
從技術層面聊聊雙目自動駕駛系統為何難以普及?

- 王林轉載
- 2023-05-19 10:12:201664瀏覽
單目視覺是Mobileye(ME)的看家法寶,其實當年它也考慮過雙目,最終選擇放棄。
單目的測距和3-D估計靠什麼?是偵測目標的Bounding Box(BB),如果無法偵測的障礙物,該系統就無法估計其距離和3-D姿態/朝向。沒有深度學習的時候,ME主要是基於BB,攝影機標定得到的姿態和高度以及路面平直的假設估算距離。
有了深度學習,可以根據3-D的ground truth來訓練NN模型,得到3D大小和姿態估計,距離是基於平行線原理(single view metrology)得到的。不久前百度Apollo公佈的單目L3解決方案講的比較清楚了,參考論文是“3D Bounding Box Estimation by Deep Learning and Geometry".
雙眼當然可以算視差和深度了,即使沒有檢測出障礙物(因為有附加的深度信息,檢測器會比單目好),也會報警。問題是,雙眼視覺系統估計視差沒那麼容易,立體匹配是計算機視覺典型的難題,基線寬得到遠目標測距準,而基線短得到近目標測距結果好,這裡是存在折衷的。
目前市面上ADAS存在的雙眼視覺系統就是Subaru EyeSight,據說表現還行。

百度推出的阿波龍L4擺渡車量產100台,就安裝了雙目系統。還有歐盟自主停車計畫V-Charge也採用了前向雙眼視覺系統,另外自動駕駛研發系統Berta Benz也是,而且和雷達系統後融合,其中雙眼匹配的障礙物偵測演算法Stixel很有名。以前Bosch和Conti這些Tier-1公司也研發過雙眼視覺解決方案,但沒有在市場上產生影響力,據說被砍掉了。
談到雙眼系統的困難點,除了立體匹配,還有標定。標定後的系統會出現「漂移」的,所以線上標定是必須具有的。單目也是一樣,因為輪胎變形和車體顛簸都會影響攝影機外參數變化,必須在線上做標定修正一些參數,例如仰角(pitch angle)和偏角(yaw angle)。
雙眼在線標定就更複雜些,因為雙目匹配盡量簡化成1-D搜索,所以需要通過stereo rectification將兩個鏡頭光軸方向平行並和基線垂直。所以針對獲得的gain相比,增加的複雜度和成本,如果不划算商家就會放棄。
最近重提雙眼視覺,是因為矽谷晶片公司安霸(Ambarella)在2014年收購義大利帕瑪大學的Vis Lab,研發了雙目的ADAS和自動駕駛晶片,去年CES之後就開始進軍車廠和Tier-1。而且,安霸目前正在繼續研究提升該系統的效能。
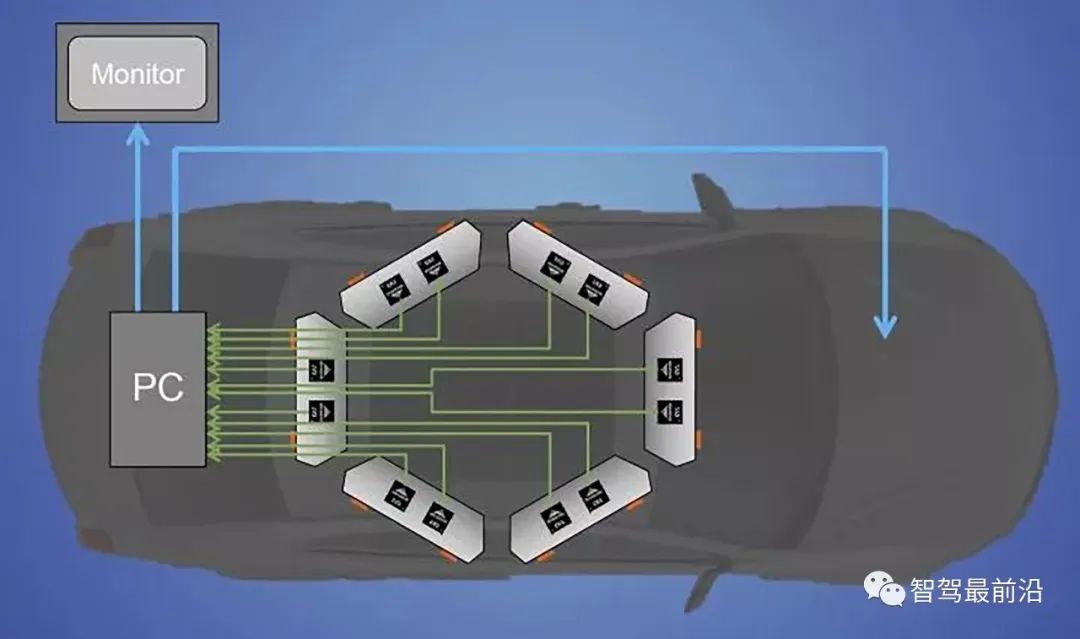
下圖就是它在車頂安裝6對立體視覺系統的示意圖,其中它們的基線寬度可以不一樣的,相應地有效檢測距離也就不同。筆者曾坐過它的自動駕駛車,遠處可以看到200米,近處20-30米。它確實可以做線上標定,隨時調整一些雙眼視覺的參數。
01 立體匹配
先說立體匹配,即視差/深度估計。如圖假設左右鏡頭焦距f,基線(兩個光心連線)寬B,3-D點X的深度z,而其視差(投影到左右影像的2-D點,其座標差)即
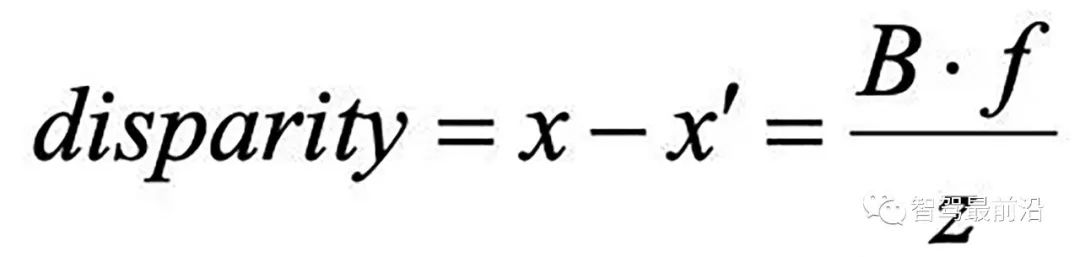
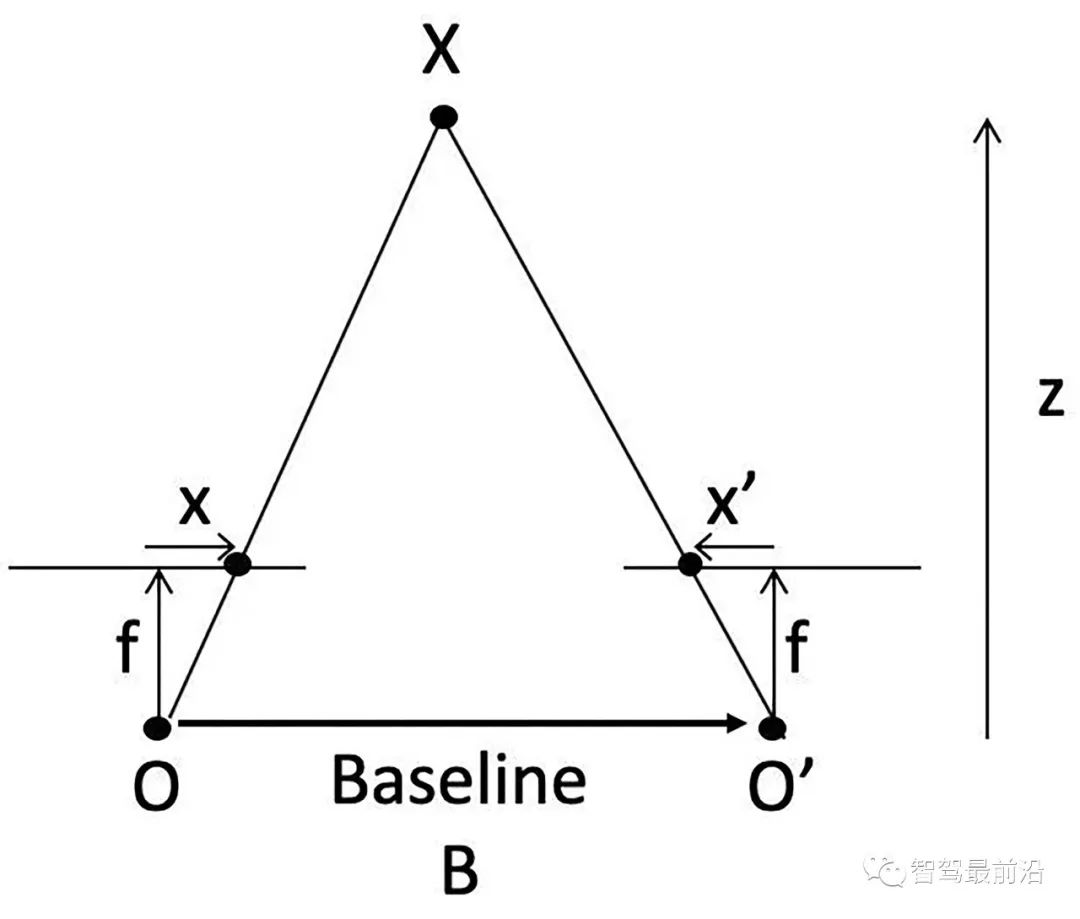
可見視差能夠反算深度值。但這裡最難的就是左右鏡頭看到的影像如何確定是同一個目標,即匹配問題。
匹配方法分兩種,全域法和局部法,雙目匹配的四個步驟:
- 匹配成本(matching cost)計算;
- 成本聚集(aggregation);
- 視差(disparity)計算/優化;
- 視差修正(refinement)。
最著名的局部法就是SGM(semi-global matching),許多產品在用的方法都是基於此的改進,不少視覺晶片都採用這種演算法.
SGM就是把一個全域最佳化近似成多個局部最佳化的問題組合,如下公式是2-D匹配的最佳化目標函數,SGM實現成為多個1-D最佳化路徑之和
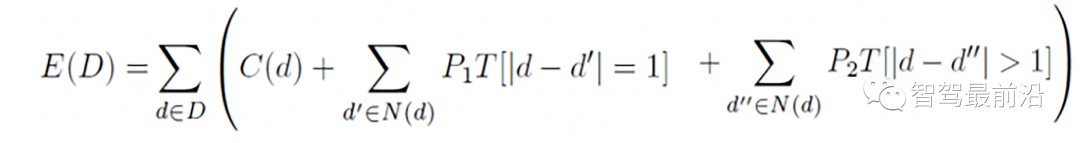
下圖是沿著水平方向的路徑最佳化函數
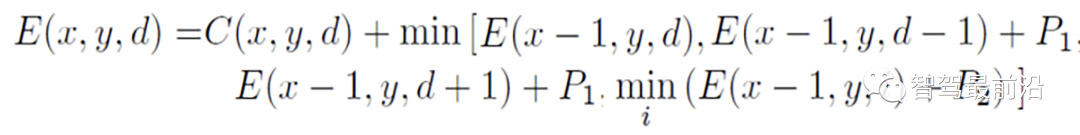
Census Transform是將8/24位元的像素變成一個2進位序列,另外一個2值特徵叫LBP(local binary pattern)和它相似。立體匹配演算法就是基於這個變換將匹配變成一個Hamming距離的最小化搜尋。 Intel的RealSense當年就是收購了一個成立於1994年基於該技術的雙眼視覺創業公司,還收購另外幾個小公司把他們合在一起做出來的。
下圖是CS變換的示意圖:
#PatchMatch是加速影像模版匹配的演算法,被用在光流計算和視差估計。之前微軟研究院曾經做過一個基於單眼手機相機3-D重建的項目,仿造以前成功的基於RGB-D演算法KinectFusion,名字也類似MonoFusion,其中深度圖估計就是採用一個修正的PatchMatch方法。
其基本想法是對視差和平面參數隨機初始化,然後透過鄰域像素之間訊息傳播更新估計。 PM演算法分為五個步驟:
- 1) 空間傳播(Spatial propagation): 每個像素檢查左邊和上邊鄰居視差和平面參數,如果匹配成本變小就取代目前估計;
- 2) 視角傳播(View propagation): 其他視角的像素做變換,檢查其對應影像的估計,如果變小就取代;
- #3) 時域傳播(Temporal propagation): 前後幀考慮對應像素的估計;
- 4) 平面細化(Plane refinement): 隨機產生樣本,如果估計使匹配成本下降,更新。
- 5) 後處理(Post-processing): 左右一致性與加權中值濾波器去除出格點(outliers)。
下圖是PM的示意圖:
#02 線上標定
再說線上標定。
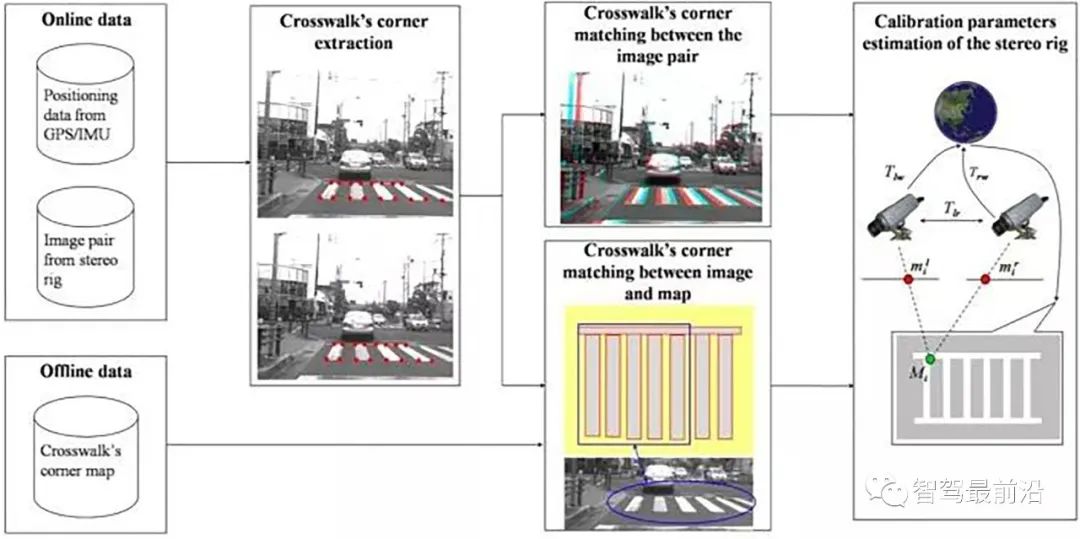
這是利用路上標誌線(斑馬線)的標定方法:已知斑馬線的平行線模式,檢測斑馬線並提取角點,計算斑馬線模式和路面實現匹配的單映性變換(Homography)參數,得到標定參數。
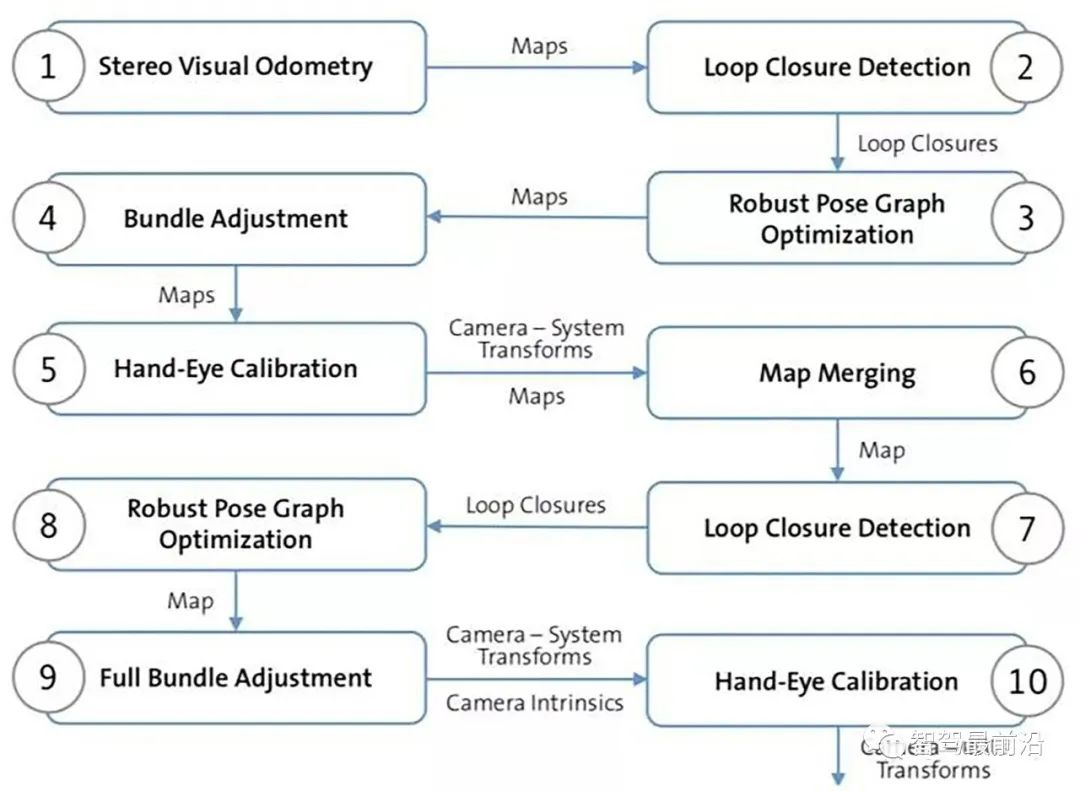
另外一個方法是基於VO和SLAM,比較複雜,不過可以同時做基於地圖的定位。採用SLAM做線上標定,不適合高頻率操作,下圖是其演算法的流程圖:1-4步, 透過立體視覺SLAM取得全域連續地圖;第5步給出雙目相機變換初始估計,第6步把所有立體相機的地圖聚合成一張地圖;7-8步取得多台相機之間的姿態。
和單目方法類似,採用車道線平行和路平面這個假設可以快速完成在線標定,即消失點(vanishing point)理論:假設一個平坦的道路模型,清晰的縱向車道線,沒有其他目標的邊緣和它們平行;要求駕駛車輛速度慢,車道線連續,左右相機的雙眼配置要左攝像頭相對路面的仰角/斜角(yaw/roll angles)比較小;這樣跟初始化的消失點(與線下標定相關)比較可以算出雙目外參數的漂移量(圖5-269),其演算法就是從消失點估計相機仰角/斜角。

03 典型的雙目自動駕駛系統
##以下介紹幾個典型的雙眼自動駕駛系統。
Berta Benz採用的障礙物偵測演算法Stixel基於以下假設:場景中的目標描述為列,重心的原因目標是站立在地面上,每個目標上的上部比下部的深度大。下圖(a-d) 介紹了SGM視差結果如何產生Stixel分割結果:
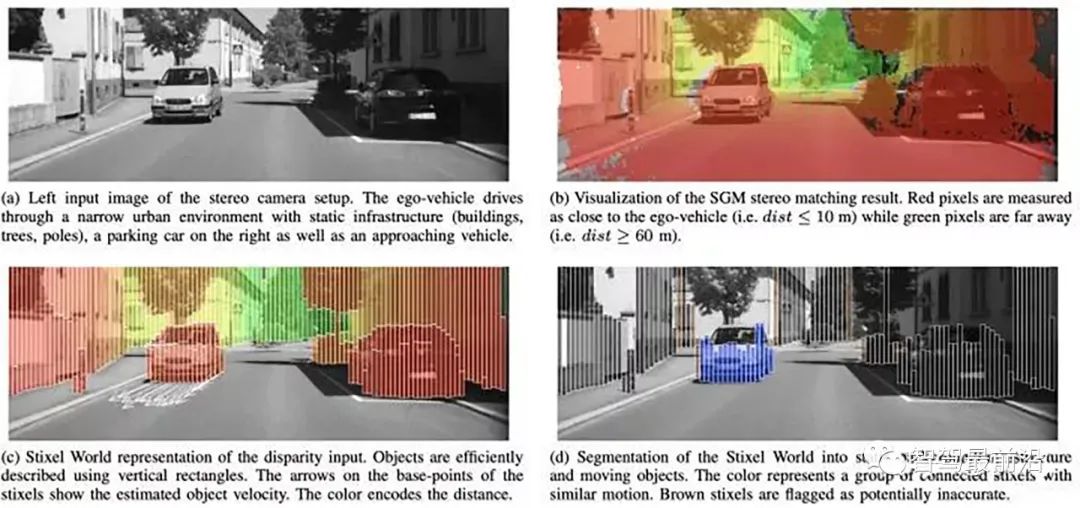
下圖是Stixels 計算的示意圖:(a)基於動態規劃的自由駕駛空間計算(b) 高度分割中的屬性值(c) 成本影像(灰階值反過來) (d) 高度分割。
這是他們加上深度學習做視差融合之後再做Stixel的框圖和新結果:

介紹一個VisLab早期雙眼障礙物的演算法,Generic Obstacle and Lane Detection system (GOLD)。基於IPM(Inverse Perspective Mapping),偵測車道線,根據左右影像的差計算路上障礙物:

##(a) Left . (b) Right (c) Remapped left. (d) Remapped right. (e) Thresholded and filtered difference between remapped views. (f) In light gray, the road area visible from both cameras.
(a) Original. (b) Remapped. (c) Filtered. (d) Enhanced. (e) Binarized.
#GOLD system architecture
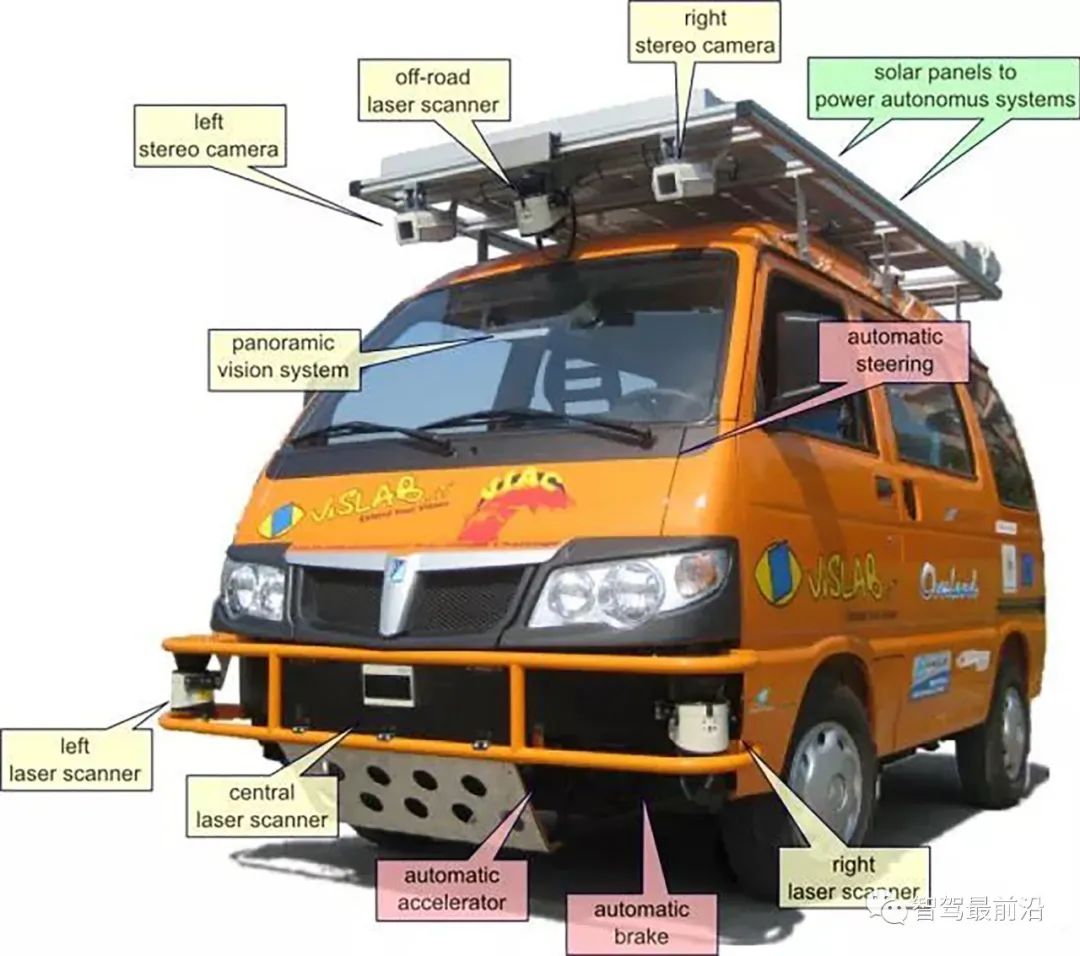
這是VisLab參加自動駕駛比賽VIAC (VisLab Intercontinental Autonomous Challenge)的車輛,除了雙眼攝影機以外,車上還有雷射雷達作為道路分類的輔助。

#
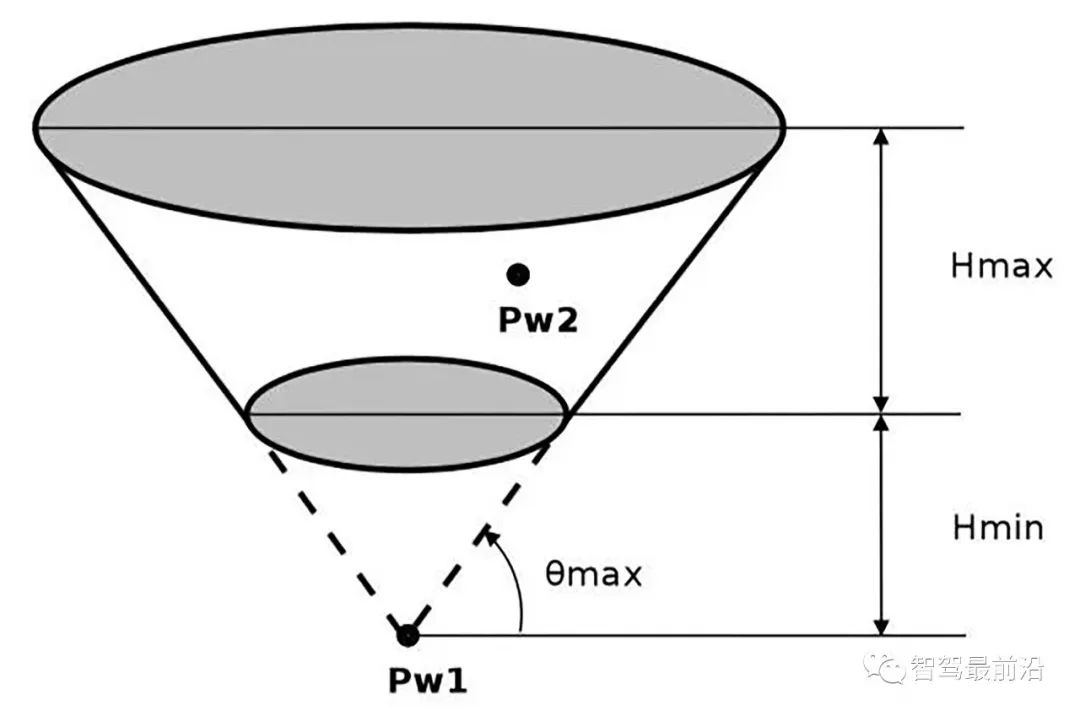
障礙物偵測演算法採用了JPL的方法,基於空間佈置特性以及車輛的物理特性聚類得到障礙物。物理特性包括最大的高度(車輛),最小高度(障礙物)和最大道路可通過範圍,這些約束定義了一個空間截斷錐(truncated cone), 如圖所示,那麼在聚類過程中凡是落在截斷錐內的點劃為障礙物。
為加速視差估計演算法,採用了分割DSI的方法:
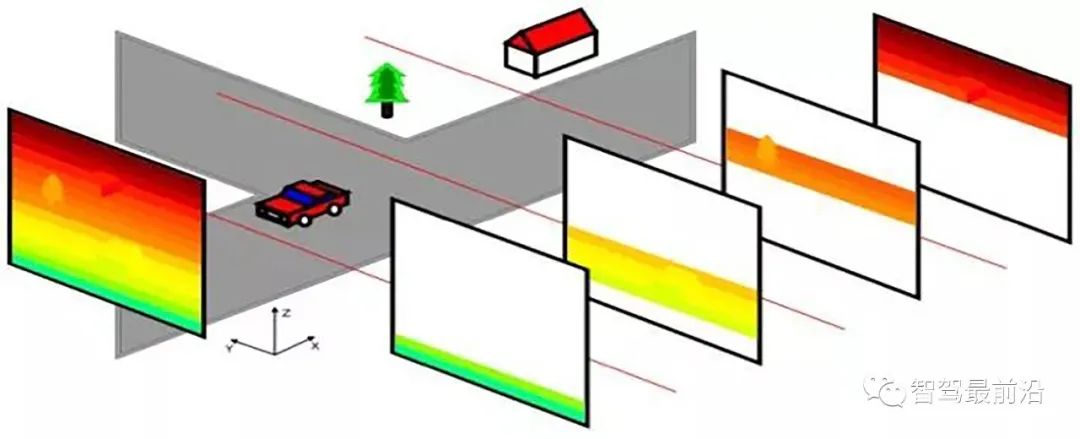
另外一種經典的方法是根據路面方程式(立體視覺)得到路面視差,基於此計算出路面的障礙物:
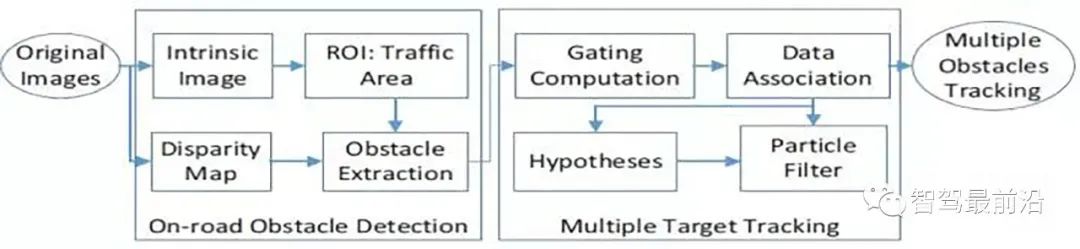

04 總結
總的看,雙眼偵測障礙物的方法基本上是基於視差圖,基於路面視差的方法較多。或許隨著深度學習發展的突飛猛進,加上運算平台的增強,雙眼自動駕駛系統也會普及。
以上是從技術層面聊聊雙目自動駕駛系統為何難以普及?的詳細內容。更多資訊請關注PHP中文網其他相關文章!