



前言
ImageNet 是一個著名的公共影像資料庫,用於訓練物件分類、偵測和分割等任務的模型,它包含超過 1,400 萬張影像。
在Python 中處理影像資料的時候,例如應用卷積神經網路(也稱為CNN)等演算法可以處理大量影像資料集,這裡就需要學習如何用最簡單的方式儲存、讀取數據。
對於影像資料處理應該有個定量的比較方式,讀取和寫入檔案需要多長時間,以及將使用多少磁碟記憶體。
分別用不同的方式去處理、解決影像的儲存、效能最佳化的問題。
資料準備
一個可以玩的資料集
我們熟知的影像資料集CIFAR-10,由60000 個32x32 像素的彩色影像組成,這些影像屬於不同的物件類別,例如狗、貓和飛機。相對而言 CIFAR 不是一個非常大的資料集,但如使用完整的 TinyImages 資料集,那麼將需要大約 400GB 的可用磁碟空間。
文中的程式碼應用程式的資料集下載位址 CIFAR-10 資料集 。
這份資料是使用cPickle進行了序列化和批次保存。不需要進行額外程式碼或轉換,pickle模組可序列化Python的任意物件。然而,處理大量數據可能會帶來無法評估的安全風險。
映像載入到 NumPy 陣列中
import numpy as np
import pickle
from pathlib import Path
# 文件路径
data_dir = Path("data/cifar-10-batches-py/")
# 解码功能
def unpickle(file):
with open(file, "rb") as fo:
dict = pickle.load(fo, encoding="bytes")
return dict
images, labels = [], []
for batch in data_dir.glob("data_batch_*"):
batch_data = unpickle(batch)
for i, flat_im in enumerate(batch_data[b"data"]):
im_channels = []
# 每个图像都是扁平化的,通道按 R, G, B 的顺序排列
for j in range(3):
im_channels.append(
flat_im[j * 1024 : (j + 1) * 1024].reshape((32, 32))
)
# 重建原始图像
images.append(np.dstack((im_channels)))
# 保存标签
labels.append(batch_data[b"labels"][i])
print("加载 CIFAR-10 训练集:")
print(f" - np.shape(images) {np.shape(images)}")
print(f" - np.shape(labels) {np.shape(labels)}")映像儲存的設定
安裝三方庫 Pillow 用於映像處理 。
pip install Pillow
LMDB
"閃電記憶體映射資料庫"(LMDB)也被稱為"閃電資料庫",因為其速度快並且使用記憶體映射檔案。它是鍵值存儲,而不是關係資料庫。
安裝三方庫 lmdb 用於映像處理 。
pip install lmdb
HDF5
HDF5 代表 Hierarchical Data Format,一種稱為 HDF4 或 HDF5 的檔案格式。這種可移植、緊湊的科學資料格式來自美國國家超級計算應用中心。
安裝三方庫 h6py 用於映像處理 。
pip install h6py
單一圖像的儲存
3種不同的方式進行資料讀取操作
from pathlib import Path
disk_dir = Path("data/disk/")
lmdb_dir = Path("data/lmdb/")
hdf5_dir = Path("data/hdf5/")同時載入的資料可以建立資料夾分開保存
disk_dir.mkdir(parents=True, exist_ok=True) lmdb_dir.mkdir(parents=True, exist_ok=True) hdf5_dir.mkdir(parents=True, exist_ok=True)
儲存到磁碟
使用Pillow 完成輸入是一個單一的映像image,在記憶體中作為一個NumPy 數組,並且使用唯一的映像ID 對其進行命名image_id。
單一影像儲存到磁碟
from PIL import Image
import csv
def store_single_disk(image, image_id, label):
""" 将单个图像作为 .png 文件存储在磁盘上。
参数:
---------------
image 图像数组, (32, 32, 3) 格式
image_id 图像的整数唯一 ID
label 图像标签
"""
Image.fromarray(image).save(disk_dir / f"{image_id}.png")
with open(disk_dir / f"{image_id}.csv", "wt") as csvfile:
writer = csv.writer(
csvfile, delimiter=" ", quotechar="|", quoting=csv.QUOTE_MINIMAL
)
writer.writerow([label])儲存到LMDB
LMDB 是一個鍵值對儲存系統,其中每個條目都儲存為一個位元組數組,鍵將是每個圖像的唯一標識符,值將是圖像本身。
鍵和值都應該是字串。常見的用法是將值序列化為字串,然後在讀回時將其反序列化。
用於重建的圖像尺寸,某些資料集可能包含不同大小的圖像會使用到這個方法。
class CIFAR_Image:
def __init__(self, image, label):
self.channels = image.shape[2]
self.size = image.shape[:2]
self.image = image.tobytes()
self.label = label
def get_image(self):
""" 将图像作为 numpy 数组返回 """
image = np.frombuffer(self.image, dtype=np.uint8)
return image.reshape(*self.size, self.channels)單一影像儲存到 LMDB
import lmdb
import pickle
def store_single_lmdb(image, image_id, label):
""" 将单个图像存储到 LMDB
参数:
---------------
image 图像数组, (32, 32, 3) 格式
image_id 图像的整数唯一 ID
label 图像标签
"""
map_size = image.nbytes * 10
# Create a new LMDB environment
env = lmdb.open(str(lmdb_dir / f"single_lmdb"), map_size=map_size)
# Start a new write transaction
with env.begin(write=True) as txn:
# All key-value pairs need to be strings
value = CIFAR_Image(image, label)
key = f"{image_id:08}"
txn.put(key.encode("ascii"), pickle.dumps(value))
env.close()儲存 HDF5
一個 HDF5 檔案可以包含多個資料集。可以建立兩個資料集,一個用於影像,一個用於元資料。
import h6py
def store_single_hdf5(image, image_id, label):
""" 将单个图像存储到 HDF5 文件
参数:
---------------
image 图像数组, (32, 32, 3) 格式
image_id 图像的整数唯一 ID
label 图像标签
"""
# 创建一个新的 HDF5 文件
file = h6py.File(hdf5_dir / f"{image_id}.h6", "w")
# 在文件中创建数据集
dataset = file.create_dataset(
"image", np.shape(image), h6py.h6t.STD_U8BE, data=image
)
meta_set = file.create_dataset(
"meta", np.shape(label), h6py.h6t.STD_U8BE, data=label
)
file.close()儲存方式比較
將保存單一影像的所有三個函數放入字典中。
_store_single_funcs = dict(
disk=store_single_disk,
lmdb=store_single_lmdb,
hdf5=store_single_hdf5
)以三種不同的方式儲存保存 CIFAR 中的第一張圖像及其對應的標籤。
from timeit import timeit
store_single_timings = dict()
for method in ("disk", "lmdb", "hdf5"):
t = timeit(
"_store_single_funcs[method](image, 0, label)",
setup="image=images[0]; label=labels[0]",
number=1,
globals=globals(),
)
store_single_timings[method] = t
print(f"存储方法: {method}, 使用耗时: {t}")來一個表格看看對比。
| 儲存方法 | 儲存耗時 | #使用記憶體 |
|---|---|---|
| Disk | 2.1 ms | 8 K |
| LMDB | 1.7 ms | 32 K |
| #HDF5 | 8.1 ms | 8 K |
#多個影像的儲存
同單一影像儲存方法類似,修改程式碼進行多個影像資料的儲存。
多重圖像調整程式碼
將多個映像儲存為.png檔案可以被視為多次呼叫store_single_method()方法。 LMDB或HDF5無法採用此方法,因為每個影像都存在於不同的資料庫檔案中。
將一組影像儲存到磁碟
store_many_disk(images, labels):
""" 参数:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
num_images = len(images)
# 一张一张保存所有图片
for i, image in enumerate(images):
Image.fromarray(image).save(disk_dir / f"{i}.png")
# 将所有标签保存到 csv 文件
with open(disk_dir / f"{num_images}.csv", "w") as csvfile:
writer = csv.writer(
csvfile, delimiter=" ", quotechar="|", quoting=csv.QUOTE_MINIMAL
)
for label in labels:
writer.writerow([label])將一組影像儲存到LMDB
def store_many_lmdb(images, labels):
""" 参数:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
num_images = len(images)
map_size = num_images * images[0].nbytes * 10
# 为所有图像创建一个新的 LMDB 数据库
env = lmdb.open(str(lmdb_dir / f"{num_images}_lmdb"), map_size=map_size)
# 在一个事务中写入所有图像
with env.begin(write=True) as txn:
for i in range(num_images):
# 所有键值对都必须是字符串
value = CIFAR_Image(images[i], labels[i])
key = f"{i:08}"
txn.put(key.encode("ascii"), pickle.dumps(value))
env.close()將一組影像儲存到HDF5
def store_many_hdf5(images, labels):
""" 参数:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
num_images = len(images)
# 创建一个新的 HDF5 文件
file = h6py.File(hdf5_dir / f"{num_images}_many.h6", "w")
# 在文件中创建数据集
dataset = file.create_dataset(
"images", np.shape(images), h6py.h6t.STD_U8BE, data=images
)
meta_set = file.create_dataset(
"meta", np.shape(labels), h6py.h6t.STD_U8BE, data=labels
)
file.close()準備資料集比較
使用100000 個影像進行測試
cutoffs = [10, 100, 1000, 10000, 100000] images = np.concatenate((images, images), axis=0) labels = np.concatenate((labels, labels), axis=0) # 确保有 100,000 个图像和标签 print(np.shape(images)) print(np.shape(labels))
建立一個計算方式進行比較
_store_many_funcs = dict(
disk=store_many_disk, lmdb=store_many_lmdb, hdf5=store_many_hdf5
)
from timeit import timeit
store_many_timings = {"disk": [], "lmdb": [], "hdf5": []}
for cutoff in cutoffs:
for method in ("disk", "lmdb", "hdf5"):
t = timeit(
"_store_many_funcs[method](images_, labels_)",
setup="images_=images[:cutoff]; labels_=labels[:cutoff]",
number=1,
globals=globals(),
)
store_many_timings[method].append(t)
# 打印出方法、截止时间和使用时间
print(f"Method: {method}, Time usage: {t}")PLOT 顯示具有多個資料集和匹配圖例的單一圖
import matplotlib.pyplot as plt
def plot_with_legend(
x_range, y_data, legend_labels, x_label, y_label, title, log=False
):
""" 参数:
--------------
x_range 包含 x 数据的列表
y_data 包含 y 值的列表
legend_labels 字符串图例标签列表
x_label x 轴标签
y_label y 轴标签
"""
plt.style.use("seaborn-whitegrid")
plt.figure(figsize=(10, 7))
if len(y_data) != len(legend_labels):
raise TypeError(
"数据集的数量与标签的数量不匹配"
)
all_plots = []
for data, label in zip(y_data, legend_labels):
if log:
temp, = plt.loglog(x_range, data, label=label)
else:
temp, = plt.plot(x_range, data, label=label)
all_plots.append(temp)
plt.title(title)
plt.xlabel(x_label)
plt.ylabel(y_label)
plt.legend(handles=all_plots)
plt.show()
# Getting the store timings data to display
disk_x = store_many_timings["disk"]
lmdb_x = store_many_timings["lmdb"]
hdf5_x = store_many_timings["hdf5"]
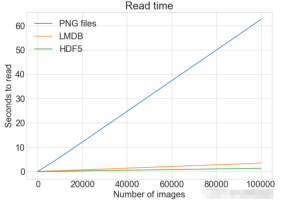
plot_with_legend(
cutoffs,
[disk_x, lmdb_x, hdf5_x],
["PNG files", "LMDB", "HDF5"],
"Number of images",
"Seconds to store",
"Storage time",
log=False,
)
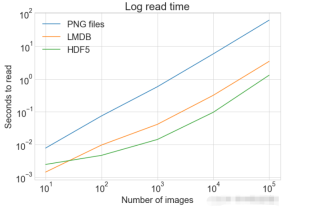
plot_with_legend(
cutoffs,
[disk_x, lmdb_x, hdf5_x],
["PNG files", "LMDB", "HDF5"],
"Number of images",
"Seconds to store",
"Log storage time",
log=True,
)

單一映像的讀取
從磁碟讀取
def read_single_disk(image_id):
""" 参数:
---------------
image_id 图像的整数唯一 ID
返回结果:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
image = np.array(Image.open(disk_dir / f"{image_id}.png"))
with open(disk_dir / f"{image_id}.csv", "r") as csvfile:
reader = csv.reader(
csvfile, delimiter=" ", quotechar="|", quoting=csv.QUOTE_MINIMAL
)
label = int(next(reader)[0])
return image, label從LMDB 讀取取
def read_single_lmdb(image_id):
""" 参数:
---------------
image_id 图像的整数唯一 ID
返回结果:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
# 打开 LMDB 环境
env = lmdb.open(str(lmdb_dir / f"single_lmdb"), readonly=True)
# 开始一个新的事务
with env.begin() as txn:
# 进行编码
data = txn.get(f"{image_id:08}".encode("ascii"))
# 加载的 CIFAR_Image 对象
cifar_image = pickle.loads(data)
# 检索相关位
image = cifar_image.get_image()
label = cifar_image.label
env.close()
return image, label從HDF5 讀取
def read_single_hdf5(image_id):
""" 参数:
---------------
image_id 图像的整数唯一 ID
返回结果:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
# 打开 HDF5 文件
file = h6py.File(hdf5_dir / f"{image_id}.h6", "r+")
image = np.array(file["/image"]).astype("uint8")
label = int(np.array(file["/meta"]).astype("uint8"))
return image, label讀取方式比較
from timeit import timeit
read_single_timings = dict()
for method in ("disk", "lmdb", "hdf5"):
t = timeit(
"_read_single_funcs[method](0)",
setup="image=images[0]; label=labels[0]",
number=1,
globals=globals(),
)
read_single_timings[method] = t
print(f"读取方法: {method}, 使用耗时: {t}")| 儲存方法 | ##。儲存耗時|
|---|---|
| 1.7 ms | |
| ##4.4 ms | |
| 2.3 ms |


以上是Python圖片儲存與存取的三種方式是什麼的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 在Python陣列上可以執行哪些常見操作?Apr 26, 2025 am 12:22 AM
在Python陣列上可以執行哪些常見操作?Apr 26, 2025 am 12:22 AMPythonarrayssupportvariousoperations:1)Slicingextractssubsets,2)Appending/Extendingaddselements,3)Insertingplaceselementsatspecificpositions,4)Removingdeleteselements,5)Sorting/Reversingchangesorder,and6)Listcomprehensionscreatenewlistsbasedonexistin
 在哪些類型的應用程序中,Numpy數組常用?Apr 26, 2025 am 12:13 AM
在哪些類型的應用程序中,Numpy數組常用?Apr 26, 2025 am 12:13 AMNumPyarraysareessentialforapplicationsrequiringefficientnumericalcomputationsanddatamanipulation.Theyarecrucialindatascience,machinelearning,physics,engineering,andfinanceduetotheirabilitytohandlelarge-scaledataefficiently.Forexample,infinancialanaly
 您什麼時候選擇在Python中的列表上使用數組?Apr 26, 2025 am 12:12 AM
您什麼時候選擇在Python中的列表上使用數組?Apr 26, 2025 am 12:12 AMuseanArray.ArarayoveralistinpythonwhendeAlingwithHomoGeneData,performance-Caliticalcode,orinterfacingwithccode.1)同質性data:arraysSaveMemorywithTypedElements.2)績效code-performance-calitialcode-calliginal-clitical-clitical-calligation-Critical-Code:Arraysofferferbetterperbetterperperformanceformanceformancefornallancefornalumericalical.3)
 所有列表操作是否由數組支持,反之亦然?為什麼或為什麼不呢?Apr 26, 2025 am 12:05 AM
所有列表操作是否由數組支持,反之亦然?為什麼或為什麼不呢?Apr 26, 2025 am 12:05 AM不,notalllistoperationsareSupportedByArrays,andviceversa.1)arraysdonotsupportdynamicoperationslikeappendorinsertwithoutresizing,wheremactsperformance.2)listssdonotguaranteeconecontanttanttanttanttanttanttanttanttanttimecomplecomecomplecomecomecomecomecomecomplecomectacccesslectaccesslecrectaccesslerikearraysodo。
 您如何在python列表中訪問元素?Apr 26, 2025 am 12:03 AM
您如何在python列表中訪問元素?Apr 26, 2025 am 12:03 AMtoAccesselementsInapythonlist,useIndIndexing,負索引,切片,口頭化。 1)indexingStartSat0.2)否定indexingAccessesessessessesfomtheend.3)slicingextractsportions.4)iterationerationUsistorationUsisturessoreTionsforloopsoreNumeratorseforeporloopsorenumerate.alwaysCheckListListListListlentePtotoVoidToavoIndexIndexIndexIndexIndexIndExerror。
 Python的科學計算中如何使用陣列?Apr 25, 2025 am 12:28 AM
Python的科學計算中如何使用陣列?Apr 25, 2025 am 12:28 AMArraysinpython,尤其是Vianumpy,ArecrucialInsCientificComputingfortheireftheireffertheireffertheirefferthe.1)Heasuedfornumerericalicerationalation,dataAnalysis和Machinelearning.2)Numpy'Simpy'Simpy'simplementIncressionSressirestrionsfasteroperoperoperationspasterationspasterationspasterationspasterationspasterationsthanpythonlists.3)inthanypythonlists.3)andAreseNableAblequick
 您如何處理同一系統上的不同Python版本?Apr 25, 2025 am 12:24 AM
您如何處理同一系統上的不同Python版本?Apr 25, 2025 am 12:24 AM你可以通過使用pyenv、venv和Anaconda來管理不同的Python版本。 1)使用pyenv管理多個Python版本:安裝pyenv,設置全局和本地版本。 2)使用venv創建虛擬環境以隔離項目依賴。 3)使用Anaconda管理數據科學項目中的Python版本。 4)保留系統Python用於系統級任務。通過這些工具和策略,你可以有效地管理不同版本的Python,確保項目順利運行。
 與標準Python陣列相比,使用Numpy數組的一些優點是什麼?Apr 25, 2025 am 12:21 AM
與標準Python陣列相比,使用Numpy數組的一些優點是什麼?Apr 25, 2025 am 12:21 AMnumpyarrayshaveseveraladagesoverandastardandpythonarrays:1)基於基於duetoc的iMplation,2)2)他們的aremoremoremorymorymoremorymoremorymoremorymoremoremory,尤其是WithlargedAtasets和3)效率化,效率化,矢量化函數函數函數函數構成和穩定性構成和穩定性的操作,製造


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

PhpStorm Mac 版本
最新(2018.2.1 )專業的PHP整合開發工具

SAP NetWeaver Server Adapter for Eclipse
將Eclipse與SAP NetWeaver應用伺服器整合。

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

VSCode Windows 64位元 下載
微軟推出的免費、功能強大的一款IDE編輯器

