
哈工大南洋理工提出全球首個「多模態DeepFake偵測定位」模式:讓AIGC偽造無處可藏

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-04-25 10:19:061680瀏覽
由於如Stable Diffusion等視覺生成模型的快速發展,高保真度的人臉圖片可以自動化地偽造,製造越來越嚴重的DeepFake問題。
隨著如ChatGPT等大型語言模型的出現,大量假本文也可以輕易地產生並惡意地傳播假訊息。
為此,一系列單模態偵測模型被設計出來,去應對以上AIGC技術在圖片和文字模態的偽造。但是這些方法無法較好應對新型偽造場景下的多模態假新聞竄改。
具體而言,在多模態媒體篡改中,各類新聞報導的圖片中重要人物的人臉(如圖1 中法國總統人臉)被替換,文字中關鍵短語或單字被竄改(如圖1 中正面短語「is welcome to」被竄改為負面片語「is forced to resign」)。
這將改變或掩蓋新聞關鍵人物的身份,以及修改或誤導新聞文字的含義,製造出網路上大規模傳播的多模態假新聞。
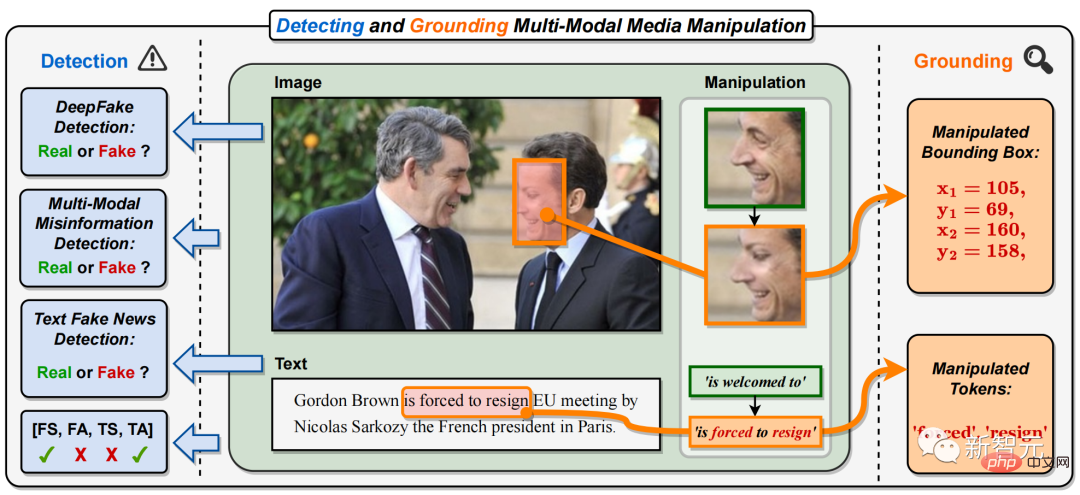
圖1. 本文提出偵測並定位多模態媒體竄改任務(DGM4)。與現有的單模態DeepFake偵測任務不同,DGM4不僅對輸入影像-文字對預測真假二分類,也試圖偵測更細粒度的竄改類型和定位影像竄改區域和文字竄改單字。除了真假二分類之外,此任務對篡改偵測提供了更全面的解釋和更深入的理解。

表1: 所提出的DGM4與現有的圖像和文字偽造檢測相關任務的比較
偵測並定位多模態媒體竄改任務
為了解此新挑戰,來自哈工大(深圳)和南洋理工的研究人員提出了偵測並定位多模態媒體篡改任務(DGM4)、建構並開源了DGM4資料集,同時提出了多模態層次化篡改推理模型。目前,該工作已被CVPR 2023收錄。

理論#文字位址:https://arxiv.org/abs /2304.02556
GitHub:https://github.com/rshaojimmy/MultiModal-DeepFake
##專案首頁:https://rshaojimmy.github.io/Projects/MultiModal-DeepFake
如圖1和表1所示,偵測並定位多模態媒體篡改任務(Detecting and Grounding Multi-Modal Media Manipulation (DGM
4))和現有的單模態篡改偵測的差異在於:
1)不同於現有的DeepFake影像偵測與偽造文字偵測方法只能偵測單模態偽造訊息,DGM4
要求同時偵測在影像-文字對中的多模態篡改;2)不同於現有DeepFake檢測專注於二分類,DGM4進一步考慮了定位圖像篡改區域和文字篡改單字。這要求檢測模型對於圖像-文字模態間的篡改進行更全面和深入的推理。 檢測並定位多模態媒體篡改資料集
######為了支援對DGM###4###研究,如圖2所示,本工作貢獻了全球首個###偵測並定位多模態媒體篡改(DGM###4###)資料集###。 ######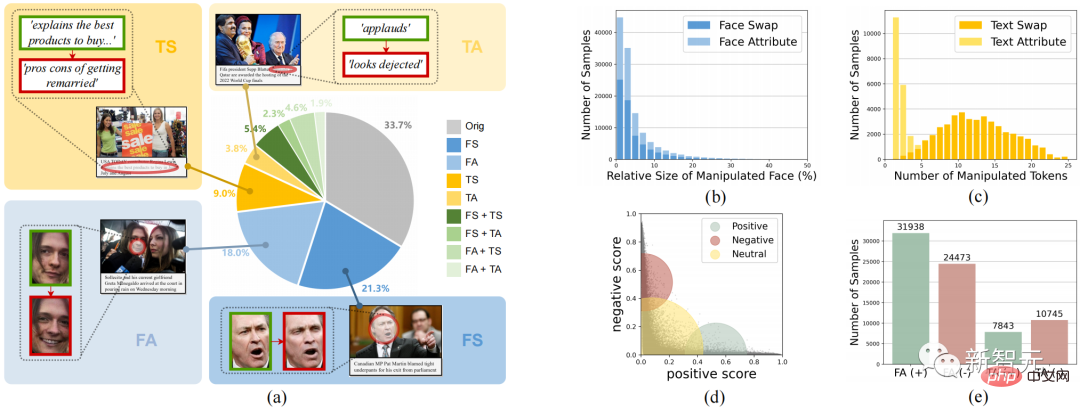
圖2. DGM4資料集
DGM 4資料集調查了4種篡改類型,人臉替換篡改(FS)、人臉屬性篡改(FA)、文字替換篡改(TS)、文字屬性篡改(TA)。
圖2展示了DGM4 整體統計信息,包括(a) 篡改類型的數量分佈;(b) 大多數圖像的篡改區域是小尺寸的,特別是對於人臉屬性篡改;(c) 文本屬性篡改的篡改單字少於文本替換篡改;(d)文本情感分數的分佈;(e)每種篡改類型的樣本數。
此資料共產生23萬張圖像-文字對樣本,包含了包含77426個原始圖像-文字對和152574個篡改樣本對。篡改樣本對包含66722個人臉替換篡改,56411個人臉屬性篡改,43546個文本替換篡改和18588個文本屬性篡改。
多模態層次化篡改推理模型
本文認為多模態的竄改會造成模態間細微的語意不一致性。因此透過融合與推理模態間的語意特徵,偵測到篡改樣本的跨模態語意不一致性,是本文應對DGM4的主要想法。
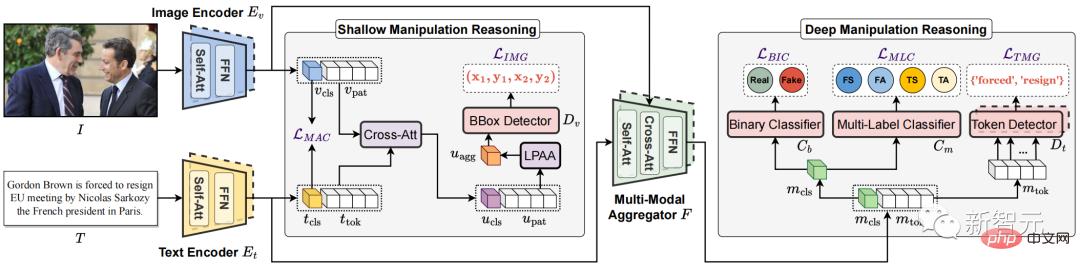
圖3. 提出的多模態層次化篡改推理模型HierArchical Multi-modal Manipulation rEasoning tRansformer (HAMMER)
基於此想法,如圖3所示,本文提出了多模態層次化篡改推理模型HierArchical Multi-modal Manipulation rEasoning tRansformer (HAMMER)。
此模型建立在基於雙塔結構的多模態語義融合與推理的模型架構上,並將多模態篡改的檢測與定位細粒度層次化地通過淺層與深層篡改推理來實現。
具體而言,如圖3所示,HAMMER模型具有以下兩個特點:
1)在淺層篡改推理中,透過篡改感知的對比學習(Manipulation-Aware Contrastive Learning)來對齊圖像編碼器和文字編碼器提取出的圖像和文字單模態的語義特徵。同時將單模態嵌入特徵利用交叉注意力機制進行資訊交互,並設計局部區塊注意力聚合機制(Local Patch Attentional Aggregation)來定位影像篡改區域;
2)在深層篡改推理中,利用多模態聚合器中的模態感知交叉注意力機制進一步融合多模態語意特徵。在此基礎上,進行特殊的多模態序列標記(multi-modal sequence tagging)和多模態多標籤分類(multi-modal multi-label classification)來定位文字篡改單字並檢測更細粒度的篡改類型。
實驗結果
如下圖,實驗結果顯示研究團隊提出的HAMMER與多模態和單模態偵測方法相比,都能更精確地偵測並定位多模態媒體竄改。

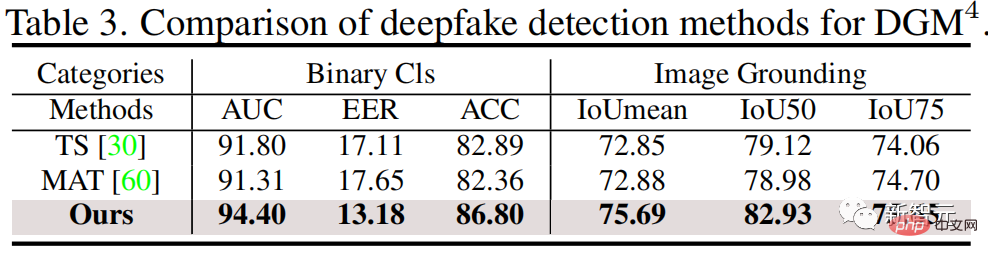
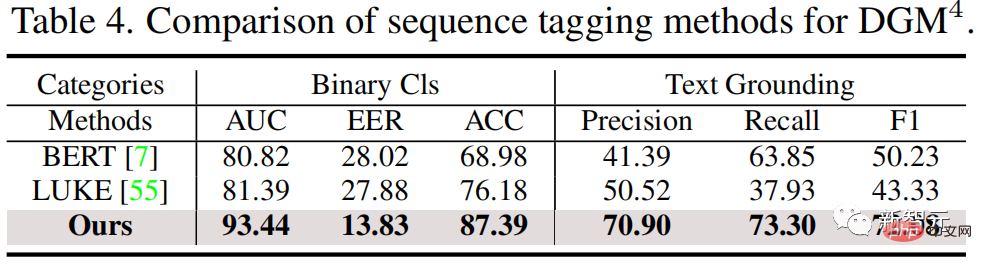
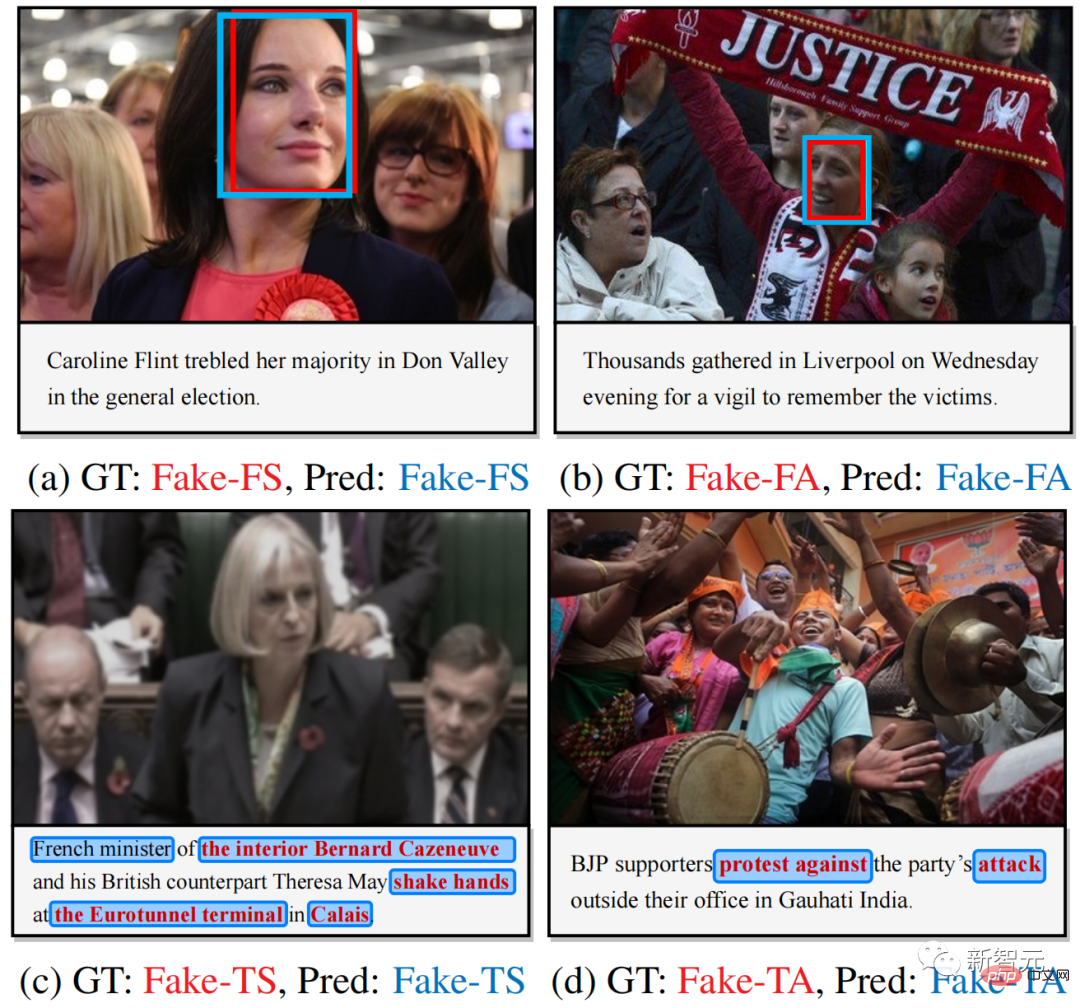
圖4. 多模態篡改偵測與定位結果視覺化

圖5 . 關於篡改文本的模型篡改檢測注意力可視化
圖4提供了一些多模態篡改檢測和定位的可視化結果,說明了HAMMER可以準確地同時進行篡改檢測與定位任務。圖5提供了關於篡改單字的模型注意力視覺化結果,進一步展示了HAMMER是透過專注於與篡改文字語義不一致性的圖像區域來進行多模態篡改檢測和定位。
總結
- 本工作提出了一個新的研究主題:偵測並定位多模態媒體竄改任務,來處理多模態假新聞。
- 本工作貢獻了首個大規模的偵測並定位多模態媒體篡改資料集,並提供了詳細豐富的篡改偵測與定位的標註。團隊相信它可以很好地幫助未來多模態假新聞檢測的研究。
- 本工作提出了一個強大的多模態層次化篡改推理模型作為此新課題很好的起始方案。
本工作的程式碼和資料集連結都已分享在本專案的GitHub上,歡迎大家Star這個GitHub Repo, 使用DGM4資料集和HAMMER來研究DGM4問題。 DeepFake領域不只有影像單模態偵測,還有更廣大的多模態竄改偵測問題亟待大家解決!
以上是哈工大南洋理工提出全球首個「多模態DeepFake偵測定位」模式:讓AIGC偽造無處可藏的詳細內容。更多資訊請關注PHP中文網其他相關文章!