
平行計算的量化模型及其在深度學習引擎的應用

- 王林轉載
- 2023-04-18 13:37:031772瀏覽
天下武功,唯快不破。怎麼更快訓練深度學習模型是業界一直關注的焦點,業界玩家或開發專用硬件,或開發軟體框架,各顯神通。
當然,這些定律在電腦體系結構的教材和文獻中都可看到,譬如這本《電腦體系結構:量化研究方法 ( Computer Architecture: a Quantative Approach )》,但本文的價值在於有針對性地挑選最根本的幾條定律,並結合深度學習引擎來理解。
1 關於計算量的假定
在研究平行計算的量化模型之前,我們先做一些設定。對於一個特定的深度學習模型訓練任務,假設總的計算量V固定不變,那可以粗略認為只要完成V這個量級的計算,深度學習模型就完成訓練。
GitHub這個頁面( https://github.com/albanie/convnet-burden )羅列了常見CNN模型處理一張圖片所需的計算量,需要注意的是,本頁列出的是前向階段的計算量,在訓練階段還需要後向階段的計算,通常後向階段的計算量是大於前向計算量的。這篇論文( https://openreview.net/pdf?id=Bygq-H9eg )對訓練階段處理一張圖片的計算量給出了一個直覺的視覺化結果:
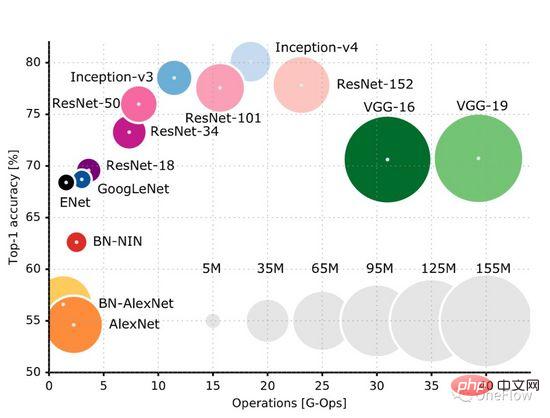
#以ResNet-50為例,訓練階段處理一張224X224x3的圖片需要8G-Ops (約80億次計算),整個ImageNet資料集約有120萬張圖片,訓練過程需要對整個資料集合處理90遍(Epochs),粗略估計,訓練過程共需要(8*10^9) *(1.2*10^6)* 90 = 0.864*10^18次運算,那麼ResNet-50訓練過程的總計算量大約是10億乘以10億次運算,我們可以簡單地認為,只要完成這些計算量就完成了模型運算。 深度學習計算引擎的目標是以最短的時間完成這個給定的計算量。
2 關於計算裝置的假定
本文僅限於下圖所示的以處理器為中心的計算裝置(Processor-centric computing),以記憶體為中心的計算(Processing in memory)裝置在業界有探索,但還不是主流。
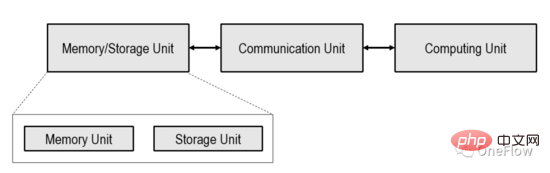
上圖所示的運算裝置中Computing Unit可以是通用處理器如CPU, GPGPU, 也可以是專用晶片如TPU等。如果Computing Unit是通用晶片,通常程式和資料都儲存在Memory Unit,這也是現在最受歡迎的馮諾依曼結構電腦。
如果Computing Unit是專用晶片,通常只有資料儲存在Memory Unit。 Communication Unit負責把資料從Memory Unit搬運到Computing Unit,完成資料載入(load),Computing Unit拿到資料後負責完成計算(資料的形式轉換),再由Communication Unit把計算結果搬運到Memory Unit完成資料儲存(Store)。
Communication Unit的傳輸能力通常以存取(Memory access)頻寬beta表示,即每秒鐘可以搬運的位元組數,這通常和線纜數和訊號的頻率相關。 Computing Unit的運算能力通常以吞吐率pi表示,即每秒鐘可以完成的浮點計算次數(flops),這通常和計算單元上整合的邏輯運算元件個數及時脈頻率有關。
深度學習引擎的目標是透過軟硬體協同設計使得該計算裝置處理資料的能力最強,即用最短的時間完成給定的計算量。
3 Roofline Model: 刻畫實際計算效能的數學模型
一個計算裝置執行一個任務時能達到的實際計算效能(每秒鐘完成的操作次數)不僅與訪存頻寬beta以及計算單元的理論峰值pi有關,也和目前任務本身的 運算強度 (Arithemetic intensity,或Operational intensity)。
任務的運算強度定義為每位元組資料所需的浮點計算次數,即Flops per byte。通俗地理解,一個任務運算強度小,表示Computing Unit在Communication Unit搬運的一個位元組上需要執行的運算次數少,為了讓Computing Unit在這種情況下處於忙碌狀態,Communication Unit就要頻繁搬運資料;
一個任務運算強度大,表示Computing Unit在Communication Unit搬運的一個位元組上需要執行的運算次數多,Communication Unit不需要那麼頻繁地搬運資料就能使Computing Unit處於忙碌狀態。
首先,實際計算性能不會超越計算單元的理論峰值pi。其次,假如訪存頻寬beta特別小,1秒鐘只能把beta個位元組從記憶體搬運到Computing Unit,令I表示目前計算任務中每個位元組所需的操作次數,那麼beta * I 表示1秒鐘內搬運過來的資料實際需要的操作次數,如果beta * I
Roofline model 就是一種根據訪存頻寬,計算單元峰值吞吐率,任務的運算強度三者關係來推斷實際計算性能的數學模型。由David Patterson團隊在2008年發表在Communications of ACM上( https://en.wikipedia.org/wiki/Roofline_model ),是一種簡潔優雅的可視化模式:
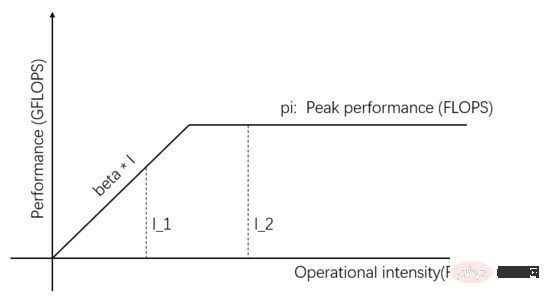
圖1:Roofline Model
圖1橫軸的自變數表示不同任務的運算強度,也就是每個位元組所需的浮點運算次數。縱軸的因變數表示實際可達的計算效能,即每秒鐘執行的浮點運算次數。上圖展示了兩個運算強度分別為I_1和I_2的任務能實際達到的計算性能,I_1的運算強度小於pi/beta,稱為訪存受限任務,實際計算性能beta * I_1低於理論峰值pi 。
I_2的運算強度高於pi/beta,稱為計算受限型任務,實際計算表現達到理論峰值pi,訪存頻寬僅利用了pi/(I_2*beta)。圖中斜線的斜率為beta,斜線和理論峰值pi 水平線的交點稱為脊點(Ridge point),脊點的橫座標是pi/beta,當任務的運算強度等於pi/beta時,Communication Unit和Computing Unit處於平衡狀態,哪一個都不會浪費。
回顧深度學習引擎的目標“ 以最短的時間完成給定的計算量 ”,就要最大化系統的實際可達的計算性能。為了實現這個目標,有幾種策略可用。
圖1中的I_2是計算受限型任務,可以透過 增加Computing Unit的平行度 並進而提高理論峰值來提高實際運算效能,譬如在Computing Unit上整合更多的運算邏輯單元( ALU)。具體到深度學習場景,就是增加GPU,從一個GPU增加到幾個GPU同時運算。
如圖2所示,當在Computing Unit內增加更多的並行度後,理論峰值高於beta * I_2,那麼I_2的實際計算性能就更高,只需要更短的時間就可以。
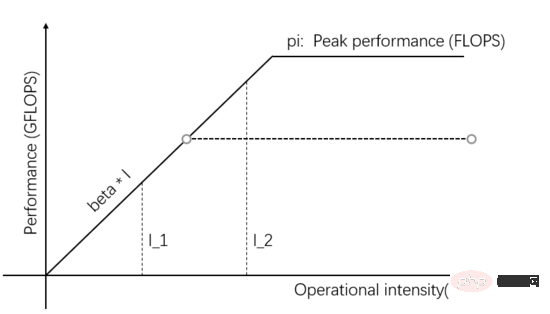
圖2:提高Computing Unit的理論峰值來提高實際計算性能
圖1中的I_1是訪存受限型的任務,則可透過 改善Communication Unit的傳輸頻寬 來提升實際運算效能,提升資料供應能力。如圖3所示,斜線的斜率表示Communication Unit的傳輸頻寬,當斜線的斜率增加時,I_1由訪問受限型任務變成計算受限型任務,實際運算效能提升。
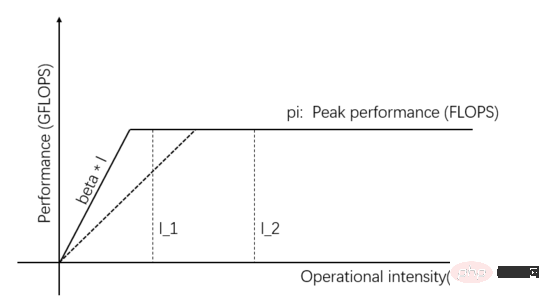
圖3:提高Communication Unit的數據供應能力來提高實際計算性能
除了透過改善硬體的傳輸頻寬或理論峰值來提高實際計算性能外,還可以透過 改善任務本身的運算強度 來提高實際計算性能。同樣的任務可以有多種不同的實現方式,不同實現方式的運算強度也存在差異。運算強度由I_1改造成超過pi/beta後,就變成計算受限型任務,實際運算效能達到pi,超過原來的beta*I_1。
在實際的深度學習引擎裡,以上三種手段(提高並行度,改善傳輸頻寬,使用運算強度更好的演算法實現)都會用到。
4 Amdahl's Law: 如何計算加速比?
圖2 的範例透過增加Computing Unit的平行度來提升實際運算效能,到底能把任務的執行時間縮短多少呢?這就是加速比問題,也就是效率提高了幾倍。
為了討論方便,(1)我們假設目前的任務是計算受限型,令I表示運算強度,即I*beta>pi。在將Computing Unit的運算單元增加s倍後,理論計算峰值是s * pi,假設該任務的運算強度I足夠高,使得在理論峰值提高s倍之後仍是計算受限型,即I*beta > s*pi;(2)假設沒有使用管線,Communication Unit和Computing Unit總是依序執行(後文我們將專門討論管線的影響)。讓我們來計算一下任務執行效率提高了幾倍。
在理論峰值是pi的初始情況下,1秒鐘Communication Unit搬運了beta位元組的數據,Computing Unit需要(I*beta)/pi 秒來完成計算。即在1 (I*beta)/pi 秒時間內完成了I*beta的計算,那麼單位時間內可以完成(I*beta) / (1 (I*beta)/pi) 的計算,假設總計算量是V,則總共需要t1=V*(1 (I*beta)/pi)/(I*beta) 秒。
透過增加並行度把理論計算峰值提高s倍之後,Communication Unit搬運beta位元組的資料仍需要1秒鐘,Computing Unit需要(I*beta)/(s*pi)秒來完成計算。假設總計算量是V,則共需t2=V*(1 (I*beta)/(s*pi))/(I*beta)秒完成任務。
計算t1/t2即獲得加速比:1/(pi/(pi I*beta) (I*beta)/(s*(pi I*beta))),很抱歉這個公式比較難看,讀者可以自己推導一下,比較簡單。
在理論高峰是pi時,搬運資料花了1秒,計算花了(I*beta)/pi 秒,那麼計算時間佔的比例是(I*beta)/(pi I*beta ),我們令p表示這個比例,等於(I*beta)/(pi I*beta)。
把p代入t1/t2的加速比,可以得到加速比為1/(1-p p/s),這就是大名鼎鼎的Amdahl's law( https://en.wikipedia.org/wiki/ Amdahl's_law )。其中p表示原始任務中可以被並行化部分的比例,s表示並行化的倍數,則1/(1-p p/s)表示所得的加速比。
讓我們用一個簡單的數字演算一下,假設Communication Unit搬運資料花了1秒鐘,Computing Unit需要用9秒鐘來計算,則p=0.9。假設我們增強Computing Unit的並行度,令其理論峰值提高3倍,即s=3,則Computing Unit只需要3秒鐘就可以完成計算,那麼加速比是多少呢?利用Amdahl's law可以得知加速比是2.5倍,加速比2.5小於Computing Unit的平行度倍數3。
我們嚐到了增加Computing Unit並行度的甜頭,能不能透過進一步提高並行度s來獲得更好的加速比呢?可以。譬如令s=9,那麼我們可以獲得5倍加速比,可以看到提高並行度的效益越來越小。
我們能透過無限提高s來提高加速比嗎?可以,不過越來越不划算,試想令s趨於無窮大(即令Computing Unit理論峰值無限大),p/s就趨於0,那麼加速比最大是1/(1-p)=10。
只要係統中存在不可並行的部分(Communication Unit),加速比就不可能超過1/(1-p)。
實際情況可能比加速比上限1/(1-p)要更差一些,因為上述分析假設了運算強度I無窮大,而且在增加Computing Unit並行度時,通常會使得Communication Unit的傳輸頻寬下降,就使得p更小,從而1/(1-p)更大。
這個結論令人很悲觀,即使通訊開銷(1-p)只佔0.01,也意味著無論使用多少並行單元,成千上萬,我們最大隻能獲得100倍的加速比。有沒有辦法讓p盡量接近1,也就是1-p趨近於0,進而提高加速比呢?有一枚靈丹妙藥:流水線。
5 Pipelining: 靈丹妙藥
在推導Amdahl's law時,我們假設了Communication Unit和Computing Unit串行工作,總是先令Communication Unit搬運數據,Computing Unit再做計算,計算完成再令Communication Unit搬運數據,再計算,如此循環往復。
能不能讓Communication Unit和Computing Unit同時運作,一邊搬運資料一邊計算呢?如果Computing Unit每計算完一份數據,就立刻可以開始計算下一批數據,那麼p就幾乎是1,無論並行度s提高多少倍,都能獲得線性加速比。讓我們研究一下在什麼條件下可以獲得線性加速比。
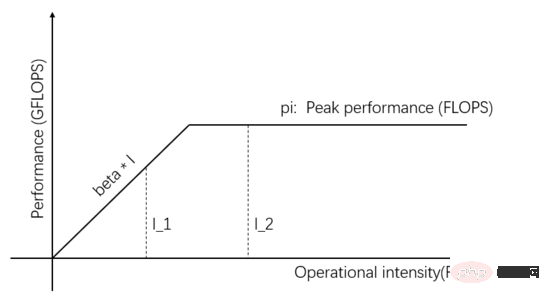
圖4:(同圖1)Roofline Model
圖4中的I_1是通訊受限型任務,1秒鐘Communication Unit可以搬運beta位元組的數據,處理這beta位元組Computing Unit需要的計算量是beta*I_1次操作,理論計算峰值是pi,一共需要(beta*I_1)/pi秒完成計算。
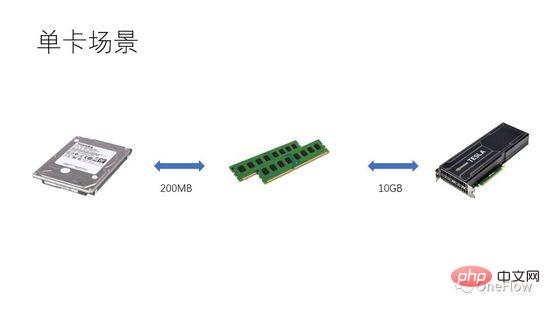
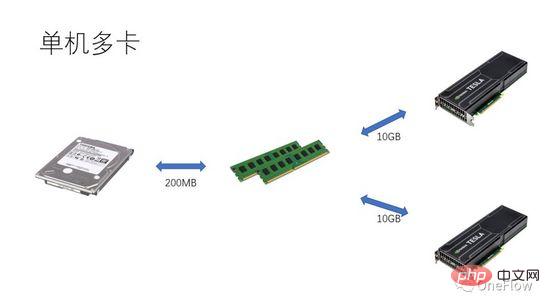
對於通訊受限型任務,我們有beta*I_1 圖4中的I_2是計算受限任務,1秒鐘Communication Unit可以搬運beta字節的數據,處理這beta字節Computing Unit需要的計算量是beta*I_2次操作,理論計算峰值是pi,總共需要(beta*I_2)/pi秒完成計算。對於計算受限型任務,我們有 beta*I_2>pi,所以Computing Unit的計算時間是大於1秒的。 這也意味著,每花1秒鐘搬運的數據需要好幾秒鐘才能計算完,在計算的時間內有充足的時間去搬運下一批數據,也就是計算時間能掩蓋住資料搬運時間,p最大是1,只要I是無限大,加速比就可以無限大。 使得Communication Unit和Computing Unit重疊工作的技術叫流水線( Pipelinging: https://en.wikipedia.org/wiki/Pipeline_(computing) )。是一種有效提高Computing Unit利用率和提高加速比的技術。 上文討論的各種量化模型對深度學習引擎研發同樣適用,譬如對於計算受限型任務,可以透過增加並行度(增加顯示卡)來加速;即使是使用相同的硬體設備,使用不同的平行方法(資料並行,模型並行或管線並行)會影響到運算強度I,從而影響實際運算效能;分散式深度學習引擎包含大量的通訊開銷和運行時開銷,如何減小或掩蓋這些開銷對於加速效果至關重要。 在Processor-centric運算裝置的視角下理解基於GPU訓練深度學習模型,讀者可以思考怎麼設計深度學習引擎來獲得更好的加速比。 在單機單卡情況下,只需要做好資料搬運和運算的管線,就可以做到GPU 100%的使用率。實際運算效能最終取決於底層矩陣運算的效率,也就是cudnn的效率,理論上各種深度學習框架在單卡場景不應該有效能差距。 如果想在同一台機器內部透過增加GPU來獲得加速,與單卡場景相比,增加了GPU之間資料搬運的複雜性,不同的任務切分方式可能會產生不同的運算強度I(譬如對卷積層適合做資料並行,對全連接層適合模型並行)。除了通訊開銷,運行時的調度開銷也會影響加速比。 多機多卡場景,GPU之間資料搬運的複雜性進一步提高,機器之間透過網路搬運資料的頻寬一般低於機器內部透過PCIe搬運數據的頻寬,這意味著並行度提高了,可數據搬運頻寬降低了,代表著Roofline model中斜線的斜率變小了,CNN這種適合數據並行的場景通常意味著比較高的運算強度I,而還有一些模型譬如RNN/LSTM,運算強度I就小很多,這也意味著管線中的通訊開銷更難以掩蓋了。 有過分散式深度學習引擎的讀者應該對軟體框架的加速比有切身的體會,基本上,卷積神經網路這種適合數據並行(運算強度I比較高)的模型透過增加GPU來加速的效果還是比較令人滿意的,然而,還有很大一類神經網路使用模型並行的運算強度才更高一點,而且即使使用模型並行,其運算強度也遠低於卷積神經網絡,對於這些應用如何透過增加GPU並行度來獲得加速是業界尚未解決的難題。 在先前的深度學習評測中,甚至發生了使用多GPU訓練RNN速度比單一GPU還要慢的情況( https://rare-technologies.com/machine-learning-hardware-benchmarks/ )。無論使用什麼技術解決深度學習引擎的效率問題,萬變不離其宗,為了提高加速比,都是為了減小運行時開銷,選擇合適的並行模式來提高運算強度,透過流水線掩蓋通訊開銷,也都在本文所描述的基本定律涵蓋的範圍之內。 6 平行計算的量化模型對深度學習引擎的啟發
7 總結
以上是平行計算的量化模型及其在深度學習引擎的應用的詳細內容。更多資訊請關注PHP中文網其他相關文章!