
解讀Toolformer

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-05-05 20:10:051679瀏覽
大語言模型(LLM)在利用有限的文字資料解決新任務方面表現出令人難以置信的優勢。然而,儘管如此,它們在其他方面也有局限性,例如:
- 無法訪問最新資訊
- #幻想事實的傾向
- 低資源語言的困難
- 缺乏精確計算的數學技能
- 對時間進程的不了解
如何使用大模型解決更多的問題呢?在《解讀TaskMatrix.AI》一文中,TaskMatrix.AI是 Toolformer 和 chatGPT 的結合,將基礎模型與數百萬個 API 連接起來以完成任務。那麼,什麼是 Toolformer 呢?
Toolformer 是 Meta 開源的新模型,能夠解決需要利用 API 的問題,例如計算器、維基百科搜尋、字典查找等。 Toolformer 能夠認識到它必須使用一個工具,能夠確定使用哪個工具,以及如何使用該工具。 Toolformers 的用例可能是無窮無盡的,從提供任何問題的即時搜尋結果,到情境信息,例如城裡最好的餐廳。
1. 什麼是Toolformer?
什麼是 Toolformer 呢?簡而言之,Toolformer 是一個可以自學使用工具的語言模型。
Toolformer 基於預先訓練的 GPT-J 模型,包含 67 億個參數,使用自監督學習方法進行訓練。這種方法包括採樣和過濾 API 呼叫,以增加現有的文字資料集。
Toolformer 希望透過以下兩個要求來完成LLM 自學如何使用工具的任務:
- 工具的使用應該透過自我監督的方式來學習,而不需要大量的人工註釋。
- LM 不應喪失其一般性,應該能夠自行決定何時以及如何使用哪種工具。
下圖顯示了Toolformer 的預測(例如,在資料樣本中嵌入的API 呼叫):

2. Toolformer 的架構和實作方法
ChatGPT 中的一個核心特性是基於上下文的學習(In-Context Learning),指的是一種機器學習方法,其中模型從特定上下文或環境中呈現的範例中學習。上下文學習的目標是提高模型理解和產生適合給定上下文或情況的語言的能力。在自然語言處理(NLP)任務中,可以訓練語言模型來產生對特定提示或問題的反應。那麼,Toolformer 要如何利用 In-Context Learning 呢?
Toolformer 是一個大型語言模型,它能夠透過 API 呼叫使用不同的工具。每個 API 呼叫的輸入和輸出需要格式化為文字/對話序列,以便在會話中自然流動。

從上面的圖片可以看到的,Toolformer 首先利用模型的上下文學習能力來對大量潛在的 API 呼叫進行取樣。
執行這些 API 呼叫,並檢查獲得的回應是否有助於將來預測 token,並被用作篩選條件。經過過濾之後,對不同工具的 API 呼叫被嵌入到原始資料樣本中,從而產生增強的資料集,而模型就是在這個資料集上進行微調的。
具體地,上圖顯示了使用問答工具完成此任務的模型:
- LM 資料集包含範例文字: 為「Pittsburgh is also known as」輸入提示「Pittsburgh is also known as The Steel City」。
- 為了找到正確的答案,模型需要進行一個 API 呼叫並正確地進行呼叫。
- 對一些 API 呼叫進行了抽樣,特別是「 What other name is Pittsburgh known by?」和「 Which country is Pittsburgh in?」。
- 對應的答案是「Steel City」和「United States」。因為第一個答案更好,所以它被包含到一個新的LM 資料集中,並帶有API 呼叫: “Pittsburgh is also known as [QA(”What other name is Pittsburgh known by?”) -> Steel City] the Steel City」。
- 這包含預期的 API 呼叫和應答。重複此步驟以使用各種工具(即 API 呼叫)產生新的 LM 資料集。
因此,LM 使用嵌入在文字中的 API 呼叫來註釋大量數據,然後使用這些 API 呼叫對 LM 進行微調,以進行有用的 API 呼叫。這就是自監督訓練的方式,這種方法的好處包括:
- 更少需要手動註解。
- 將 API 呼叫嵌入到文字中允許 LM 使用多個外部工具來新增更多內容。
Toolformer 接著學會預測每個任務會使用哪個工具。
2.1 API 呼叫的取樣
下圖顯示了給定使用者輸入的情況下,Toolformer使用和來表示API呼叫的開始和結束。為每個API編寫一個提示符,鼓勵Toolformer使用相關的API呼叫對範例進行註解。

Toolformer為每個token分配一個機率,作為給定序列的一個可能的延續。此方法透過計算ToolFormer分配給在序列中每個位置啟動API呼叫的機率,對API呼叫的最多k個候選位置進行採樣。保持機率大於給定閾值的位置,對於每個位置,透過使用以API呼叫為前綴、以序列結束標記為後綴的序列從Toolformer取樣,最多可獲得m個API呼叫。
2.2 API呼叫的執行
API呼叫的執行完全取決於正在執行呼叫的客戶端。客戶端可以是不同類型的應用程序,從另一個神經網路、Python腳本,到在大型語料庫中搜尋的檢索系統。需要注意的是,當客戶端發出呼叫時,API會傳回單一的文字序列回應。此回應包含有關呼叫的詳細信息,包括呼叫的成功或失敗狀態、執行時間等。
因此,為了獲得準確的結果,客戶端應該確保提供正確的輸入參數。如果輸入參數不正確,API可能會傳回錯誤的結果,這對使用者來說可能是不可接受的。另外,客戶端也應該確保與API的連線是穩定的,以避免在呼叫期間發生連線中斷或其他網路問題。
2.3 濾波API呼叫
在篩選過程中,Toolformer透過API呼叫後的token計算Toolformer的加權交叉熵損失。
然後,比較兩種不同的損失計算:
(i)一種是API調用,其結果作為輸入給Toolformer
(ii)一種是沒有API呼叫或API呼叫但沒有回傳結果。
如果為API呼叫提供輸入和輸出,使得Toolformer更容易預測未來的token,那麼API呼叫就被認為是有用的。應用過濾閾值僅保留兩個損失之間的差值大於或等於閾值的API呼叫。
2.4 模型微調
最後,Toolformer將剩餘的API呼叫與原始輸入合併,並建立一個新的API呼叫來增強的資料集。換句話說,增強的資料集包含與原始資料集相同的文本,只插入了API呼叫。
然後,使用新的資料集使用標準語言建模目標對ToolFormer進行微調。這樣可以確保在增強的資料集上微調模型會暴露給與在原始資料集上微調相同的內容。透過在準確的位置插入API調用,並使用幫助模型預測未來token的輸入,對增強資料的微調使語言模型能夠了解何時以及如何根據自己的回饋使用API調用。
2.5 推理
在推理過程中,當語言模型產生「→」token時,解碼過程被中斷,這表示 API 呼叫的下一個預期回應。然後,呼叫適當的 API 來取得回應,並在插入回應和token之後繼續解碼。
此時,我們需要確保所獲得的回應與上一個token所期望的回應相符。如果不匹配,我們需要調整 API 呼叫以獲得正確的回應。在繼續解碼之前,我們還需要執行一些資料處理來準備下一步的推理過程。這些資料處理包括對反應的分析、對上下文的理解以及對推理路徑的選擇。因此,在推理過程中,不僅需要呼叫 API 來獲取回應,還需要進行一系列的資料處理和分析,以確保推理過程的正確性和連貫性。
2.6 API工具
Toolformer 中每個可以使用的API工具都要滿足以下兩個條件:
- 輸入/輸出都需要表示為文字序列。
- 有可用的簡報表達如何使用這些工具。
Toolformer 的初始實作中支援了五個API工具:
- 問答回答:這是另一個LM,可以回答簡單的事實問題。
- 計算器:目前只支援4個基本的算術運算,並四捨五入到小數點後兩位。
- Wiki搜尋:傳回從維基百科剪下來的短文字的搜尋引擎。
- 機器翻譯系統:一個可以將任何語言的片語翻譯成英文的LM。
- 日曆:對日曆的API調用,該調用返回當前日期而不接受任何輸入。
下圖顯示了所有使用的API的輸入和輸出範例:

3. 應用範例
Toolformer在LAMA、數學資料集、問題解答和時間資料集等任務中的表現優於基準模型和GPT-3,但在多語言問答中表現不如其他模型。 Toolformer使用API呼叫來完成任務,例如LAMA API、Calculator API和Wikipedia搜尋工具API。
3.1 LAMA
任務是完成一個缺少事實的陳述語句。 Toolformer 的表現優於基準模型,甚至更大的模型,如 GPT-3。下表展示了透過LAMA API 呼叫獲得的結果:
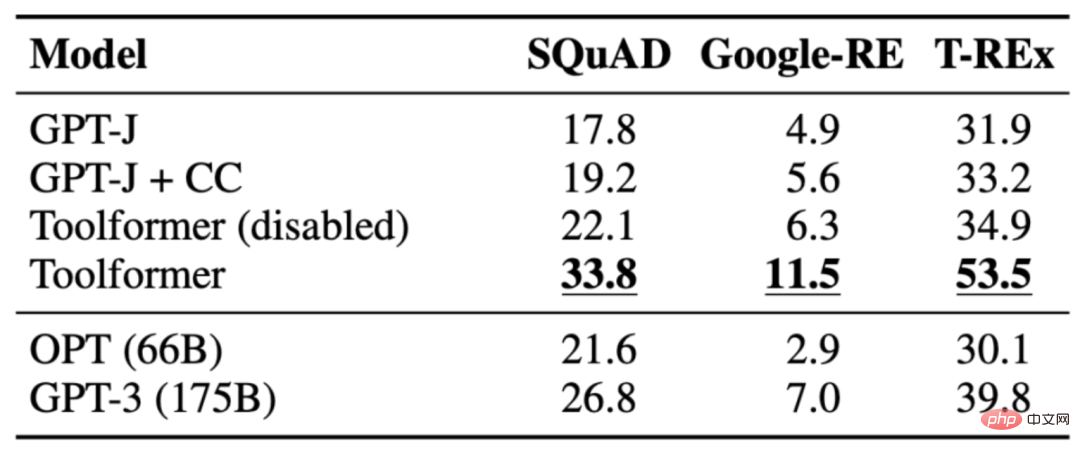
3.2 數學資料集
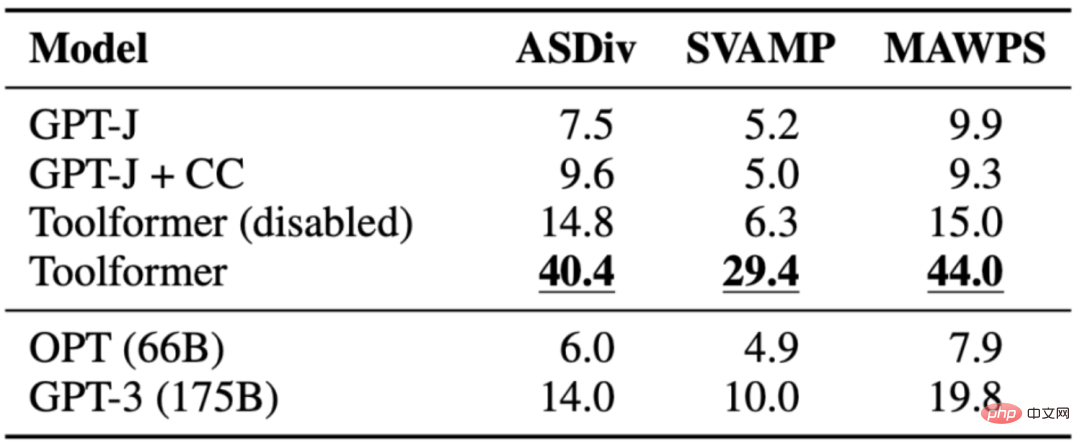
任務是評估Toolformer 的數學推理能力來比較各種基線模型。 Toolformer 的效能優於其他模型,可能是因為它對 API 呼叫範例進行了微調。允許模型進行 API 呼叫可以顯著提高所有任務的效能,並優於 OPT 和 GPT-3等更大的模型。在幾乎所有情況下,模型都決定向計算器工具尋求協助。
下表展示了透過Calculator API 呼叫獲得的結果:
#3.3 問題解答
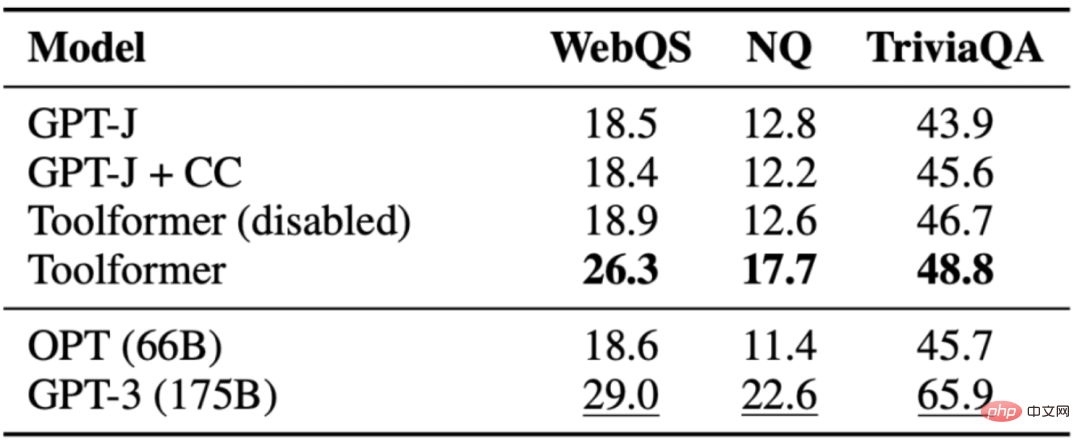
任務是回答問題,Toolformer 的表現優於同樣大小的基準模型,但是優於GPT-3(175B)。 Toolformer 利用 Wikipedia 的搜尋工具來完成這項任務中的大多數範例。下表展示了透過Wikipedia 搜尋工具API 呼叫獲得的結果:
#3.4 多語言問答
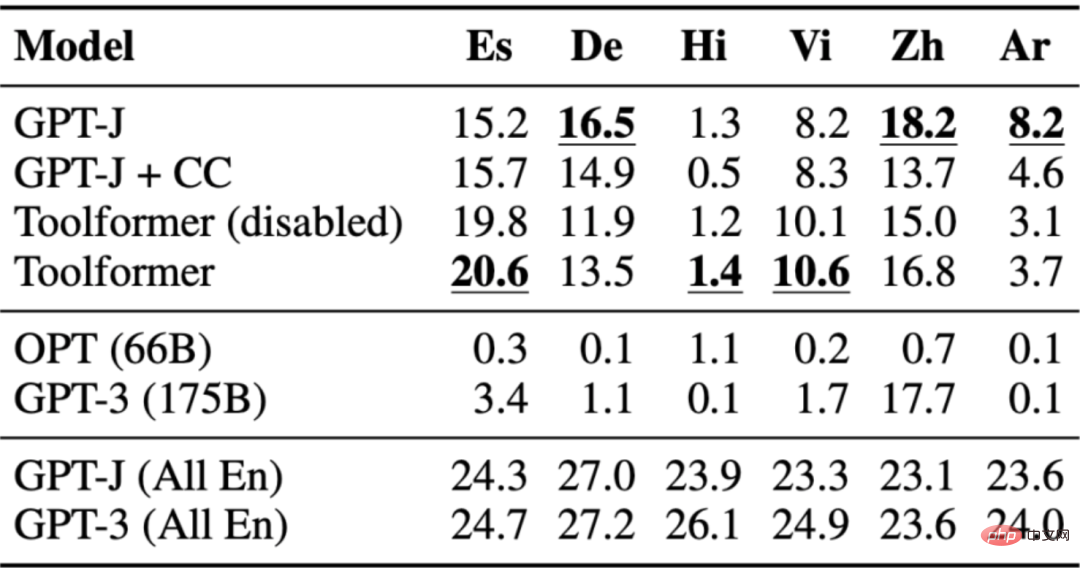
問答資料集被用於多語言問答基準測試MLQA,其中包含英語上下文段落和阿拉伯語、德語、西班牙語、印地語、越南語或簡體中文的問題。 Toolformer 在這裡並不是最強大的表現者,這可能是由於 CCNet 在所有語言上都缺乏調優。
下表展示了透過Wikipedia 搜尋工具API 呼叫所獲得的結果:
3.5 時間資料集
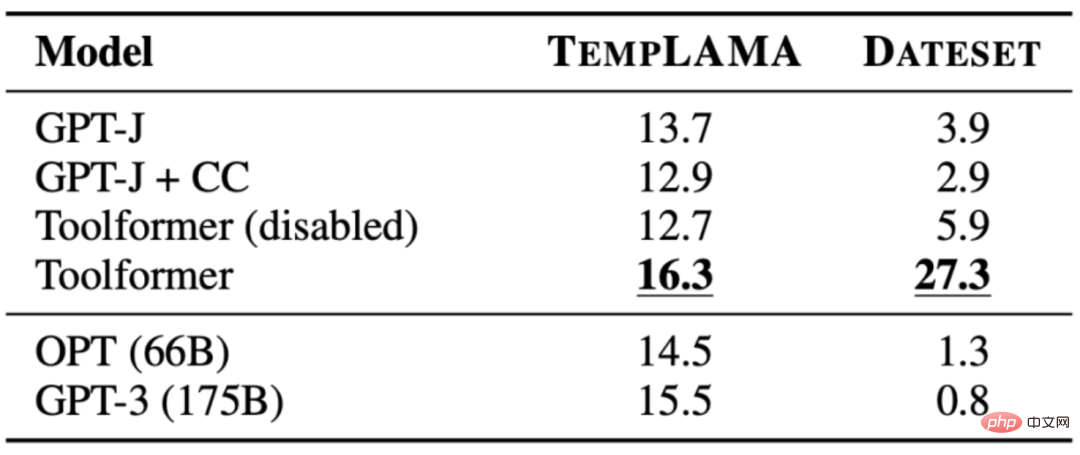
- 由於每個工具的 API 呼叫都是獨立產生的,因此 Toolformer 無法在一個流程中使用多個工具。
- 特別是對於可能傳回數百個不同結果的工具(如搜尋引擎),Toolformer 不能以互動方式使用。
- 使用 Toolformer 進行訓練的模型對輸入的確切措辭非常敏感,這種方法對於某些工具來說效率很低,需要大量的文件以產生少量有用的 API 呼叫。
- 在決定使用每個工具時,沒有考慮使用它的成本,這可能會導致較高的計算成本。
5. 小結
Toolformer 是一個大型語言模型,透過使用 In-Context Learning 來提高模型理解和產生適合給定上下文或情況的語言能力。它使用 API 呼叫來註釋大量數據,然後使用這些 API 呼叫對模型進行微調,以進行有用的 API 呼叫。 Toolformer 學會預測每個任務會使用哪個工具。然而,Toolformer 仍然存在一些局限性,例如無法在一個流程中使用多個工具,對於可能返回數百個不同結果的工具不能以互動方式使用等。
【參考資料與關聯閱讀】
- Toolformer: Language Models Can Teach Themselves to Use Tools,https://arxiv.org/pdf/2302.04761.pdf
- Meta's Toolformer Uses APIs to Outperform GPT-3 on Zero-Shot NLP Tasks,https://www.infoq.com/news/2023/04/meta-toolformer/
- #Toolformer: Language Models Can Teach Themselves to Use Tools (2023),https://kikaben.com/toolformer-2023/
- Breaking Down Toolformer,https://www.shaped.ai/blog/breaking-down-toolformer
- Toolformer: Meta Re-enters the ChatGPT Race With a New Model Using Wikipedia,https://thechainsaw.com/business/meta-toolformer-ai/
- #Toolformer language model uses external tools on its own ,https://the-decoder.com/toolformer-language-model-uses-external-tools-on-its-own/
以上是解讀Toolformer的詳細內容。更多資訊請關注PHP中文網其他相關文章!