
北大、西湖大學等開源「裁判大模型」PandaLM:三行程式碼全自動評估LLM,準確率達ChatGPT的94%

- 王林轉載
- 2023-05-19 11:55:051813瀏覽
ChatGPT發布後,自然語言處理領域的生態徹底發生了變化,許多之前無法完成的問題都可以利用ChatGPT解決。
不過也帶來了一個問題:大模型的表現都太強了,光靠肉眼很難評估各個模型的差異。
例如用不同的基座模型和超參數訓練了幾版模型,從樣本來看表現可能都差不多,無法完全量化兩個模型之間的表現差距。
目前評估大語言模型主要有兩個方案:
1、呼叫OpenAI的API介面評估。
ChatGPT可以用來評估兩個模型輸出的質量,不過ChatGPT一直在迭代升級,不同時間對同一個問題的回應可能會有所不同,評估結果存在無法復現的問題。
2、手動標註
如果在眾包平台上請手動標註的話,經費不足的團隊可能無力負擔,也存在第三方公司洩漏資料的情況。
為了解決諸如此類的「大模型評估問題」,來自北京大學、西湖大學、北卡羅來納州立大學、卡內基梅隆大學、MSRA的研究人員合作開發了一個全新的語言模型評估架構PandaLM,致力於實現保護隱私、可靠、可重現及廉價的大模型評估方案。

專案連結:https://github.com/WeOpenML/PandaLM
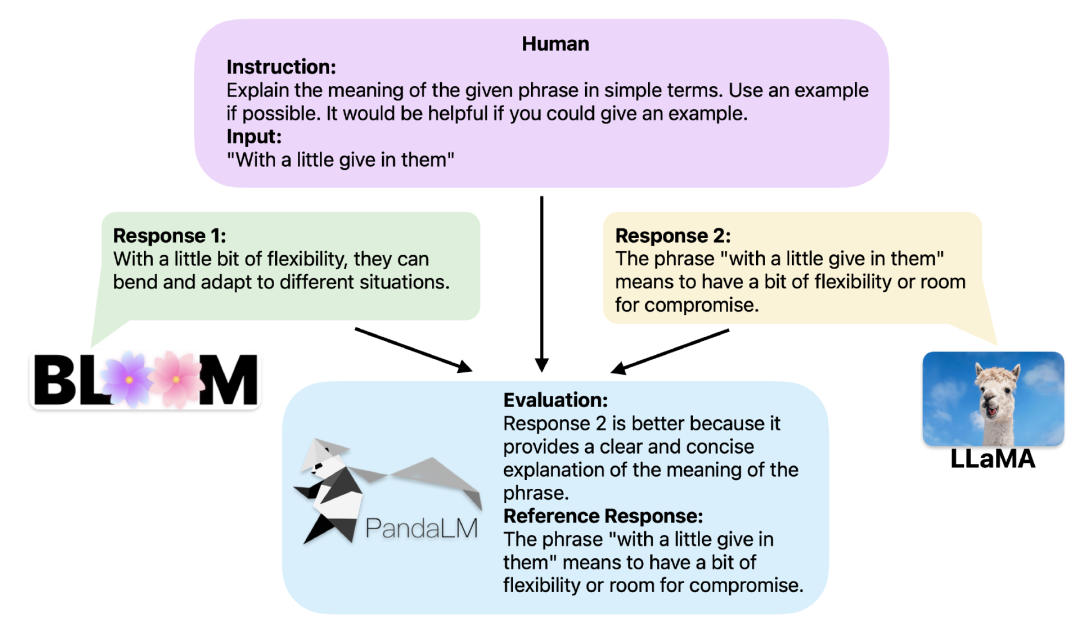
提供相同的上下文,PandaLM可以比較不同LLM的回應輸出,並提供具體的理由。
為了證明工具的可靠性和一致性,研究人員創建了一個由大約1000個樣本組成的多樣化的人類標註測試資料集,其中PandaLM-7B的準確率達到了ChatGPT的94%評估能力。
三行程式碼用上PandaLM
當兩個不同的大模型對同一個指令和上下文產生不同回應時,PandaLM旨在比較這兩個大模型的響應質量,並輸出比較結果,比較理由以及可供參考的響應。
比較結果有三種:回應1更好,回應2更好,回應1與回應2品質相似。
比較多個大模型的效能時,只需使用PandaLM對其進行兩兩比較,再匯總兩兩比較的結果進行多個大模型的效能排名或畫出模型偏序關係圖,即可清楚直觀地分析不同模型間的表現差異。
PandaLM只需要在「本地部署」,且「不需要人類參與」,因此PandaLM的評估是可以保護隱私且相當廉價的。
為了提供更好的解釋性,PandaLM亦可用自然語言對其選擇進行解釋,並額外產生一組參考回應。
在專案中,研究人員不僅支援使用Web UI使用PandaLM以便於進行案例分析,為了方便使用,也支援三行程式碼呼叫PandaLM對任意模型和資料生成的文字評估。
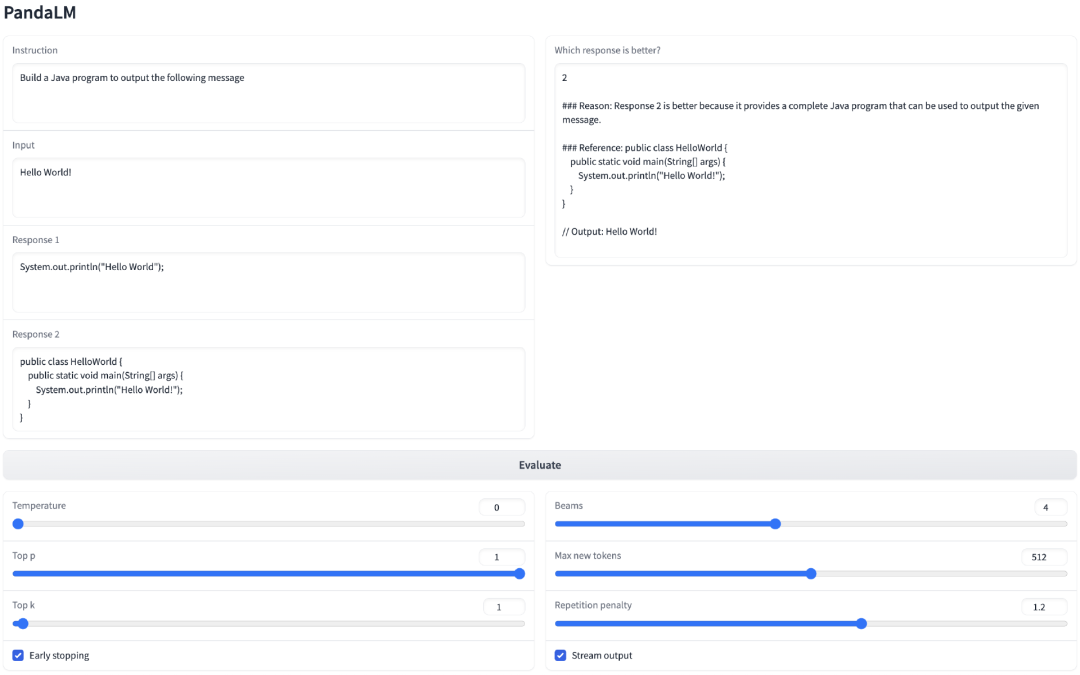
考慮到現有的許多模型、框架並不開源或難以在本地完成推理,PandaLM支持利用指定模型權重生成待評估文本,或直接傳入包含待評估文本的.json文件。
使用者只需傳入一個包含模型名稱/HuggingFace模型ID或.json檔案路徑的列表,即可利用PandaLM對使用者定義的模型和輸入資料進行評估。以下是一個極簡的使用範例:

#為了能讓大家靈活的運用PandaLM進行自由評測,研究人員也將PandaLM的模型權重公佈在了huggingface網站上,可以透過以下指令載入PandaLM-7B模型:

PandaLM的特點
可復現性
#因為PandaLM的權重是公開的,即使語言模型的輸出有隨機性,當固定隨機種子之後,PandaLM的評價結果仍可始終保持一致。
而基於線上API的模型的更新不透明,其輸出在不同時間有可能很不一致,且舊版模型不再可訪問,因此基於在線API的評測往往不具有可復現性。
自動化、保護隱私性和開銷低
#只需本地部署PandaLM模型,呼叫現成的指令即可開始評估各種大模型,不需像僱用專家標註時要時刻與專家保持溝通,也不會存在資料外洩的問題,同時也不涉及任何API費用以及勞務費用,非常廉價。
評估水平
#為了證明PandaLM的可靠性,研究人員僱用了三個專家進行獨立重複標註,創建了一個人工標註的測試集。
測試集包含50個不同的場景,每個場景中又包含若干任務。這個測試集是多樣化、可靠且與人類對文本的偏好相一致的。測試集的每個樣本由一個指令和上下文,以及兩個由不同大模型產生的回應共同組成,並由人類來比較這兩個回應的品質。
篩除了標註員之間有較大差異的樣本,以確保每個標註者在最終測試集上的IAA(Inter Annotator Agreement)接近0.85。值得注意的是,PandaLM的訓練集與創建的人工標註測試集沒有任何重疊。
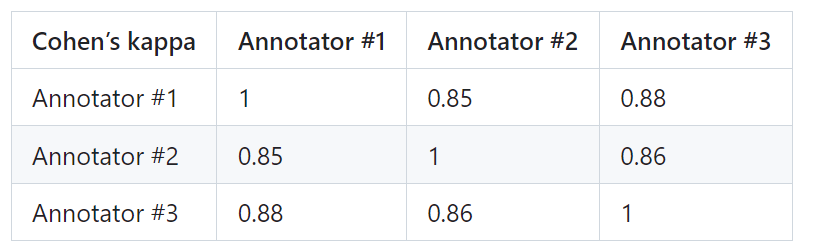
這些被過濾的樣本需要額外的知識或難以獲得的資訊來輔助判斷,這使得人類也難以對它們進行準確標註。
經過篩選的測試集包含1000個樣本,而原始未經過濾的測試集包含2500個樣本。測試集的分佈為{0:105,1:422,2:472},其中0表示兩個響應質量相似,1表示響應1更好,2表示響應2更好。以人類測試集為基準,PandaLM與gpt-3.5-turbo的表現比較如下:
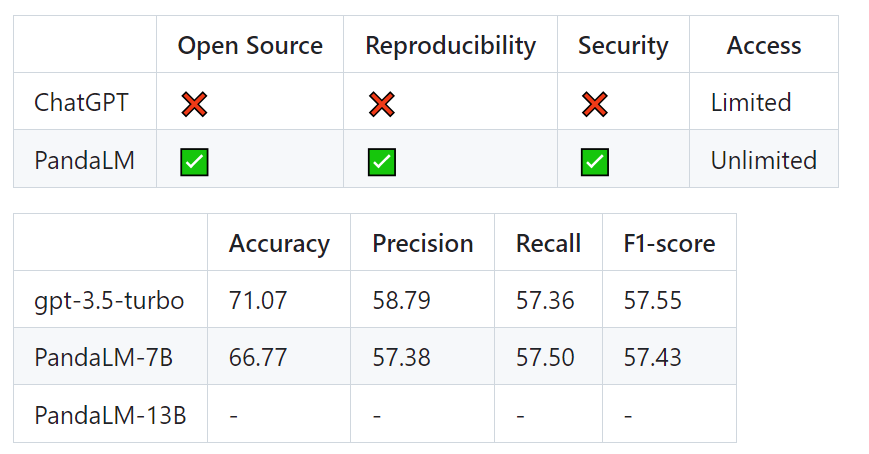
可以看到,PandaLM-7B在準確度上已經達到了gpt-3.5-turbo 94%的水平,而在精確率,召回率,F1分數上,PandaLM-7B已於gpt-3.5-turbo相差無幾。
因此,相較於gpt-3.5-turbo而言,可以認為PandaLM-7B已經具備了相當的大模型評估能力。
除了在測試集上的準確度,精確率,召回率,F1分數之外,還提供了5個大小相近且開源的大模型之間比較的結果。
首先使用了相同的訓練資料對這個5個模型進行指令微調,接著用人類,gpt-3.5-turbo,PandaLM對這5個模型分別進行兩兩比較。
下表中第一行第一個元組(72,28,11)表示有72個LLaMA-7B的回應比Bloom-7B的好,有28個LLaMA -7B的響應比Bloom-7B的差,兩個模型有11個響應品質相似。
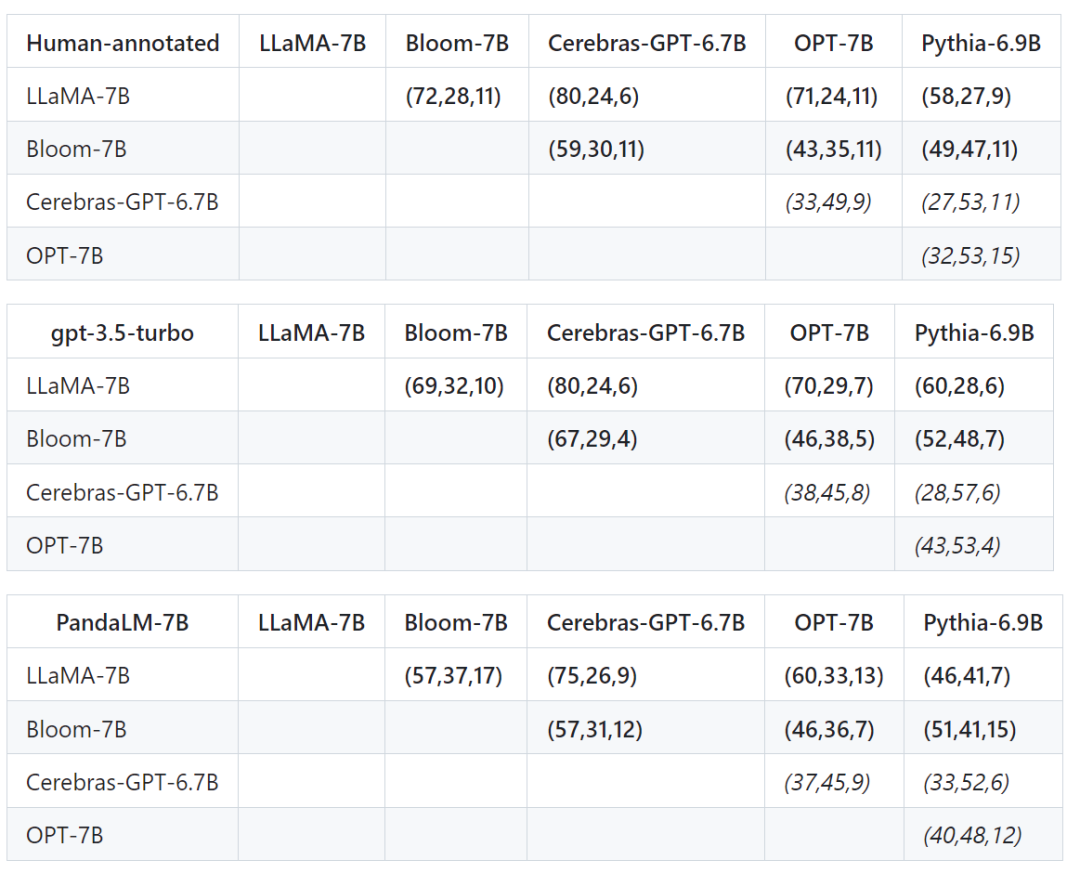
因此在這個例子中,人類認為LLaMA-7B優於Bloom-7B。以下三張表的結果說明人類,gpt-3.5-turbo與PandaLM-7B對於各模型之間優劣關係的判斷完全一致。
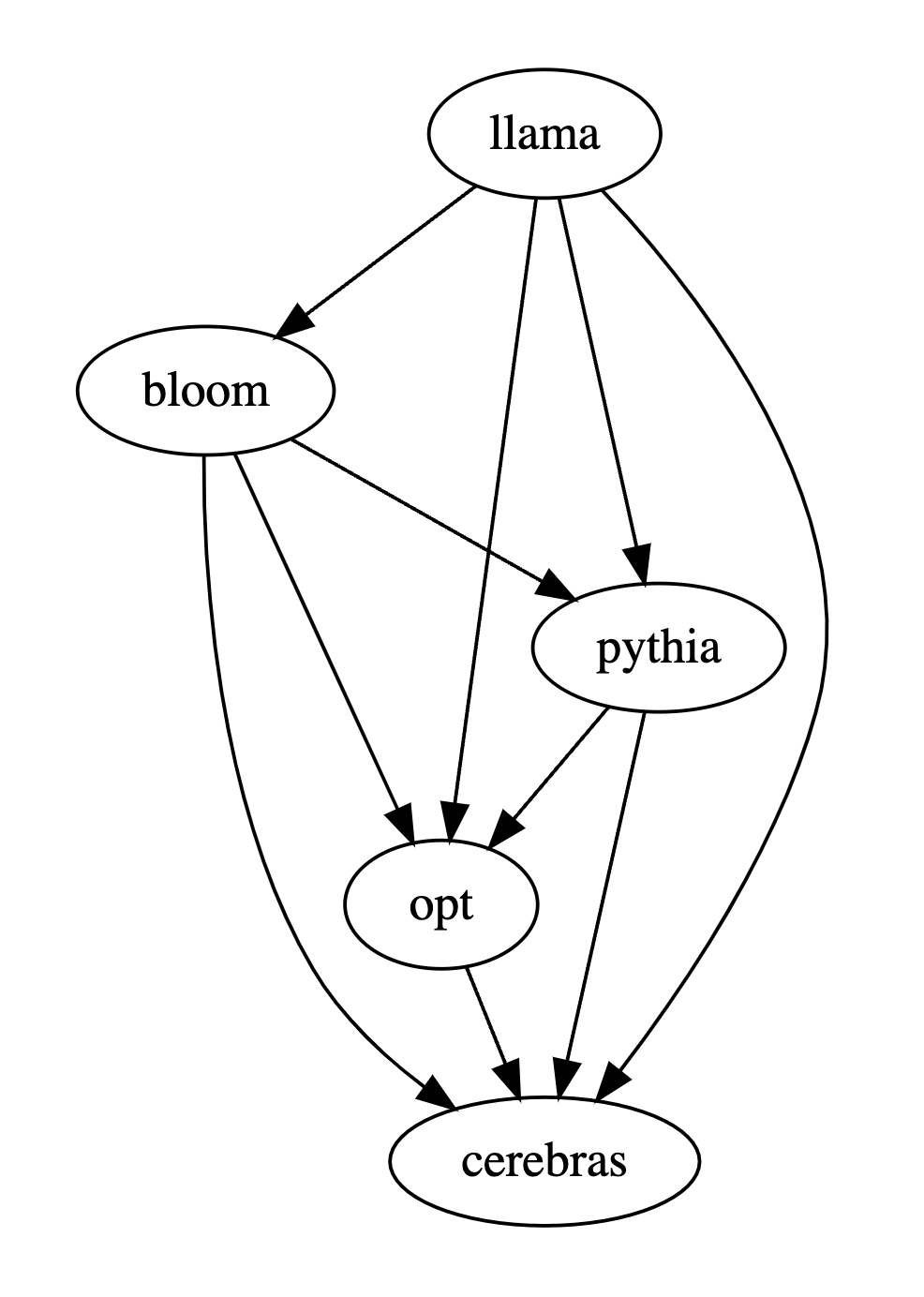
總結
#PandaLM提供了人類評估與OpenAI API評估之外的第三條評估大模型的方案,PandaLM不僅評估水準高,而且評估結果可復現,評估流程自動化,保護隱私且開銷低。
未來,PandaLM將推動學術界和工業界關於大模型的研究,使得更多人受益於大模型的發展。
以上是北大、西湖大學等開源「裁判大模型」PandaLM:三行程式碼全自動評估LLM,準確率達ChatGPT的94%的詳細內容。更多資訊請關注PHP中文網其他相關文章!