
如何運用視覺大模型加速訓練和推理?

- PHPz轉載
- 2023-05-07 21:16:061631瀏覽
大家好,我是來自NVIDIA GPU 計算專家團隊的陶礪,很高興今天有機會在這裡跟大家分享一下我和我的同事陳廬,在Swin Transformer 這個視覺大模的型訓練和推理優化上的一些工作。其中一些的方法與策略,在其他的模型訓練、推理的最佳化上都可以使用,來提高模型的吞吐、提升 GPU 的使用效率、加快模型的迭代。
我會介紹Swin Transformer 模型的訓練部分的最佳化,在推理最佳化部分的工作,將由我的同事來做詳細的介紹
這裡是我們今天分享的目錄,主要分為四個部分,既然是針對特定模型進行的最佳化,那麼我們首先會簡單介紹一下Swin Transformer 模型。然後,我會結合 profiling 的工具,也就是 nsight system 來分析訓練的流程。在推理部分,我的同事會給予推理最佳化的策略和方法,包含較為細節的 cuda 層面的最佳化。最後,是今天優化內容的一個總結。

首先是第一部分,也就是 Swin Transformer 的介紹。
1. Swin Transformer 簡介
#從模型的名稱我們可以看出,這是一個基於transformer 的模型,我們先對transformer 做簡單的回顧。
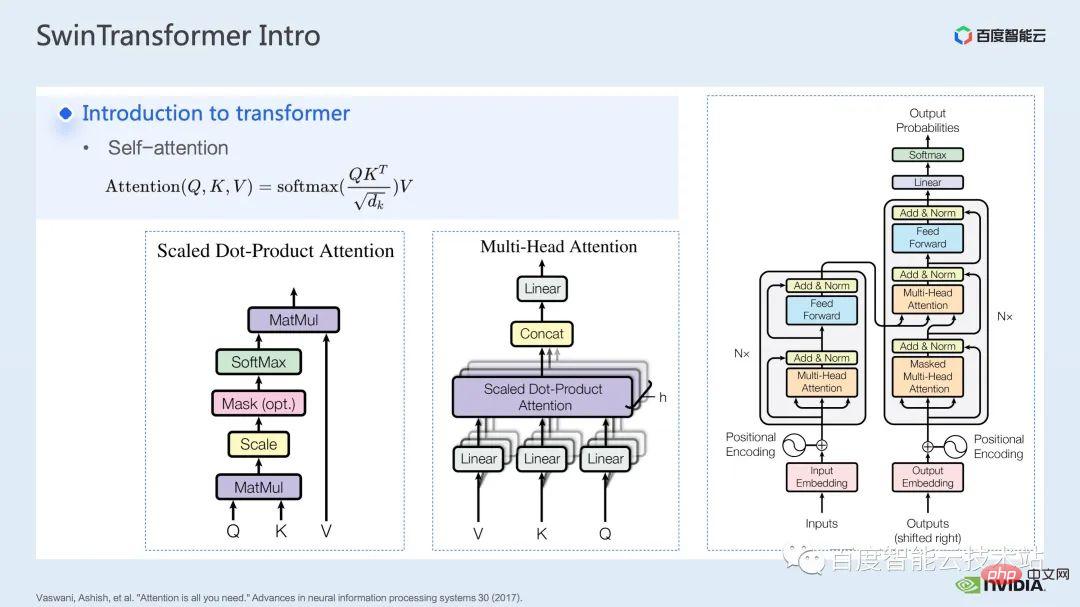
Transformer 模型從 attention is all you need 這篇文章中被提出後,在自然語言處理領域的許多任務上大放異彩。
Transformer 模型的核心就是所謂的注意力機制,也就是 attention mechanism。對於注意力模組,通常的輸入是 query,key 和 value 三個張量。透過query 和key 的作用,加上softmax 的計算,可以得到通常被稱為attention map 的注意力結果,根據attention map 中的數值的高低,模型就可以學習到需要更加註意value 中的哪些區域,或者說模型可以學習到,value 中的哪些數值對我們的任務有很大的幫助。這就是最基礎的單頭注意力模型。
我們透過增加這樣單頭注意力的模組的數量,也就可以構成常見的多頭注意力模組。常見的 encoder、decoder 都是基於這樣的多頭注意力模組搭建的。
許多模型通常包含了 self-attention,cross-attention 這兩種注意力模組,或是一個或多個模組的堆疊。如著名的 BERT 就是由多個 encoder 模組組成,現在大熱的 diffusion 模型通常同時包含了 self-attention 和 cross-attention。
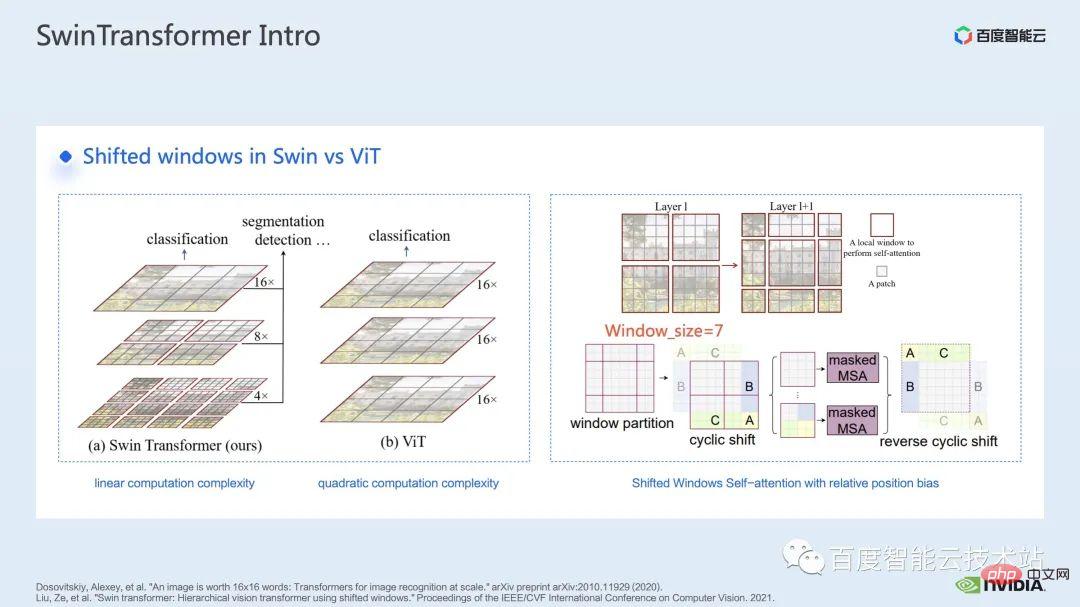
在 Swin Transformer 之前,Vision Transformer (ViT) 首先將 transformer 應用到了電腦視覺領域。 ViT 的模型結構,如下圖左側所示,ViT 會將一個影像分割成一系列的patch,每一個patch 類比於自然語言處理中的token,然後透過一個Transformer-based 的encoder 對這一系列patch 進行encode ,最後得到可用於分類等任務的feature。
而來到Swin Transformer,它引入了window attention 的概念,不同於ViT 對整個圖像進行attention,Swin Transformer 會先將圖像劃分成若干個window,然後僅對window 內部的patch 進行attention,從而減少運算量。
#為了彌補 window 帶來的邊界問題,Swin Transformer 進一步引入 window shift 的操作。同時為了讓模型有更豐富的位置訊息,在 attention 時也引入了 relative position bias。其實這裡的 window attention 和 window shift,就是 Swin Transformer 中的 Swin 名稱的由來。
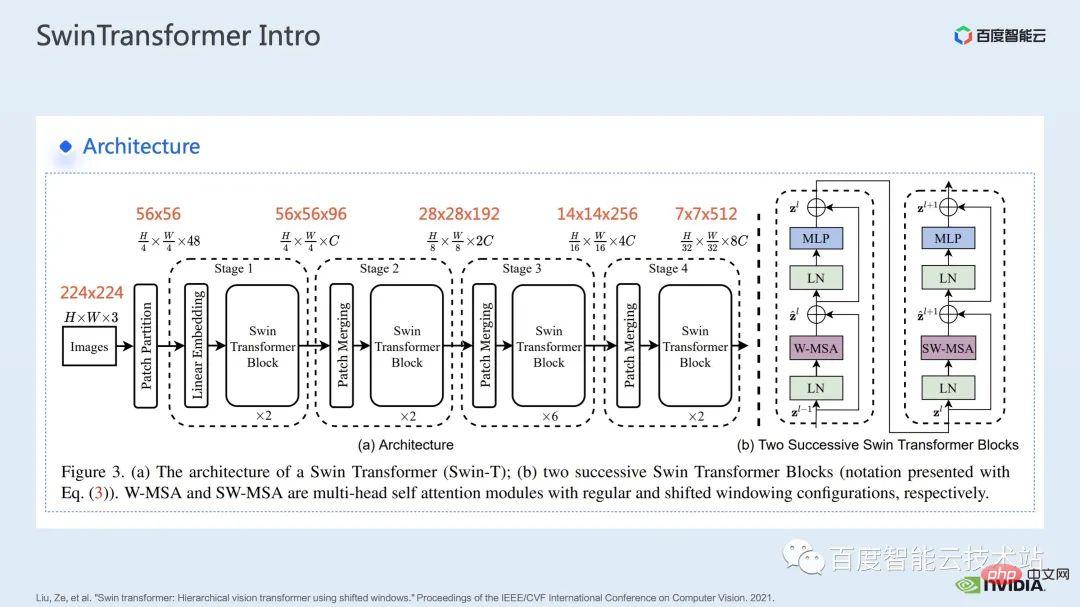
這裡給的是Swin Transformer 的網路結構,大致上的一個網路結構和傳統的CNN 如ResNet 十分相近。
可以看到整個網路結構被分割成多個 stage,在不同 stage 中間,會有對應的降採樣的過程。每個 stage 的分辨率是不一樣的,從而形成了一個分辨率金字塔,這也使得每個 stage 的計算複雜程度也逐漸降低。
然後每個 stage 中會有若干個 transformer block。每一個 transformer block 中,就會用到上面提到的 window attention 模組。
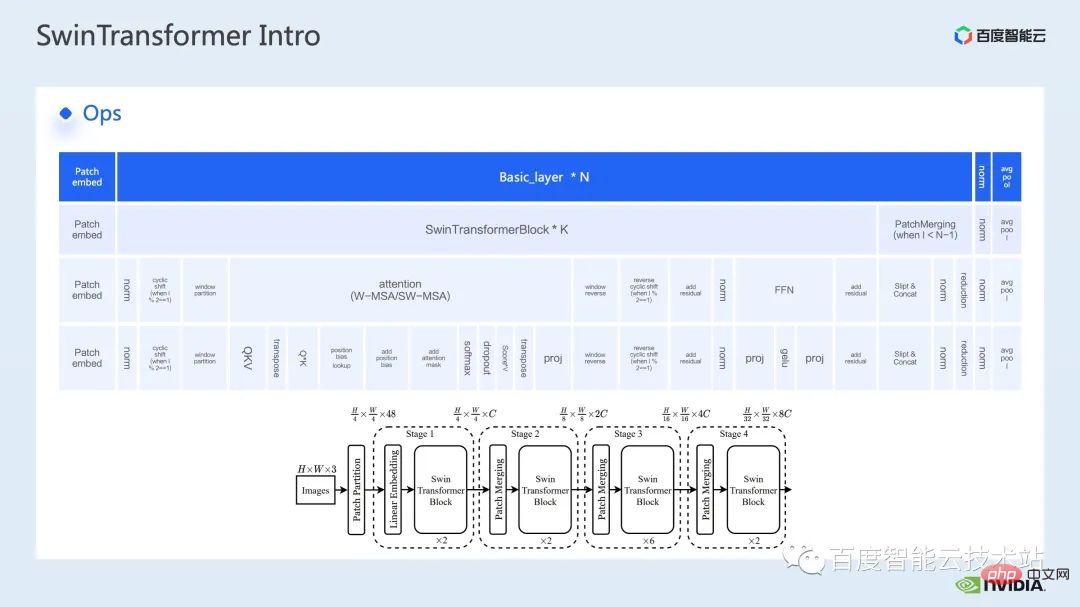
接下來,我們從具體操作的角度來對 Swin Transformer 進行解構。
可以看到,一個transformer block 中涉及到三大部分,第一部分是window shift/partition/reverse 的window 相關的操作,第二部分是attention 計算,第三部分是FFN 計算;而attention 和FFN 部分又可以進一步細分為若個op,最終我們可以將整個模型細分為幾十個op 的組合。
這樣的算符分割對於我們進行效能分析,定位效能瓶頸以及進行加速最佳化而言,都是非常重要的。
以上就是第一部分的介紹。接下來,讓我們來介紹一下在訓練上我們進行的一些優化工作,特別的,我們結合 profiling 工具,也就是 nsight system,對整體的訓練流程做一個分析和優化。
2. Swin Transformer 訓練最佳化
##對於大模型的訓練而言,通常會用到多卡、多節點的運算資源。針對Swin Transformer,我們發現卡間通訊的開銷佔比會相對較少,隨著卡數的增長,整體速度的提升幾乎呈現線性的增長,所以在這裡,我們優先對單GPU 上的計算瓶頸進行分析和優化。
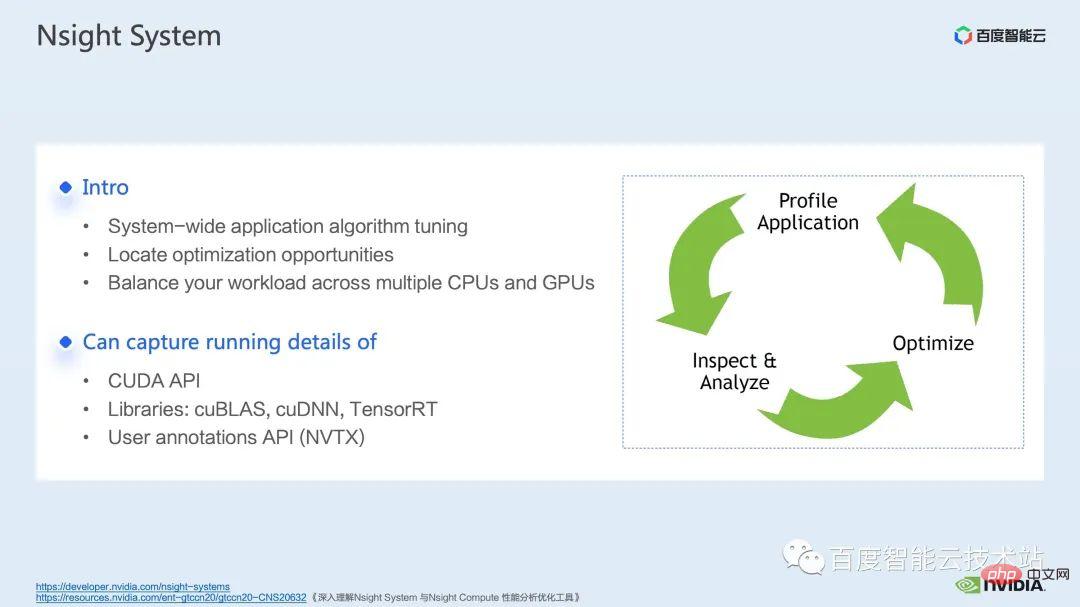
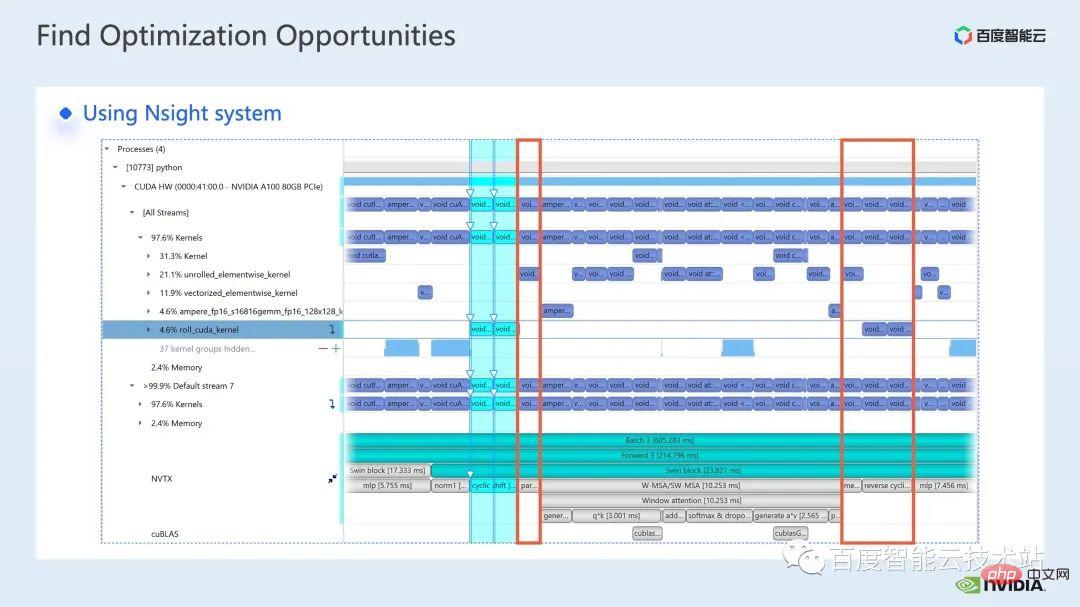
nsight system 是一個系統層面的效能分析工具,透過這個工具,我們可以很方便的看到模型的各個模組的GPU 的使用情況,是否存在資料等待等可能存在的效能瓶頸和最佳化空間,可以便於我們合理的規劃CPU、GPU 之間的負載。
nsight system 可以捕捉CUDA,以及一些gpu 計算程式庫如cublas,cudnn,tensorRT 等調用的核(kernel)函數的呼叫和運行情況,以及可以方便使用者添加一些標記,來統計標記範圍內對應gpu 的運作情況。
一個標準的模型最佳化流程如下圖所示,我們對模型進行profiling,拿到效能分析報告,發現效能最佳化點,然後有針對性的去做性能調優。
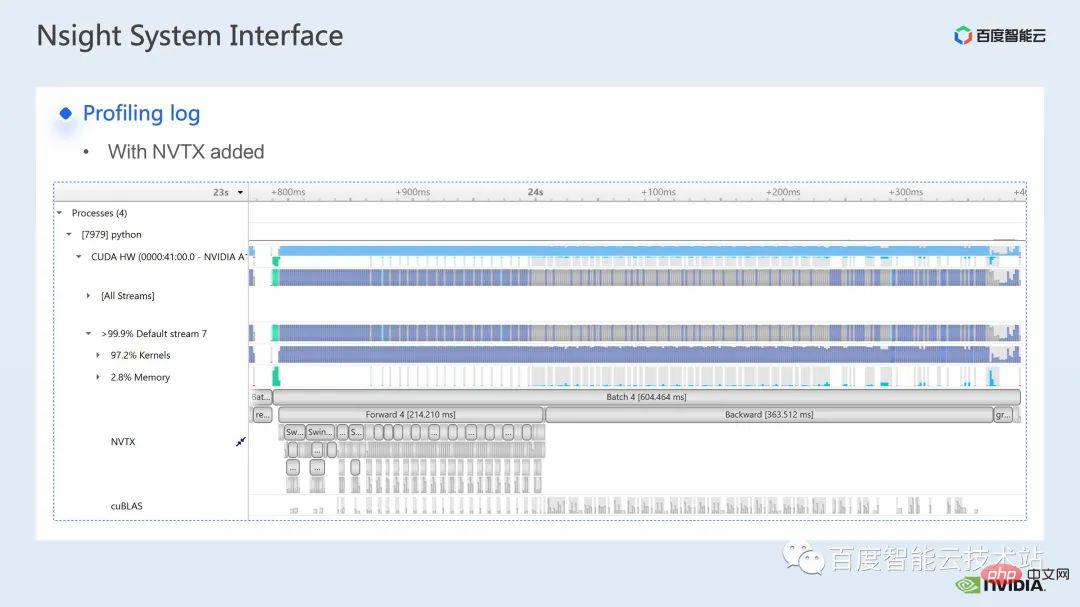
這裡有一個 nsight system 的介面,我們可以很清楚地看到核函數的發射,也就是 kernel launch;核函數的運行,也就是這裡的 runtime 部分。對於具體的核函數,我們可以看到在整個流程中的時間佔比,以及 gpu 是否存在空閒等資訊。在加入 nvtx 標記之後,我們可以看到模型前向,反向所需的時間。
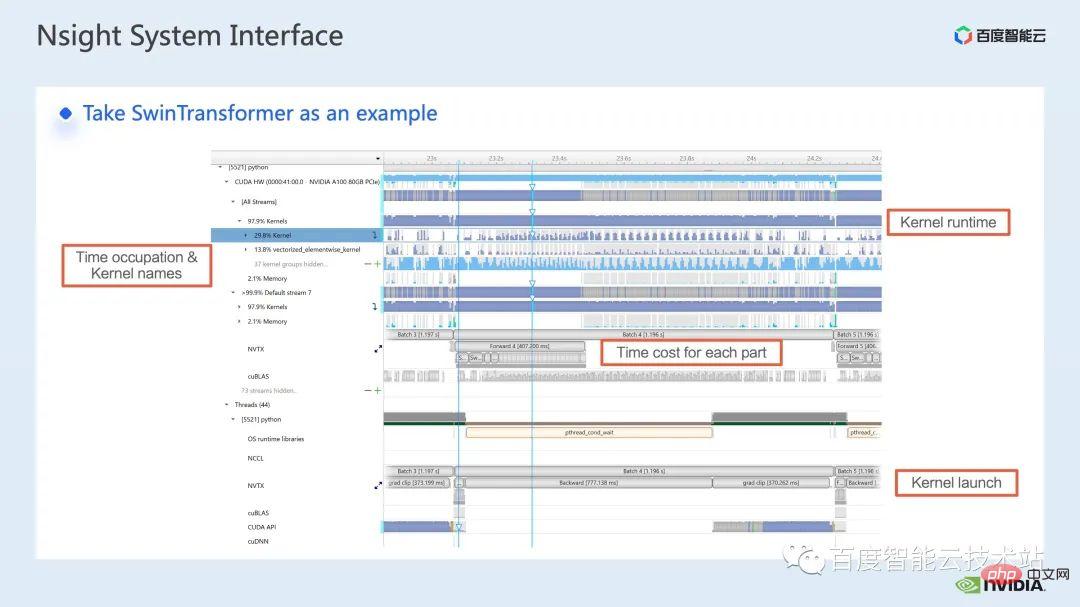
在前向部分,如果放大,我們也可以清楚地看到特定每個SwinTransformer Block 的計算需要的時間。
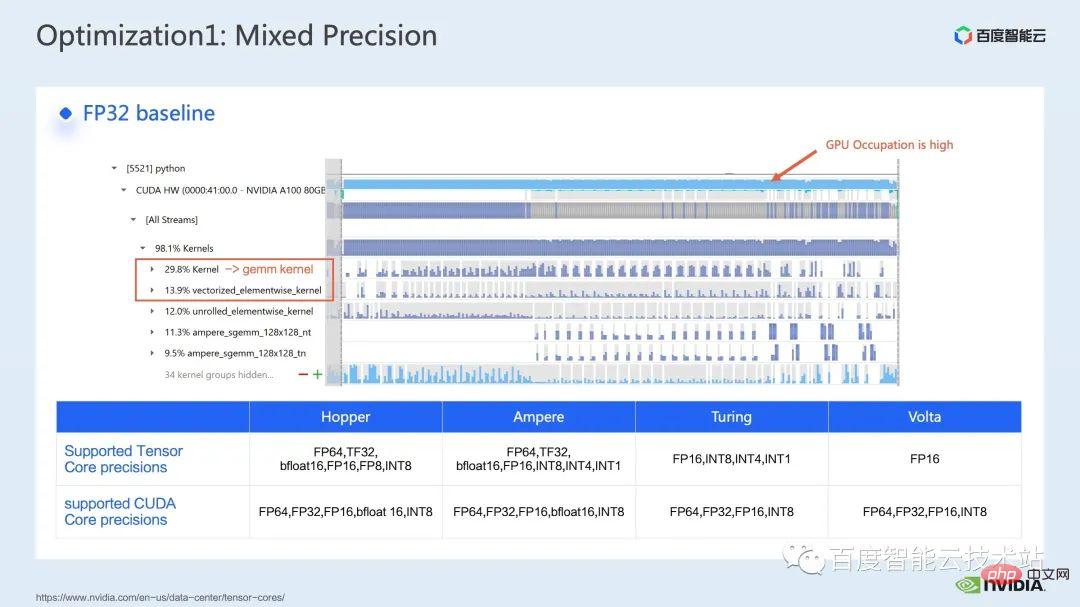
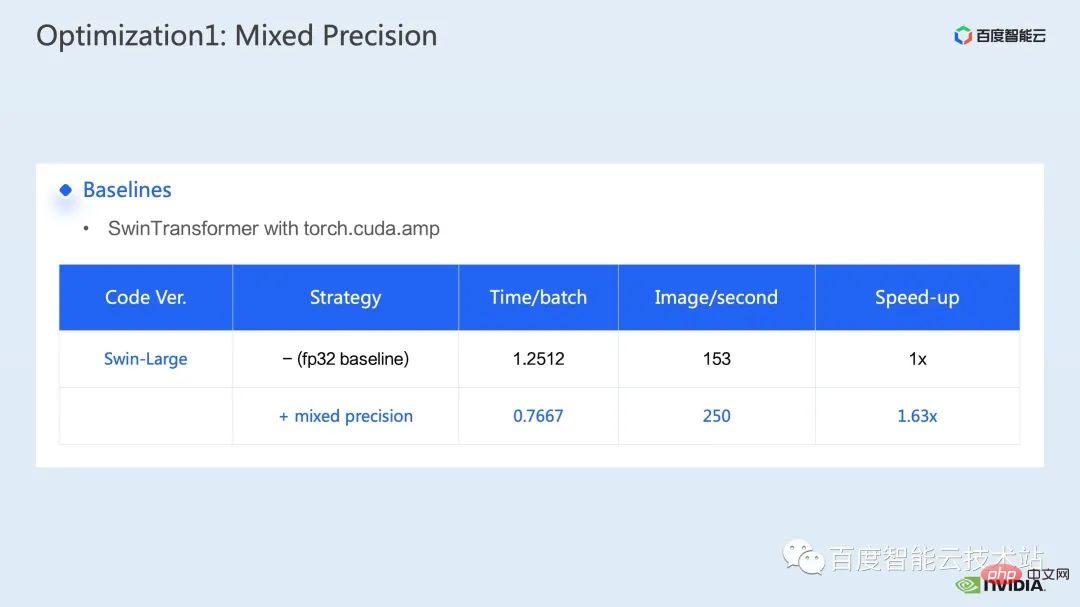
我們先透過nsight system 效能分析工具來看整個baseline 的效能表現,下圖展示的就是FP32 的baseline,可以看到它的GPU 使用率是很高的,而其中佔比最高的是矩陣乘的kernel。
那麼對於矩陣乘法而言,我們的一個最佳化手段,就是充分利用 tensor core 進行加速。
我們知道 NVIDIA 的 GPU 內有 cuda core 和 tensor core 這樣的硬體資源,tensor core 是專門為了矩陣乘法的加速的模組。我們可以考慮直接採用 tf32 tensor core 或混合精準度下,採用 fp16 tensor core。要知道,使用 fp16 的 tensor core 在矩陣乘法上的吞吐,會比 tf32 高,對比純 fp32 的矩陣乘也會有很高的加速效果。
在此,我們採用了混合精確度的方案。透過採用 torch.cuda.amp 的混合精度的模式,我們可以取得了 1. 63 倍的吞吐提升。
在profiling 的結果裡也能夠很清楚地看到,原本佔最高的矩陣乘,經過最佳化後,在整個timeline 中的佔比降到了11.9%。至此,佔比較高的 kernel 都是 elementwise kernel。
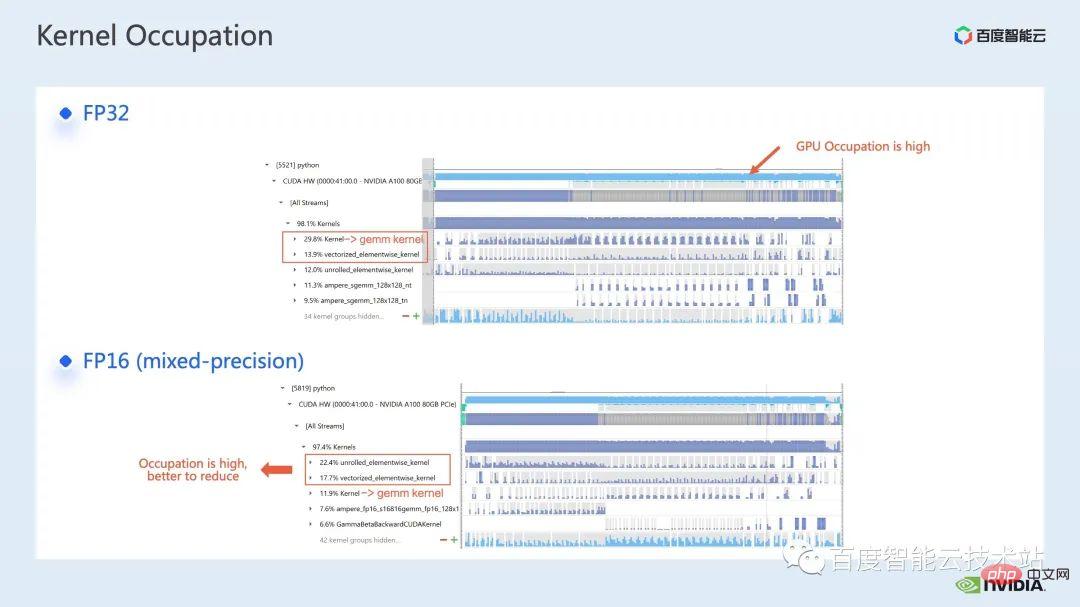
對於 elementwise kernel,我們首先要了解哪裡會用到 elementwise 的 kernel。
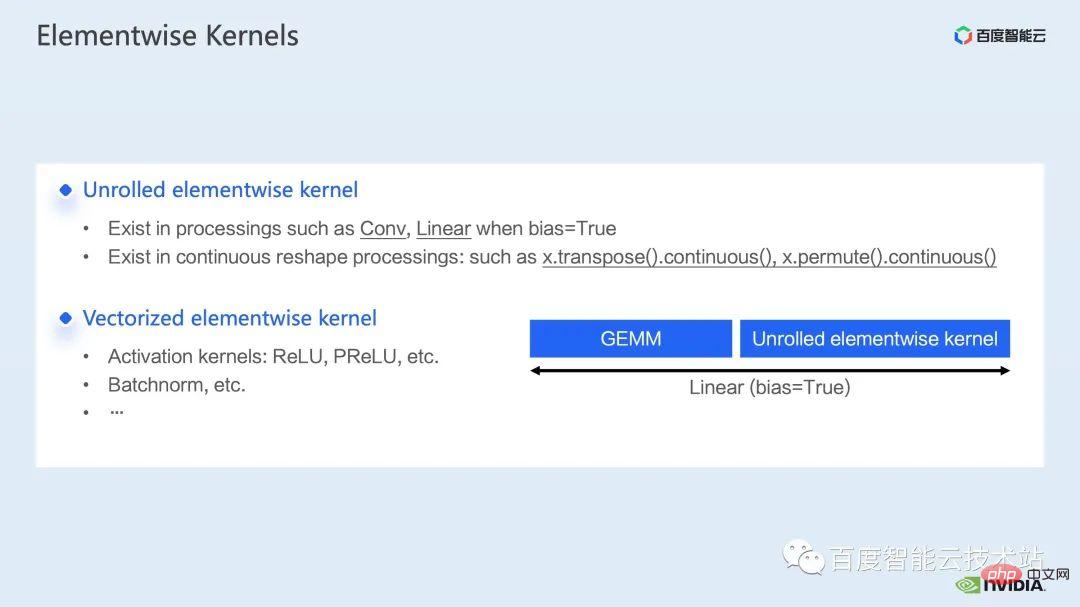
Elementwise kernel 裡,比較常見的 unrolled elementwise kernel 和 vectorized elementwise kernel。其中 unrolled elementwise kernel 廣泛存在於一些有偏置的捲積,或線性層中,以及一些保證資料在記憶體連續性的 op 中。
vectorized elementwise kernel 則常出現在一些激活函數,如 ReLU 的計算中。如果想要減少這裡大量的 elementwise kernel,一個常見的做法是做算子融合,例如矩陣乘法中,我們可以透過將 elementwise的操作與矩陣乘法的算子融合在一起,來降低這部分的時間開銷。
對於算子融合,一般而言可以為我們帶來兩個好處:
一個是減少kernel launch 的開銷,如下圖所示,兩個cuda kernel 的執行需要兩次launch,那樣可能會導致kernel 之間存在gap,使得GPU 空閒,那麼如果我們將兩個cuda kernel 融合成一個cuda kernel,一方面節省了一次launch,同時也可以避免gap 的產生。
#另一個好處是減少了global memory 的訪問,因為global memory 的訪問是非常耗時的,而兩個獨立的cuda kernel 之間要進行結果傳遞,都需要通過global memory ,將兩個cuda kernel 融合成一個kernel,我們可以在暫存器或share memory 上進行結果傳遞,從而避免了一次global memory 寫入和讀,提升效能。

對於算子融合,我們第一步是採用現成的apex 函式庫來進行Layernorm 和Adam 中操作的融合,可以看透過簡單的指令替換,我們可以使能apex 的fused layernorm 和 fused Adam,從而使得加速從1.63 倍提升至2.11 倍。

從profling 的日誌我們也可以看到,經過算子融合之後,elementwise kernel 在這個timeline 的佔比大幅降低,矩陣乘法重新成為時間佔比最大的kernel。
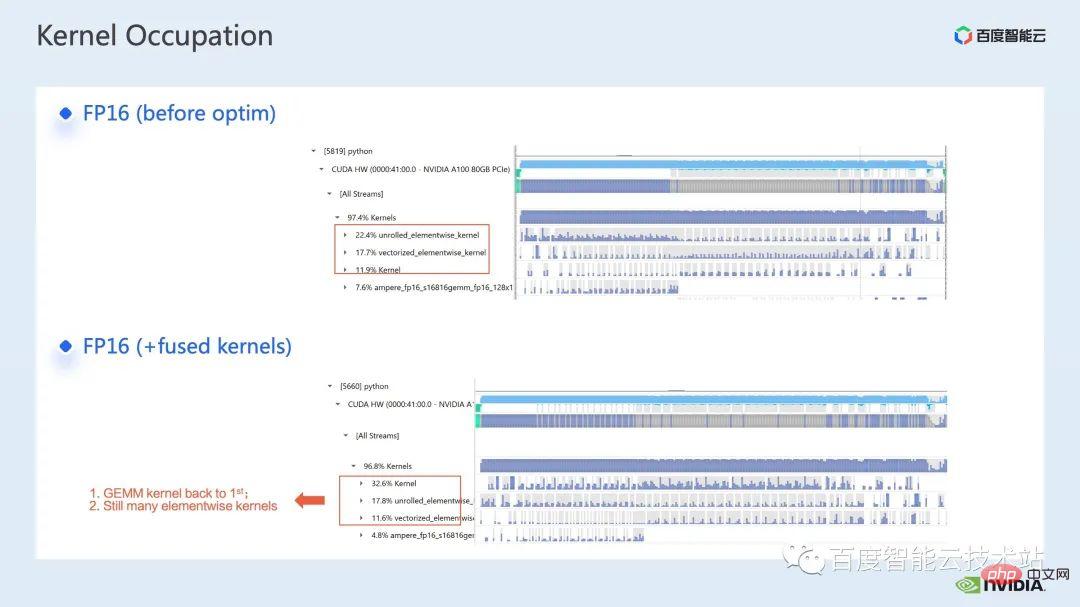
除了利用現有的 apex 函式庫,我們也進行了手工的融合算符開發。
透過觀察timeline,以及對模型的理解,我們發現Swin Transformer 中有特有的window 相關操作,如window partition/shift/merge 等,這裡的一次window shift,需要呼叫兩個kernel,並在shift 完成之後呼叫elementwise 的kernel。並且,attention 模組前如果需要做一次這樣的操作,那麼之後會有對應的 reverse 操作。這裡單單 window shift 呼叫的 roll_cuda_kernel 就在整個 timeline 中佔 4.6%。
剛才提到的這些操作,其實只是對資料進行了劃分,也就是對應的資料會被劃分到一個window 中去,對應的原始程式碼如下圖。

我們發現,這部分的操作其實本質上只是index mapping,因此,我們對這一部分進行的融合算子開發。開發的過程,我們需要掌握 CUDA 程式設計的相關知識,並且寫出算子的前向計算和反向計算的相關程式碼。
如何在pytorch 中引入自訂算子,官方給出了教程,我們可以按照教程編寫CUDA 程式碼,編譯好後就可以作為一個模組引入原始的模型。可以看到,透過引入我們的客製化融合算子,我們可以將加速比進一步提升至 2.19 倍。

接下來展示的是,我們對 mha 部分的融合工作。
Mha 部分是 transformer 模型中一個佔比很大的模組,因此對它的最佳化往往可以帶來較大的加速效果。從圖中可以看到,在沒有進行算子融合之前,mha 部分的操作佔比為 37.69%,其中包括了不少 elementwise 的 kernel。如果我們能夠將相關操作整合成一個獨立的 kernel,並且具有更快的速度,加速比可以進一步提升。
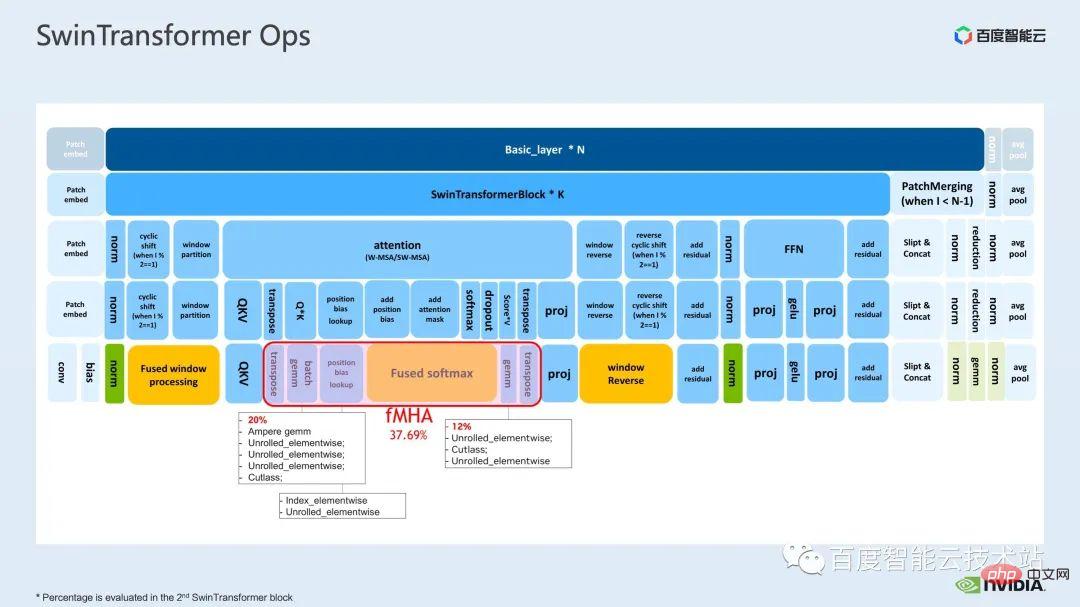
对于 Swin Transformer,这部分的模块除了 query,key 和 value 外,mask 和 bias 都是以 tensor 的形式传入的,我们开发了 fMHA 这样的一个模块,可以将原本的若干 kernel 融合起来。从 fMHA 这个模块涉及到的计算来看,针对 Swin Transformer 中遇到的一些 shape,该模块都有比较显著的提升。

模型用上 fMHA 模块后,我们可以将加速比进一步提升 2. 85 倍。上述是我们在单卡上取得的训练加速效果,那么我们来看一下单机 8 卡的训练情况,可以看到,通过上述优化,我们可以将训练吞吐从 1612 提升至 3733,取得 2.32 倍的加速。

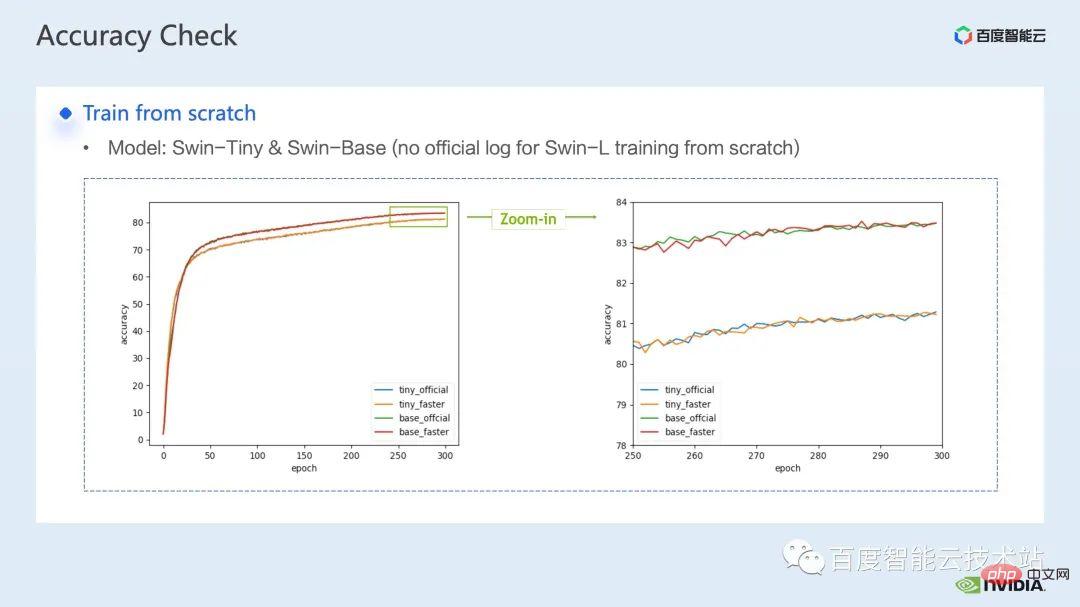
对于训练优化而言,加速比我们希望越高越好,对应的,我们也希望加速后的性能能够与加速前保持一致。
叠加上上述若干加速方案后,可以看到,模型的收敛性与原始的 baseline 保持一致,优化前后的模型的收敛、精度的一致性,在 Swin-Tiny,Swin-Base 以及 Swin-Large 上都得到了验证。
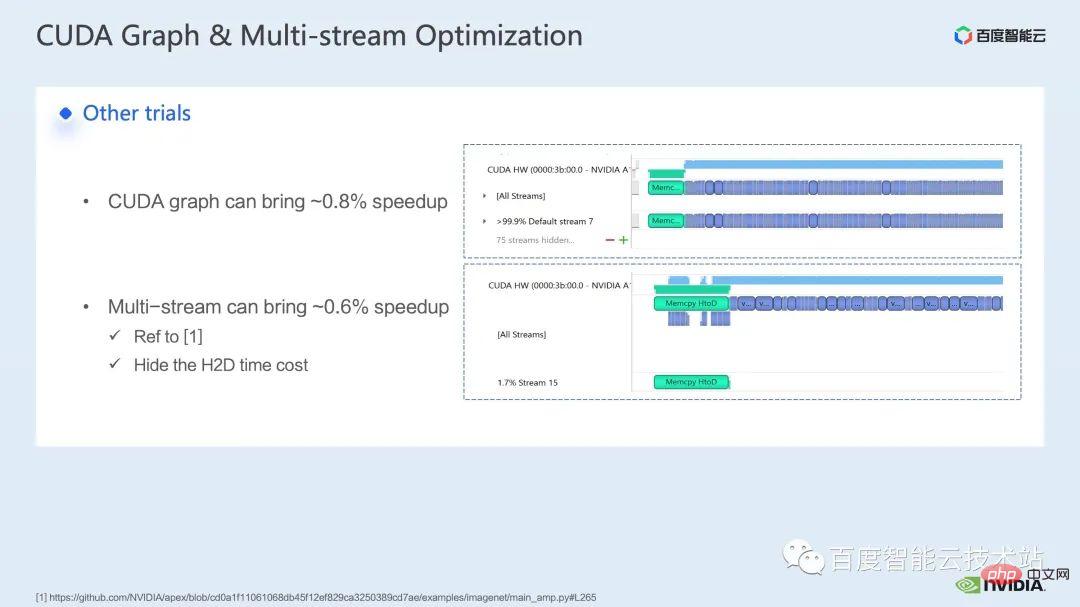
关于训练部分,一些其他的加速策略包括 CUDA graph、multi-stream 等,都能对 Swin Transformer 的性能有进一步提升;其他方面,目前我们介绍的是使用混合精度的方案,也就是 Swin Transformer 官方 repo 采用的策略;使用纯 fp16 的方案(即 apex O2 模式)可以达到更快的加速效果。
虽然 Swin 对通信的要求不高,但是对于多节点大模型的训练,相比于原始的分布式训练,使用合理的策略去隐藏通信的开销,能够在多卡训练上获得进一步的收益。
接下来,有请我的同事来介绍一下我们在推理上的加速方案和效果。
3. Swin Transformer 推理优化
大家好,我是来自英伟达 GPU 计算专家团队的陈庾,非常感谢陶砺在训练加速上的介绍,接下来由我来介绍一下推理上的加速。
跟训练一样,推理的加速离不开算子融合这一方案。不过相对于训练而言,在推理上进行算子融合有更好的灵活性,主要体现有两点:
- 推理上的算子融合不需要考虑反向,所以 kernel 开发过程中不需要考虑保存计算梯度所需要的中间结果;
- 推理过程允许预处理,我们可以对一些只需要一次计算便可重复使用的操作,提前算好,保留结果,每次推理时直接调用从而避免重复计算。
在推理侧,我们可以进行不少的算子融合,这里给出的是我们在 Transformer 模型中常见的一些算子融合的 pattern 以及实现相关 pattern 所需要用到的工具。
首先,我們單獨列出矩陣乘法和卷積,是因為有一大類算子融合是圍繞他們進行的,對於矩陣乘法相關的融合,我們可以考慮採用cublas,cutlass, cudnn 這三個函式庫;對於卷積,我們可以採用cudnn 或cutlass。那麼對於矩陣乘法的算子融合而言,在Transformer 模型中,我們歸納為gemm elementwise 的操作,例如gemm bias, gemm bias 激活函數等,這一類的算子融合,我們可以考慮直接調用cublas 或cutlass來實現。
此外,如果我們gemm 之後的op 運算比較複雜,例如layernorm,transpose 等,我們可以考慮將gemm 和bias 分開,然後把bias 融合到在下一個op 中,這樣可以更為容易地呼叫cublas 來實現簡單的矩陣乘法,當然這種bias 和下一個op 進行融合的pattern 一般是需要我們手寫cuda kernel 來實現。
最後,有些特定 op,同樣需要我們以手寫 cuda kernel 的方式進行融合,例如 layernorm shift window partition。
由於算符融合需要我們比較巧妙地設計cuda kernel,所以我們一般建議先透過nsight system 效能分析工具對整體pipeline 進行分析,優先針對熱點模組進行算子融合優化,以達到效能和工作量的平衡。

那麼在眾多的算子融合最佳化中,我們挑選了兩個加速效果比較明顯的算符進行介紹。
首先是mha 部分的算子融合,我們將position bias lookup 這一操作提前到預處理部分,從而避免每次推理時都進行lookup 。
然後將batch gemm,softmax,batch gemm 融合成一個獨立的fMHA kernel,同時我們把transpose 相關的操作融合到了fMHA kernel I/O 操作中,透過一定的資料讀寫的pattern 來避免明確的transpose 操作。
可以看到,融合後該部分取得了 10 倍的加速,而端到端也取得了 1.58 倍的加速。
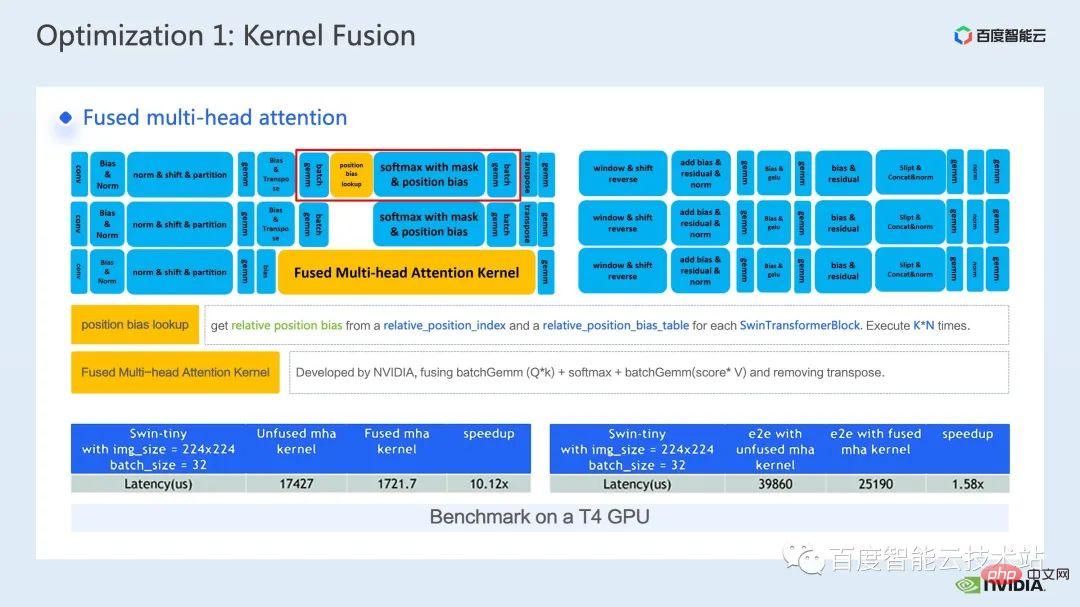
另一個我想介紹一下的算子融合是 QKV gemm bias 的融合。
gemm 和bias 的融合是十分常見的融合手段,在這裡為了配合我們前面提到的fMHA kernel,我們需要對weight 和bias 提前進行格式上的變換。
我之所以在這裡選擇介紹這個算子融合,也正是因為這個提前變換體現了我們前面提到的,推理上進行算子融合的彈性,我們可以對模型的推理流程做一些不影響其精確度的變化,從而實現更好算子融合pattern,取得更好的加速效果。
最後,透過 QKV gemm bias 的融合,我們可以進一步取得 1.1 倍的端對端加速。
下一個最佳化手段是矩陣乘法 padding。
#在Swin Transformer 的計算中,有時候我們會遇到主維為奇數的矩陣乘法,這時候並不利於我們的矩陣乘法kernel 進行向量化讀寫,從而使得kernel 的運作效率變低,此時我們可以考慮對參與運算的矩陣主維進行padding 操作,使其變為8 的倍數,這樣一來,矩陣乘kernel 就可以以alignment=8,一次讀寫8 個元素的方式來進行向量化讀寫,提升效能。
如下表所示,我們將n 從49 padding 到56 後,矩陣乘法的latency 從60.54us 下降為40.38us,取得了 1.5 倍的加速比。

下一個最佳化手段是巧用 half2 或 char4 這樣的資料型別。
以下的程式碼是一個half2 優化的範例,它實現的是一個簡單的加bias 再加殘差這樣的算子融合操作,可以看到透過使用half2 資料型,相對於half 資料類,我們可以將latency 從20.96us 下降到10.78us,加速1.94 倍。
那麼採用 half2 資料型別一般有什麼好處呢?主要有三點:
第一個好處是向量化讀寫可以提升memory 的頻寬利用效率並降低訪存指令數;如下圖右側所示,透過half2 的使用,訪存指令減少了一半,同時memory 的SOL 也有顯著提升;
第二個好處是結合half2 專有的高吞吐的數學指令,可以減低kernel 的latency。這兩點都已經體現在了這個範例程式中;
第三個好處是在進行reduction 相關kernel 開發時,採用half2 資料型別意味著一個cuda 執行緒同時處理兩個元素,可以有效減少空閒的執行緒數,也可以減少執行緒同步的latency。

下一個最佳化手段是巧用暫存器陣列。
在我們進行layernorm 或softmax 等Transformer 模型常見的算子最佳化時,我們經常需要在一個kernel 中多次使用同一個輸入數據,那麼相對於每次都從global memory 讀取,我們可以採用寄存器數組來緩存數據,從而避免重複讀取global memory。
由於暫存器是每個cuda 執行緒獨佔的,所以在進行kernel 設計時,我們需要事先設定好每個cuda 執行緒所需要快取的元素個數,從而開闢對應大小的寄存器數組,並且在分配每個cuda 線程所負責元素時,需要確保我們可以做到合併訪問,如下圖右上側所示,當我們有8 個線程時,0 號線程可以處理0 號元素,當我們有4 個線程是,0 號線程則處理0 號和4 號元素,如此類推。
我們一般建議可以採用模板函數的方式,透過模板參數來控制每個cuda 執行緒的暫存器陣列大小。
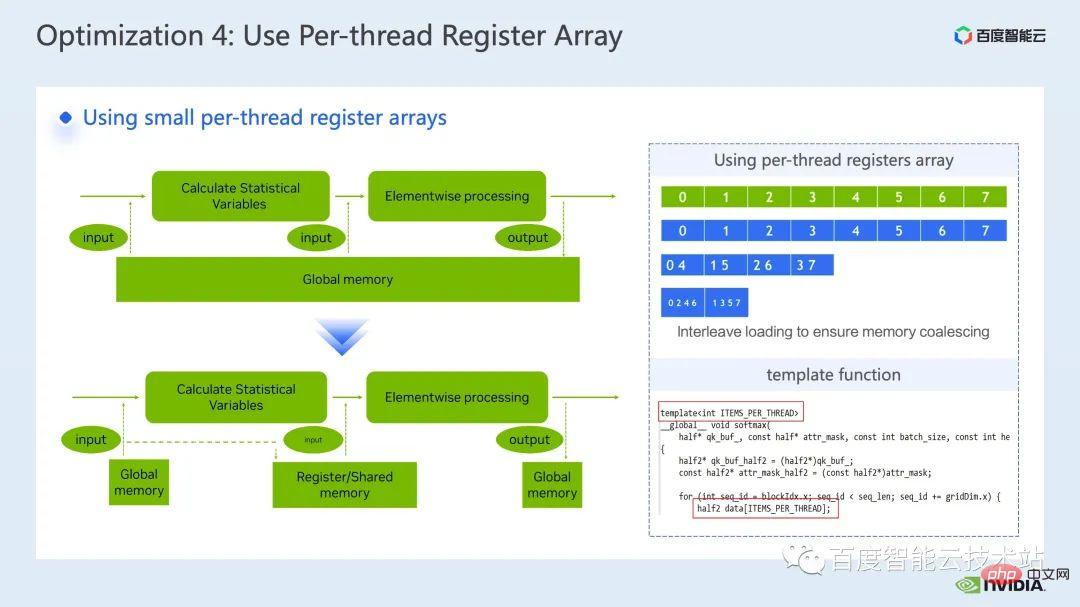
此外,在使用暫存器陣列時,需要確保我們的下標是常數,如果是循環變數作為下標,我們應該盡量保證可以進行循環展開,這樣可以避免編譯器將資料放到了latency 很高的local memory 中,如下圖所示,我們在循環條件中添加限制,透過ncu report 可以看到,避免了local memory 的使用。

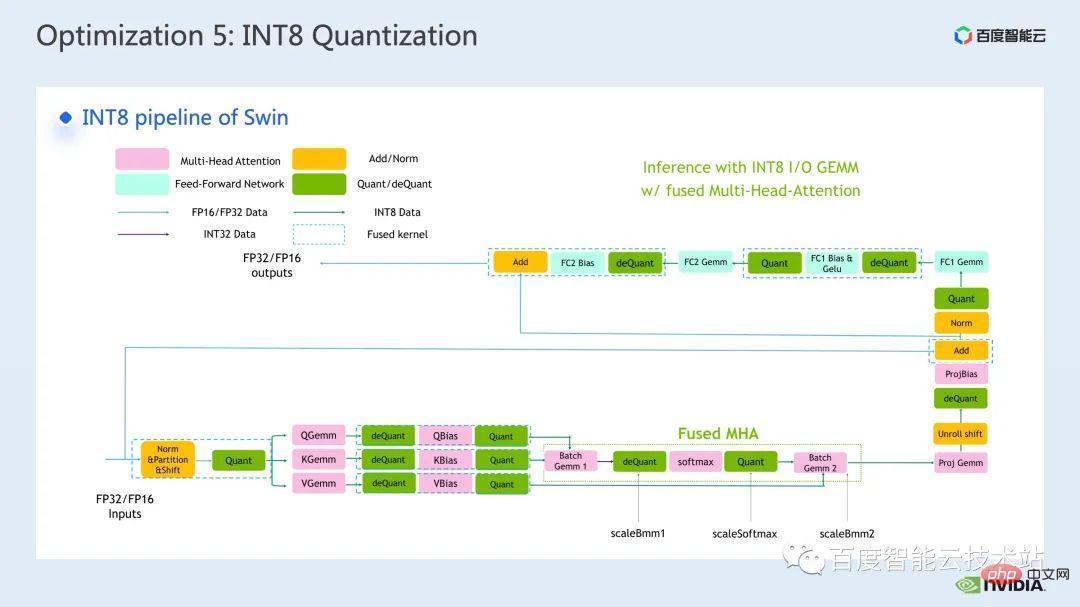
最後一個我想介紹最佳化手段是 INT8 量化。
INT8 量化是推理加速非常重要的加速手段,對於Transformer based 的模型而言,INT8 量化可以在減少顯存消耗的同時帶來更好的性能。
而對於 Swin 來說,透過結合合適的 PTQ 或 QAT 量化方案,可以在取得良好加速的同時,保證量化精度。一般我們會進行int8 量化,主要是將矩陣乘法或卷積進行量化,例如int8 矩陣乘法中,我們會先將原始的FP32 或FP16 的input 和weight 量化為INT8 然後再進行INT8 矩陣乘法,累加到INT32 資料類型上,這是我們會進行反量化操作,得到FP32 或FP16 的結果。

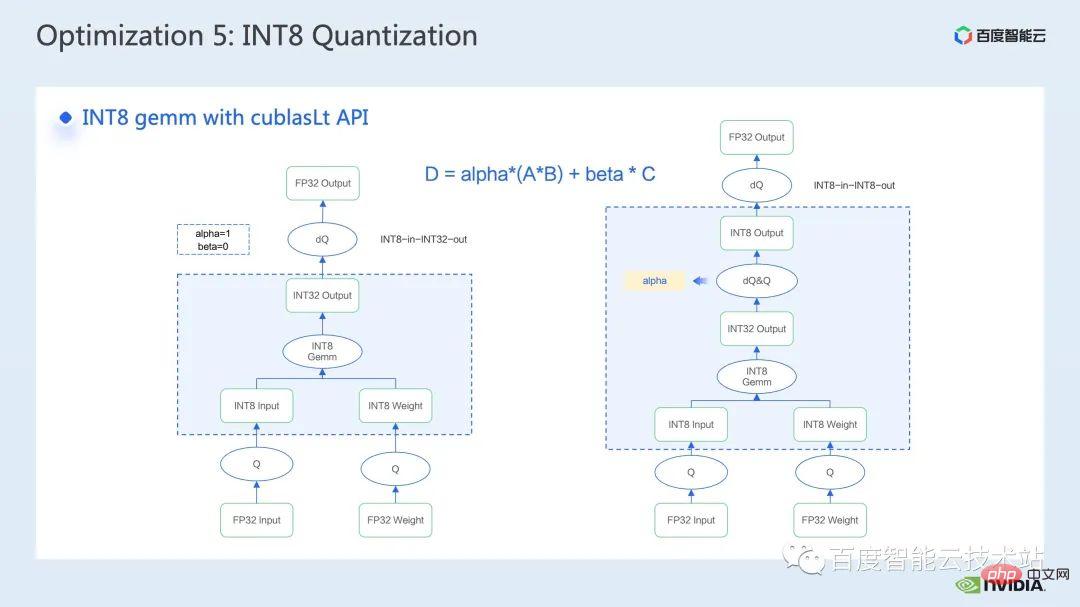
比較常見呼叫INT8 矩陣乘法的工具是cublasLt,為了可以取得更好的效能,我們有必要深入地了解一下cublasLt api 的一些特性。
cublasLt 對於int8 矩陣乘法,提供了兩種輸出類型,分別是下圖左側所示,以INT32 輸出,或是下圖右側所示,以INT8 輸出,圖中藍框所示的cublasLt 的計算操作。
可以看到相對於INT32 輸出而言, INT8 輸出會多了一對反量化和量化操作,這樣一來一般會帶來更多的精度損失,但是由於INT8 輸出,在寫出到global memory 時相對INT32 輸出少了3/4 的數據量,性能會更好,所以這裡面存在著精度和性能tradeoff。
那麼對於Swin Transformer 而言,我們發現配合QAT,以INT8 輸出會在取好的加速比的前提下,保證精度,因為我們採用了INT8 輸出的方案。
另外,關於cublasLt 中INT8 矩陣乘法,還需要考慮資料的佈局問題,cublasLt 支援兩種佈局,一種IMMA-specific 的佈局,其中涉及一些比較複雜的格式,而且在這種佈局只支援NT-gemm,另外一種是常規的列優先的佈局,在此佈局下支援TN-gemm 。
一般來說,採用列優先的佈局,會更有利於整個pipeline 程式碼的開發,因為如果我們用IMMA-specific 佈局的話,我們為了相容於這種佈局可能需要很多額外的操作,以及上下游kernel 也需要為這種特殊佈局做相容。但在一些尺寸的矩陣乘法上,IMMA-specific 佈局可能會有更好的性能,所以如果我們要嘗試建立int8 推理的話,建議咱們可以先做一些benchmark,以便更好地從性能和開發難易程度做取捨。
在 FasterTransformer 中我們採用了 IMMA-specific 佈局。所以接下來,我們以 IMMA-specific 佈局為例,簡單介紹了一下 cublasLt int8 矩陣乘法的基本搭建流程,以及一些開發技巧。

cublasLt int8 矩陣乘法的基本搭建流程,總共可以分成5 步驟:
#- 首先我們需要建立句柄和乘法描述子;
- #接下來我們為每個矩陣建立一個矩陣描述符;
- 因為一般我們的輸入都是常規layout 的,所以我們需要對常規佈局的矩陣進行佈局轉換,使其變為IMMA- specific 的佈局;
- 然後再進行int8 矩陣乘法,得到結果之後,我們可以考慮繼續用這個結果進行下游的乘法計算,這樣可以避免轉變會常規佈局的開銷;
- 只有最後一個矩陣乘法的結果,我們需要轉換常規佈局以便輸出。
上述介紹了 IMMA-specific 版面下的建置流程,可以看到裡面會有不少限制。為了避免這些限制對效能的影響,我們在Faster Transformer 中採用了以下技巧:
- #首先IMMA-specific 佈局對矩陣是有特定的尺寸要求,為了避免推理過程中需要額外分配空間的操作,我們會提前分配好符合IMMA-specific 佈局尺寸的buffer;
- 然後,由於weight 可以一次處理重複使用,所以我們會事先對weight(相當於乘法中的B 矩陣)進行佈局變換,避免在推理過程中反覆變換weight;
- 第三個技巧是,對於必須進行特殊佈局變換的A 和C,我們會把變換和上游或下游op 進行算子融合,以便隱藏這部分的開銷;
- 最後一點,是與佈局無關,而是int8 矩陣乘法必有的量化和反量化的操作,我們同樣會採用算子融合的方式,把它的latency 隱藏起來。

以下是我們在Faster Transformer 中所採用的的INT8 流程的示意圖,可以看到,所有矩陣乘都變為了int8 資料類型,每個int8 矩陣乘法前後都會插入對應的量化和反量化節點,然後對於加bias,加上殘差或layernorm 等操作,我們還是保留原始的FP32 或FP16 資料類型,當然它的I/O 可能是int8 的,因此會比FP16 或FP32 I/O 效能更好。
這裡展示的是Swin Transformer int8 量化的精確度情況,透過QAT 我們可以確保精確度損失在千分之5 以內。
而在PTQ 那一列,我們可以看到Swin-Large 的掉點比較嚴重,一般對應掉點嚴重的問題,我們都可以考慮採用減少一些量化節點的方式來提升量化精度,當然這可能會帶來加速效果的減弱。
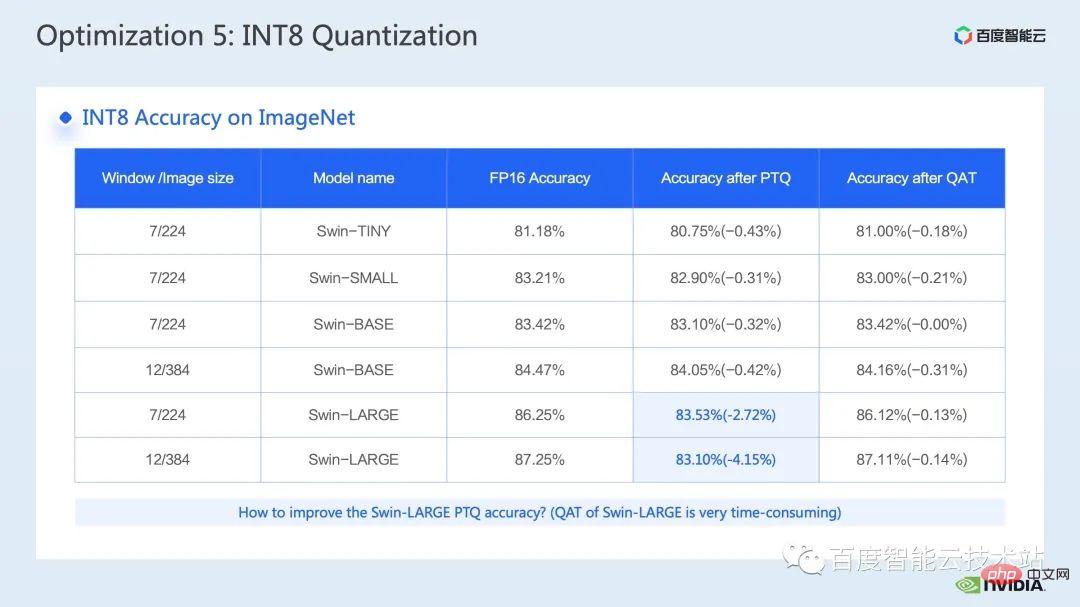
在FT 中,我們可以透過停用FC2 和PatchMerge 中int 8 矩陣乘法的int8 輸出前的反量化和量化結點(即採用int32 輸出),來進一步提升量化精度,可以看到在此優化操作下,swin-large 的PTQ 精度也明顯提升了。

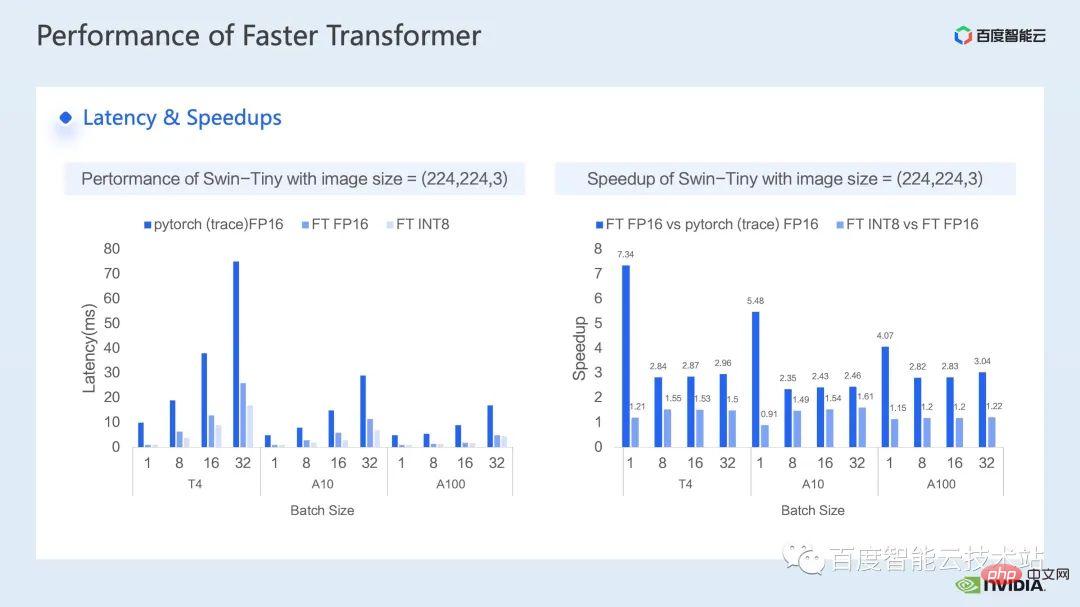
接下來是我們推理側所取得的加速效果,我們分別在不同型號的GPU T4、A10、A100上進行了跟pytorch FP16 實現的性能比較。
#其中下圖左側是優化後跟 pytorch 的 latency 對比,右圖為優化後 FP16 下跟 pytorch 以及 INT8 優化跟 FP16 優化的加速比。可以看到,透過最佳化,在 FP16 精度上,我們可以取得,相對於 pytorch 2.82x ~ 7.34x 的加速,結合 INT8 量化,我們可以在此基礎上進一步取得 1.2x ~ 1.5x 的加速。
4. Swin Transformer 最佳化總結
##最後,我們總結一下,本次分享中我們介紹瞭如何透過nsight system 效能分析工具發現效能瓶頸,然後針對效能瓶頸,介紹了一系列訓練推理加速技巧,其中包括 1. 混合精度訓練/ 低精度推理,2. 算子融合,3. cuda kernel 優化技巧:如矩陣補零,向量化讀寫,巧用寄存器數組等,4. 推理優化上採用一些預處理,來完善我們的計算流程;我們也介紹了multi-stream,cuda graph 的一些應用。
結合上述優化,我們在訓練上,以Swin-Large 模型為例取得了單卡 2.85x 的加速比,8 卡2.32x 的加速比;在推理上,以Swin-tiny 模型為例,在FP16 精度下取得了2.82x ~ 7.34x 的加速比,結合INT8 量化,進一步取得1.2x ~ 1.5x 的加速比。

上述視覺大模型訓練與推理的加速方法都已經在百度百舸AI 異構運算平台的AIAK加速功能中實現,歡迎大家使用。

以上是如何運用視覺大模型加速訓練和推理?的詳細內容。更多資訊請關注PHP中文網其他相關文章!