支援更多的語言,甚至會想辦法搞定方言。要知道,方言對現有的語音技術來說並不簡單。
Meta的最終目標是讓人們更容易用自己喜歡的語言取得資訊、使用裝置。
最後,Meta的研究人員也設想了這樣一個未來場景──靠著單一的模型就可以解決所有語言的幾個語音任務。
目前雖然Meta為語音辨識、語音合成和語言辨識訓練了單獨的模型,但研究人員相信,在未來,只需一個模型就能完成所有這些任務,甚至不止。
以上是規模性能雙殺OpenAI,Meta語音達LLaMA等級里程碑!開源MMS模型可辨識1100+語言的詳細內容。更多資訊請關注PHP中文網其他相關文章!