



短影片推薦系統的核心目標是透過提升用戶留存,牽引 DAU 成長。因此留存是各APP的核心業務優化指標之一。然而留存是使用者和系統多次互動後的長期回饋,很難分解到單一 item 或單一 list,因此傳統的 point-wise 和 list-wise 模型難以直接優化留存。
強化學習(RL)方法透過和環境互動的方式優化長期獎勵,適合直接優化使用者留存。此工作將留存優化問題建模成一個無窮視野請求粒度的馬爾科夫決策過程(MDP),使用者每次請求推薦系統決策一個動作(action),用於聚合多個不同的短期回饋預估(觀看時長、按讚、追蹤、留言、轉發等)的排序模型評分。此工作目標是學習策略(policy),最小化使用者多個會話的累積時間間隔,提升 App 開啟頻次進而提升使用者留存。
然而由於留存訊號的特性,現有RL 演算法直接應用存在以下挑戰:1)不確定性:留存訊號不僅由推薦演算法決定,還受到許多外部因素幹擾; 2)偏差:留存訊號在不同時間段、不同活躍度用戶群存在偏差;3)不穩定性:與遊戲環境立即返回獎勵不同,留存訊號通常在數小時至幾天返回,這會導致RL 演算法在線訓練的不穩定問題。
該工作提出 Reinforcement Learning for User Retention algorithm(RLUR)演算法解決以上挑戰並直接優化留存。透過離線和線上驗證,RLUR 演算法相比 State of Art 基準能夠顯著地提升次留指標。 RLUR 演算法已經在快手 App 全量,並且能夠持續地拿到顯著的次留和 DAU 收益,是業界首次透過 RL 技術在真實生產環境提升用戶留存。該工作已被 WWW 2023 Industry Track 接收。

#作者:蔡慶芃,劉殊暢,王學良,左天佑,謝文濤,楊斌,鄭東,江鵬
論文網址:https://arxiv.org/pdf/2302.01724.pdf
問題建模






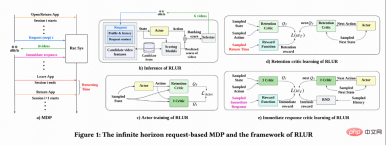
RLUR 演算法
該工作首先討論怎麼預估累計回訪時間,然後提出方法解決留存訊號的幾個關鍵挑戰。這些方法彙整成 Reinforcement Learning for User Retention algorithm,簡寫為 RLUR。
回訪時間預估
#如圖1(d)所示,由於動作是連續的,該工作採取DDPG 演算法的temporal difference(TD)學習方式預估回訪時間。

由於每個session 最後一次要求才有回訪時間reward,中間reward 為0,作者設定折扣因子 在每個session 最後一次請求取值為
在每個session 最後一次請求取值為 ,其他請求為1。這樣的設定能夠避免回訪時間指數衰減。並且從理論上可以證明當 loss(1)為 0 時,Q 實際上預估多個 session 的累計回訪時間,
,其他請求為1。這樣的設定能夠避免回訪時間指數衰減。並且從理論上可以證明當 loss(1)為 0 時,Q 實際上預估多個 session 的累計回訪時間, 。
。
解決延遲獎勵問題
#由於回訪時間只發生在每個session 結束,這會帶來學習效率低的問題。因而作者運用啟發式獎勵來增強策略學習。由於短期回饋和留存是正相關關係,因而作者把短期回饋當作第一種啟發式獎勵。而作者採用 Random Network Distillation(RND)網絡來計算每個樣本的內在獎勵作為第二種啟發式獎勵。具體而言 RND 網絡採用 2 個相同的網絡結構,一個網絡隨機初始化 fixed,另一個網絡擬合這個固定網絡,擬合 loss 作為內在獎勵。如圖 1(e)所示,為了減少啟發式獎勵對留存獎勵的干擾,該工作學習一個單獨的 Critic 網絡,用來估計短期回饋和內在獎勵總和。即  。
。
解決不確定性問題
#由於回訪時間受到許多推薦之外的因素影響,不確定度高,會影響學習效果。此工作提出一個正規化方法來減少變異數:首先預估一個分類模型 來預估回訪時間機率,即預估回訪時間是否短於
來預估回訪時間機率,即預估回訪時間是否短於 ;然後用馬可夫不等式得到回訪時間下界,
;然後用馬可夫不等式得到回訪時間下界, ; 最後用真實回訪時間/ 預估回訪時間下界作為正則化的回訪reward。
; 最後用真實回訪時間/ 預估回訪時間下界作為正則化的回訪reward。
解決偏差問題
#由於不同活躍群體的行為習慣差異大,高活用戶留存率高且訓練樣本數也顯著多於低活用戶,這會導致模型學習被高活用戶主導。為解決這個問題,該工作對高活和低活不同群體學習 2 個獨立策略,採用不同的資料流進行訓練,Actor 最小化回訪時間同時最大化輔助獎勵。如圖 1(c),以高活群體為例,Actor loss 為:

解決不穩定性問題
由於回訪時間訊號延遲,一般在幾個小時到數天內返回,這會導致RL 在線訓練不穩定。而直接使用現有的 behavior cloning 的方式要么極大限制學習速度要么不能保證穩定學習。因而該工作提出一個新的軟正則化方法,即在actor loss 乘上一個軟正則化係數:
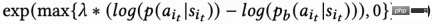
##這個正則化方法本質上是一種制動效應:如果當前學習策略和樣本策略偏差很大,這個loss 會變小,學習會趨於穩定;如果學習速度趨於穩定,這個loss 重新變大,學習速度加快。當 ,代表對學習過程不加任何限制。
,代表對學習過程不加任何限制。
該工作把RLUR 和State of the Art 的強化學習演算法TD3,以及黑盒子優化方法Cross Entropy Method (CEM) 在公開資料集KuaiRand 進行比較。這項工作首先基於 KuaiRand 資料集建立一個留存模擬器:包含使用者立即回饋,使用者離開 Session 以及使用者回訪 App 三個模組,然後在這個留存模擬器評測方法。

表 1 說明 RLUR 在回訪時間和次留指標顯著優於 CEM 和 TD3。研究進行消融實驗,比較 RLUR 和只保留留存學習部分 (RLUR (naive)),可以說明研究針對留存挑戰解決方法的有效性。並且透過 和
和 對比,說明最小化多個 session 的回訪時間的演算法效果優於只最小化單一 session 的回訪時間。
對比,說明最小化多個 session 的回訪時間的演算法效果優於只最小化單一 session 的回訪時間。
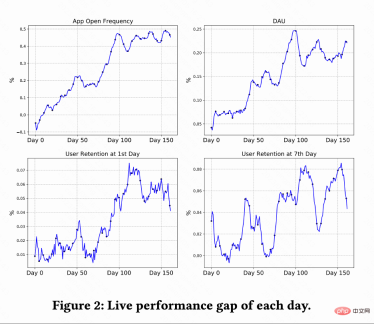
#該工作在快手短影片推薦系統進行A/B 測試對比RLUR 和CEM 方法。圖 2 分別顯示 RLUR 比較 CEM 的 App 開啟頻次、DAU、次留、7 留的提升百分比。可以發現 App 開啟頻次在 0-100 天逐漸提升甚至收斂。並且也拉動次留、7 留以及 DAU 指標的提升(0.1% 的 DAU 以及 0.01% 的次留提升視為統計顯著)。
總結與未來工作本文研究如何透過RL 技術提升推薦系統用戶留存,該工作將留存優化建模成一個無窮視野請求粒度的馬可夫決策過程,該工作提出RLUR 演算法直接優化留存並有效應對留存訊號的幾個關鍵挑戰。 RLUR 演算法已在快手 App 全量,能夠拿到顯著的次留和 DAU 收益。關於未來工作,如何採用離線強化學習、Decision Transformer 等方法更有效提升使用者留存是一個很有前景的方向。
以上是如何運用強化學習來提升快手用戶留存?的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 10個生成AI編碼擴展,在VS代碼中,您必須探索Apr 13, 2025 am 01:14 AM
10個生成AI編碼擴展,在VS代碼中,您必須探索Apr 13, 2025 am 01:14 AM嘿,編碼忍者!您當天計劃哪些與編碼有關的任務?在您進一步研究此博客之前,我希望您考慮所有與編碼相關的困境,這是將其列出的。 完畢? - 讓&#8217
 烹飪創新:人工智能如何改變食品服務Apr 12, 2025 pm 12:09 PM
烹飪創新:人工智能如何改變食品服務Apr 12, 2025 pm 12:09 PMAI增強食物準備 在新生的使用中,AI系統越來越多地用於食品製備中。 AI驅動的機器人在廚房中用於自動化食物準備任務,例如翻轉漢堡,製作披薩或組裝SA
 Python名稱空間和可變範圍的綜合指南Apr 12, 2025 pm 12:00 PM
Python名稱空間和可變範圍的綜合指南Apr 12, 2025 pm 12:00 PM介紹 了解Python函數中變量的名稱空間,範圍和行為對於有效編寫和避免運行時錯誤或異常至關重要。在本文中,我們將研究各種ASP
 視覺語言模型(VLMS)的綜合指南Apr 12, 2025 am 11:58 AM
視覺語言模型(VLMS)的綜合指南Apr 12, 2025 am 11:58 AM介紹 想像一下,穿過美術館,周圍是生動的繪畫和雕塑。現在,如果您可以向每一部分提出一個問題並獲得有意義的答案,該怎麼辦?您可能會問:“您在講什麼故事?
 聯發科技與kompanio Ultra和Dimenty 9400增強優質陣容Apr 12, 2025 am 11:52 AM
聯發科技與kompanio Ultra和Dimenty 9400增強優質陣容Apr 12, 2025 am 11:52 AM繼續使用產品節奏,本月,Mediatek發表了一系列公告,包括新的Kompanio Ultra和Dimenty 9400。這些產品填補了Mediatek業務中更傳統的部分,其中包括智能手機的芯片
 本週在AI:沃爾瑪在時尚趨勢之前設定了時尚趨勢Apr 12, 2025 am 11:51 AM
本週在AI:沃爾瑪在時尚趨勢之前設定了時尚趨勢Apr 12, 2025 am 11:51 AM#1 Google推出了Agent2Agent 故事:現在是星期一早上。作為AI驅動的招聘人員,您更聰明,而不是更努力。您在手機上登錄公司的儀表板。它告訴您三個關鍵角色已被採購,審查和計劃的FO
 生成的AI遇到心理摩托車Apr 12, 2025 am 11:50 AM
生成的AI遇到心理摩托車Apr 12, 2025 am 11:50 AM我猜你一定是。 我們似乎都知道,心理障礙由各種chat不休,這些chat不休,這些chat不休,混合了各種心理術語,並且常常是難以理解的或完全荒謬的。您需要做的一切才能噴出fo
 原型:科學家將紙變成塑料Apr 12, 2025 am 11:49 AM
原型:科學家將紙變成塑料Apr 12, 2025 am 11:49 AM根據本週發表的一項新研究,只有在2022年製造的塑料中,只有9.5%的塑料是由回收材料製成的。同時,塑料在垃圾填埋場和生態系統中繼續堆積。 但是有幫助。一支恩金團隊


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

MantisBT
Mantis是一個易於部署的基於Web的缺陷追蹤工具,用於幫助產品缺陷追蹤。它需要PHP、MySQL和一個Web伺服器。請查看我們的演示和託管服務。

記事本++7.3.1
好用且免費的程式碼編輯器

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

PhpStorm Mac 版本
最新(2018.2.1 )專業的PHP整合開發工具

SublimeText3漢化版
中文版,非常好用

