
聊天機器人是如何透過知識圖譜回答問題的?

- PHPz轉載
- 2023-04-17 09:13:021036瀏覽
前言
1950年,圖靈發表了具有里程碑意義的論文《電腦器與智慧》(Computing Machinery and Intelligence),提出了一個關於機器人的著名判斷原則-圖靈測試,也被稱為圖靈判斷,它指出如果第三者無法辨別人類與AI機器反應的差別, 則可以論斷該機器具備人工智慧。
2008年,漫威《鋼鐵人》中的AI管家賈維斯,讓人們知道了AI是如何精準地幫助人類(東尼)解決丟過來的各種事務的…

圖1:AI管家賈維斯(圖片來源網路)
#2023年初,以2C的方式從科技界火爆破圈的免費聊天機器人ChatGPT浪翻全球。
根據瑞銀的研報,其月活用戶在1月就達到了1億,目前還在增長著,它已成為史上增長最快的消費者應用。此外,其東家OpenAI繼前期發布了每月42美元的專業版Pro後,馬上就要推出Plus版,據說每月約20美元。
當一件新事物,月活上億,流量上來,並且開啟商業變現之後,你是否對它背後的各種技術感到好奇?例如,聊天機器人是如何處理和查詢大量資料的?
體驗過ChatGPT的朋友都有同感,它顯然比天貓精靈或小愛童鞋更聰明——是一個「有著無敵話術」聊天機器人,一個自然語言處理工具,一個大型語言模型,也是一個人工智慧應用。它可以根據提問素材的上下文與人類互動,可以進行推理和創作,甚至會拒絕(它認為)不當的問題,不只是完成擬人化的交流。
雖然目前對它的評價褒貶不一,但從技術發展的視角來說,它甚至有可能通過圖靈測試。試問,在我們與它交流的時候,其(對於小白而言)廣博的知識,可甜可油的回答,如果在我們完全不知情的前提下,是很難辨別出對方是人類還是機器( 或許這才是它危險的地方-ChatGPT 的核心仍屬於深度學習範疇,存在大量黑盒子與不可解釋性!)。
那麼,聊天機器人是怎麼做到將來自3000 億單字的訓練語料庫和1750 億的參數,快速地進行整理和輸出的呢,同時還能做到結合上下文,根據它「掌握」的知識,自由應對與人類的交流的呢?
其實,聊天機器人也有大腦,它跟我們人類一樣,需要學習 訓練。
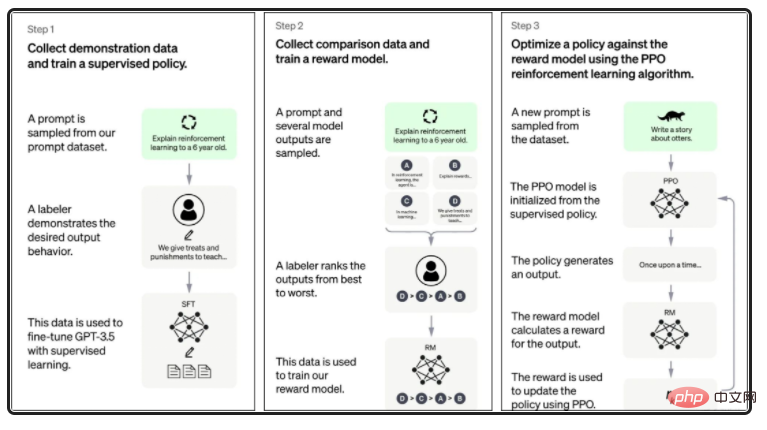
圖2:ChatGPT 學習訓練圖(來源官網)
它將海量的文字、圖片等等非結構化的文件,透過NLP(自然語言處理)、目標辨識、多模態辨識等,依其語意結構化成知識圖譜,而這個知識圖譜就是聊天機器人的大腦了。

圖3:以醫療為例,人工智慧將多來源的資料轉化在問答、搜尋、藥物研發等場景的知識圖譜中
知識圖譜是由什麼組成的呢?
知識圖譜是由什麼組成的呢?它是由點(實體)和邊(關係)組成的,能夠將人、事、物等相關資訊整合,形成一個全面的圖,如下圖。
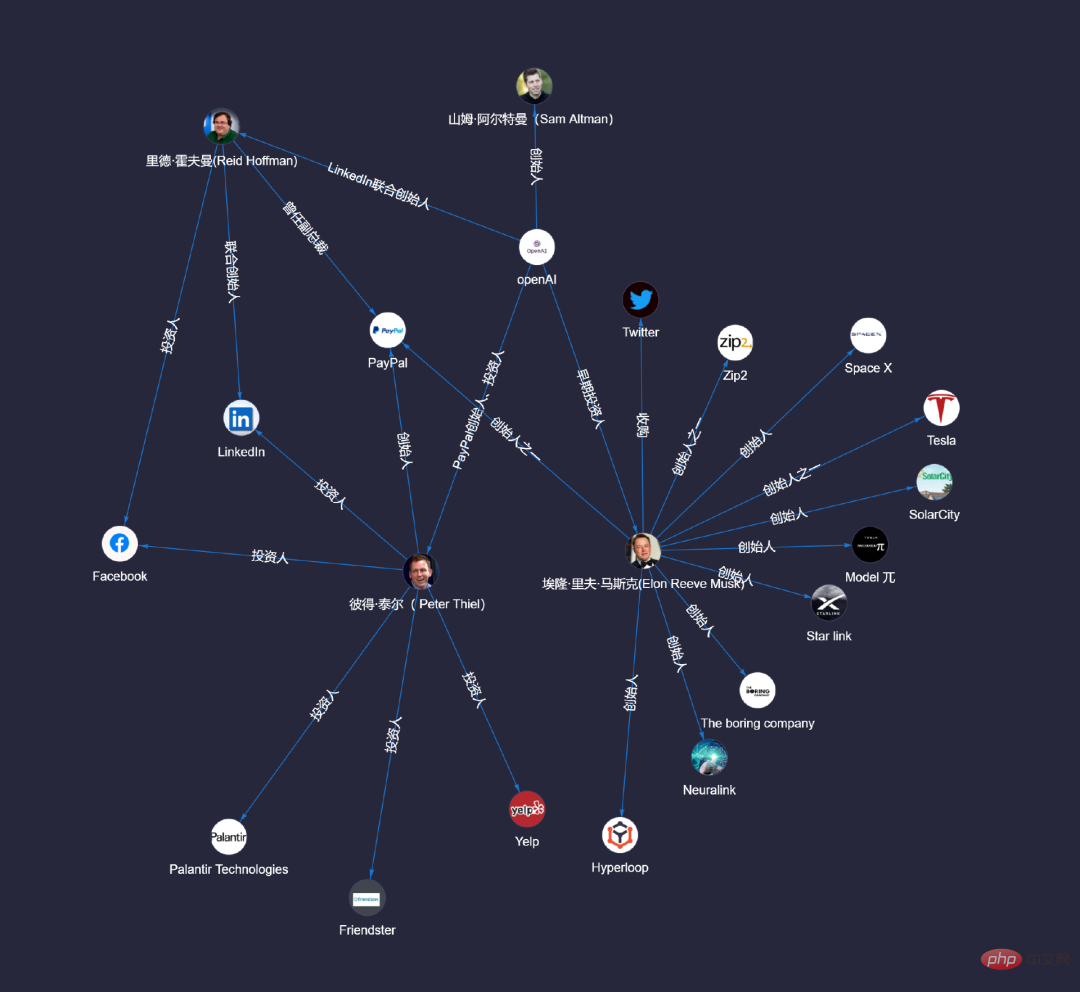
圖4:由人物的點和屬性邊構成的圖譜(子圖)
當提問“OpenAI 的創始人是誰呀?”,聊天機器人的大腦就開始迅速地在自己的知識庫裡搜索、查找,先從用戶的問句中,鎖定目標點“penAI”,再根據用戶的提問,連鎖出另一個點——創始人“山姆·阿爾特曼”。
圖5:從點「OpenAI」透過一邊連接到另一個點「山姆·阿爾特曼」
其實,當我們在提「OpenAI的創始人是誰"的時候,聊天機器人就會在自己的知識庫中,把所有圍繞該點的圖都關聯出來。所以,當我們問到相關問題的時候,它其實早已預判了我們的預判。例如當我們問:「馬斯克是OpenAI的創始團隊成員嗎?」僅僅一個指令的發出,它已經將所有的成員都查詢了(舉千反一),見下圖。
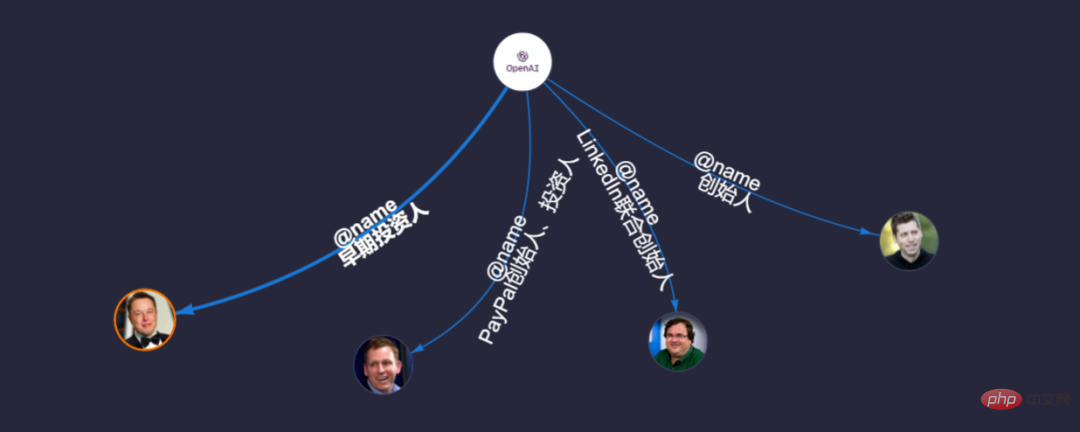
圖6:由點「OpenAI」關聯到其他人物
此外,在它的庫裡如果還收錄過其他的“學習資料”,那麼在其的“大腦”中還會關聯著諸如“人工智能機器人的產品有哪些?”等相關的圖,如下圖。

圖7:常見的AI機器人產品圖譜
當然,聊天機器人和人一樣,回答問題會受到自身知識儲備的限制,如見下圖:
#我們知道,決定一個人大腦快不快、聰明不聰明的判斷是什麼呢?從人類的角度來看,最簡單的標準就是是否具備舉一反三的能力。
子曰:「不憤不啟,不悱不發,舉一隅不以三隅反,則不復也。」
#-論語·述而篇
早在兩千年前,孔子就強調過善於舉一反三、由此及彼、觸類旁通的重要性。而對於聊天機器人來說,其答案的品質取決於建立知識圖譜的算力。
我們知道,通用的知識圖譜的建構在很長一段時間內都著重在NLP和視覺化呈現等方面,但忽略了計算時效性、資料建模靈活性、查詢(計算)過程與結果可解釋性等問題。尤其是在整個世界從大數據時代向深數據時代轉型的當下,過去傳統的基於SQL或NoSQL構建的圖譜的缺陷,已無法高效去處理海量、複雜、動態的數據的能力,更何談進行關聯、挖掘和分析的洞察力?那麼,傳統知識圖譜面臨的挑戰都有什麼特性呢?
一是,低算力(低效)。採用SQL 或 NoSQL 資料庫系統建構的知識圖譜底層架構效率低下,無法高速處理高維度資料。
二是,彈性差。基於關係型資料庫、文件資料庫或低效能圖資料庫建構的知識圖譜通常受制於底層架構而無法有效率地還原實體間的真實關係。諸如,它們有些只支援簡單圖,錄入多邊圖資料時要不是資訊容易遺失,就是花高代價來構圖。
三是,徒有其表。在2020 年之前, 極少有人真正關注底層算力,幾乎所有的知識圖譜系統建設,都僅僅是圍繞 NLP 和可視化這兩部分。而沒有底層算力支撐的知識圖譜,只是在本體與三元組的抽取和構建,並不具備解決深度的查詢、速度和可解釋性等問題的能力。
【註:在這裡,我們不展開講傳統關係型資料庫與圖資料庫之間的效能對比,有興趣的讀者可閱讀:圖資料庫與關係型資料庫的差異?和 圖資料庫解決了什麼問題? 】
行文至此,我們已經從聊天機器人的智慧知識圖譜話題,聊到了另一個前沿技術──圖資料庫(圖計算)技術領域了。
什麼是圖資料庫(圖計算)呢?
圖資料庫#【參考參考資料1】是一種應用圖理論,可以儲存實體的屬性資訊與實體之間的關係訊息,在定義方面,圖#(Graph)是以節##點
##【參考參考資料2】和
邊#【參考參考資料2】定義的資料結構。
圖是知識圖譜儲存與應用服務的基礎,擁有強大的資料關聯及知識表達能力,因此倍受學術界與產業界的推崇。
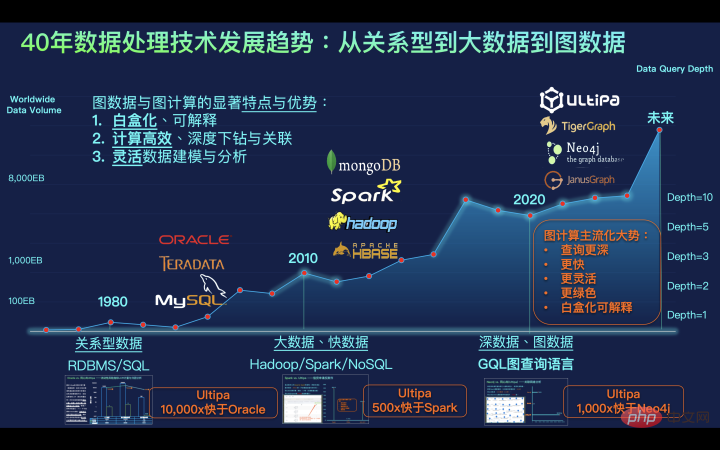
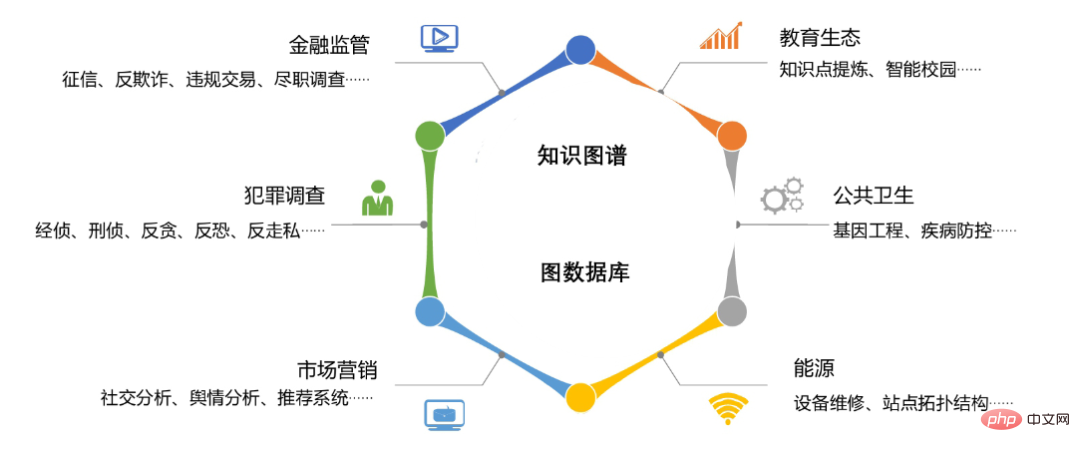
圖8:圖資料庫與知識圖譜在行銷、犯罪調查、金融監理、教育生態、公共衛生和能源等領域中的應用場景
如上圖所示,我們看到,在即時圖資料庫(圖計算)引擎的幫助下,產業界可以即時地在不同數據間找到深度關聯的各種關係,甚至可以找到最優的、人腦都無法企及的智慧途徑──這就是源自於圖資料庫的高維度。
何為高維度?圖不僅作為一種符合人類大腦思維習慣、能對現實世界進行直覺建模的工具,同時能夠建立起深刻的洞察(深圖遍歷)力。 
 諸如大家都知道“蝴蝶效應”,就是在海量的數據和資訊的中,去捕捉看似毫無關係的兩個以上的實體之間的微妙關係,這從資料處理架構的角度來看,如果沒有圖資料庫(圖計算)技術的幫助是極難實現的。 【註:對圖資料庫與圖計算到底如何區分的話題,此處不展開,有興趣的朋友可閱讀:來自「圖」的挑戰是什麼?如何區分圖資料庫與圖計算?一文速解】
諸如大家都知道“蝴蝶效應”,就是在海量的數據和資訊的中,去捕捉看似毫無關係的兩個以上的實體之間的微妙關係,這從資料處理架構的角度來看,如果沒有圖資料庫(圖計算)技術的幫助是極難實現的。 【註:對圖資料庫與圖計算到底如何區分的話題,此處不展開,有興趣的朋友可閱讀:來自「圖」的挑戰是什麼?如何區分圖資料庫與圖計算?一文速解】
圖9:過去40年來,資料處理技術的發展趨勢是從關係型到大數據再到圖表資料
#########風控就是典型的場景之一。 2008年的金融危機,其導火線僅僅是美國第四大投行雷曼兄弟倒閉了,但誰也沒有料到,一家擁有158年曆史的投行的倒閉,會引起國際銀行業後續的一系列倒閉風潮…其影響之廣、範圍之大,讓人始料未及;而即時圖資料庫(圖計算)技術,就可以找到關於風險的所有關鍵的節點、風險因子,風險傳播路徑…進而對整個金融風險進行提前預警。 #####################################圖10:雷曼兄弟(Lehman Brothers)破產傳播路徑以及風險客群圖譜############【註:以上構圖,皆在Ultipa Manager上完成。願意進一步學習和探索的朋友,可以閱讀系列文章之一: 走進 Ultipa Manager之高視覺化】######要指出的是,時下,儘管很多廠商都可以建構知識圖譜,但現實是每100 家圖譜公司中,用(高效能)圖資料庫來做算力支撐的不足5 家(低於5%)。
Ultipa嬴圖資料庫是目前全球唯一的第四代即時圖資料庫,透過高密度並發、動態剪枝、多級儲存運算加速等創新性的專利技術實現了對任意量級資料集的超深度即時下鑽。
一是,高算力。
以找出企業最終受益人(又稱實際控制人、大股東)為例。此類問題的挑戰在於,現實世界中,最終受益人與被檢查公司實體之間,經常相隔許多節點(空殼公司實體),又或者多個自然人或公司實體之間通過多個投資、參股路徑對其它公司進行控制。傳統的關係型資料庫或文件資料庫,甚至多數的圖資料庫,都無法即時解決這類圖譜穿透問題。
Ultipa嬴圖即時圖資料庫系統解決了上述許多挑戰。其高並發資料結構與高效能運算與儲存引擎,相較於其他圖系統能以100 倍甚至更快的速度進行深度挖掘,即時(微秒以內)找到最終受益人或發現龐大的投資關係網路。另一方面,微秒級的時延意味著更高的並發性和系統吞吐量,相較於那些宣稱毫秒延遲的系統,這是 1000 倍的效能提升!
以現實場景為例,原中信銀行行長孫德順利用開設多個「影子公司」的方式,借助金融手段來完成利益輸送。
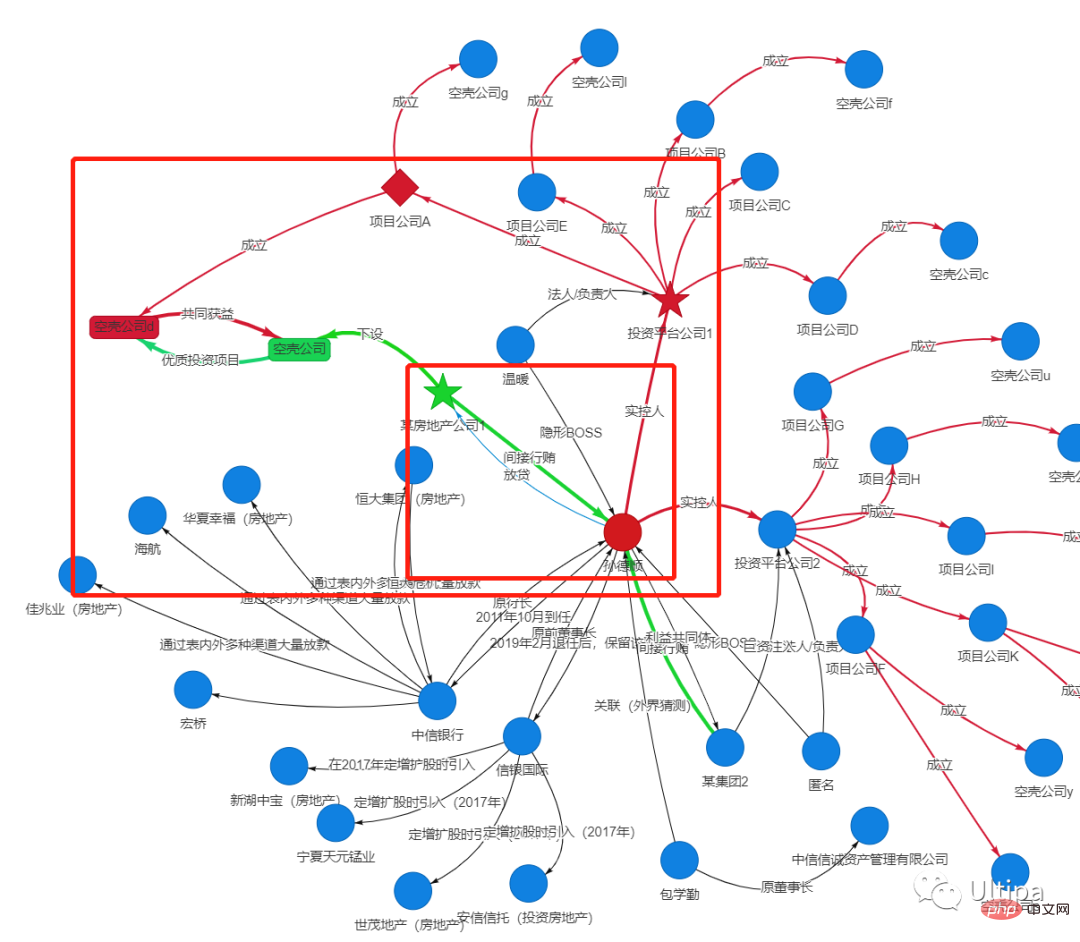
圖11:孫德順設計了結構極為複雜的重重“防火牆”,多層影子公司層層嵌套,以規避監管,獲取利益

#圖12:關聯:孫德順-中信銀行-企業老闆-(空殼公司)投資平台公司-孫德順
如上圖,孫德順利用中信銀行的公權力為企業老闆
#批貸款;與此對應,企業老闆或以投資名義或送上優質的投資項目、投資機會等等方式;雙方透過各自成立的空殼公司
完成直接交易;或企業老闆將巨資注入孫德順實控的投資平台公司
,然後平台公司再用這些資金投到老闆提供的專案內,從而以錢生錢,大家共同獲利分紅,最終形成利益共同體。
Ultipa嬴圖即時圖資料庫系統,透過白盒子穿透的方式,挖掘出層層錯綜複雜的人與人、人與企業、企業與企業之間的複雜關係,並即時鎖定最終的幕後人。
#########二是,靈活性。 ###############圖譜系統的彈性可以是個非常廣泛的議題,大體包含資料建模、查詢與運算邏輯、結果呈現、介面支援、可擴展性等幾個部分。 ############資料建模是所有關係圖譜的基礎,與圖系統(圖資料庫)的底層能力息息相關。例如,基於ClickHouse 這種列資料庫建構的圖資料庫系統,根本無法承載金融交易圖譜,因為交易網路最典型的特徵就是兩個帳戶間存在多次轉賬,但ClickHouse 傾向於將多次轉帳合併為一,這種不合理的做法會導致數據混淆(失真)。有些基於單邊圖理念建構的圖資料庫系統,則傾向於以頂點(實體)來表達交易,結果是資料量被放大(儲存浪費),並且造成圖譜查詢的複雜度指數級增大(時效性變差)。 ######介面支援層面則與使用者體驗相關。舉個簡單的例子,如果一個生產環境下的圖系統只支援CSV格式,那麼所有的資料格式都要先轉換為CSV格式才能入圖,效率顯然太低,然而這在許多圖譜系統中卻是真實存在的。
查詢與運算邏輯的彈性又如何呢?我們仍以「蝴蝶效應」為例:圖譜中任兩個人、事或物之間是否存在某種冥冥中的因果(強關聯)效應?如果只是簡單的1 步驟關聯,任何傳統的搜尋引擎、大數據NoSQL 框架甚至關係型資料庫都可以解決,但如果是深度的關聯關係,例如牛頓和成吉思汗之間有什麼關聯關係,這又該如何計算呢?
Ultipa嬴圖即時圖資料系統,可以提供不只一種方法來解決上述問題。例如點到點的深度路徑搜索、多點間的組網搜索、基於某種模糊搜索條件的模板匹配搜索,還有類似於Web搜索引擎的面向圖譜的模糊文本路徑搜索。
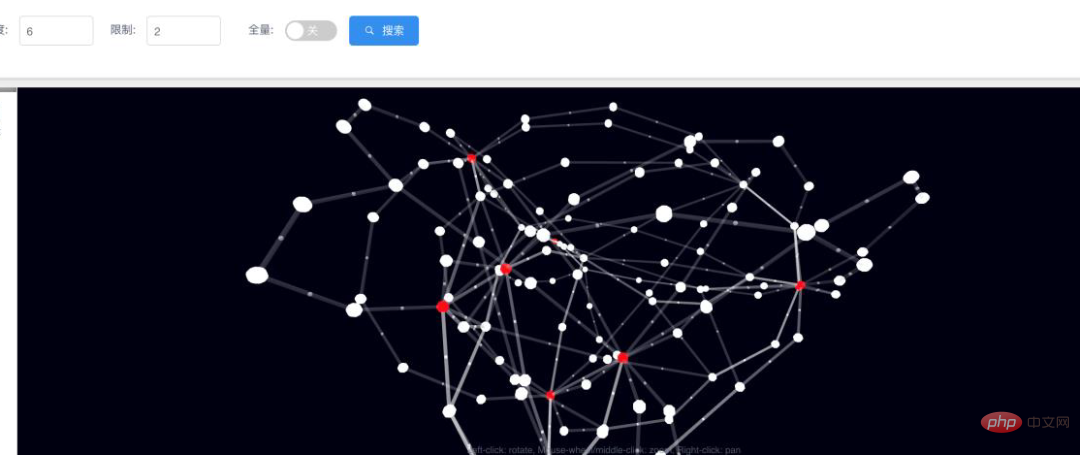
圖13:某大圖中即時群組網的視覺化結果(形成子圖)搜尋深度≥ 6跳
圖譜上還有其它很多必須依賴高靈活性與算力才可以完成的工作,例如依據靈活的過濾條件尋找點、邊、路徑;模式識別,社區、客群發現;尋找節點的全部或特定鄰居(或遞歸地發現更深的鄰居);找到圖中具有相似屬性的實體或關聯關係……總之,沒有圖算力支撐的知識圖譜就像是沒有靈魂的軀殼,空有其表。無法完成種種具有挑戰性、深度搜尋能力的事務。
三是,低程式碼,所見即所得。
圖譜系統除了上述的高算力與彈性以外,還需要有白盒化(可解釋性)、表單化(低程式碼、無程式碼)以及以所見即所得的方式賦能業務的能力。

圖14:零程式碼一鍵查找,只需填入搜尋範圍的數值即可,且2D、3D 、清單、表格甚至是異質資料融合的多種視覺模式靈活轉換
在Ultipa嬴圖即時圖資料庫系統中,開發人員只需敲1句Ultipa GQL就可以完成操作,而業務人員則是使用預置的表單化外掛程式透過零程式碼的方式就可以實現對業務的查詢。這種方式,大大助力員工提高了工作效率,同時賦能機構降低了營運成本,並打通了部門之間的溝通壁壘。
綜上所述,知識圖譜與圖資料庫的結合將會幫助各行各業加速實現資料中台的業務建設,但諸如金融業這種需要專業性、安全性、穩定性、即時性、精準性的產業,採用關係型資料庫來支撐上層應用並不能提供良好的資料處理效能,甚至無法完成資料處理任務,因此只有實現具有即時、全面、深度穿透、逐筆追溯、精準計量的監測和預警性能的圖數據庫(圖計算)技術,才可能賦能組織更好地運籌帷幄且決勝千里!
行文至此,突然想起了熱播的《三體》,其中提到了一個非常有意思的點-智子鎖死。大概意思是說,三體文明為了防止地球科技超過它,就透過鎖死人類基礎科學的方式進行各種阻礙。因為人類文明的飛躍,取決於基礎科學的發展和重大突破,鎖死人類的基礎科學就等於堵塞了地球提昇文明等級的道路……當然,筆者想告訴大家的是,圖技術就屬於人工智慧的基礎設施之一,準確的說是圖技術=增強智能可解釋AI,它是AI 與大數據發展過程中融合的必然產物。
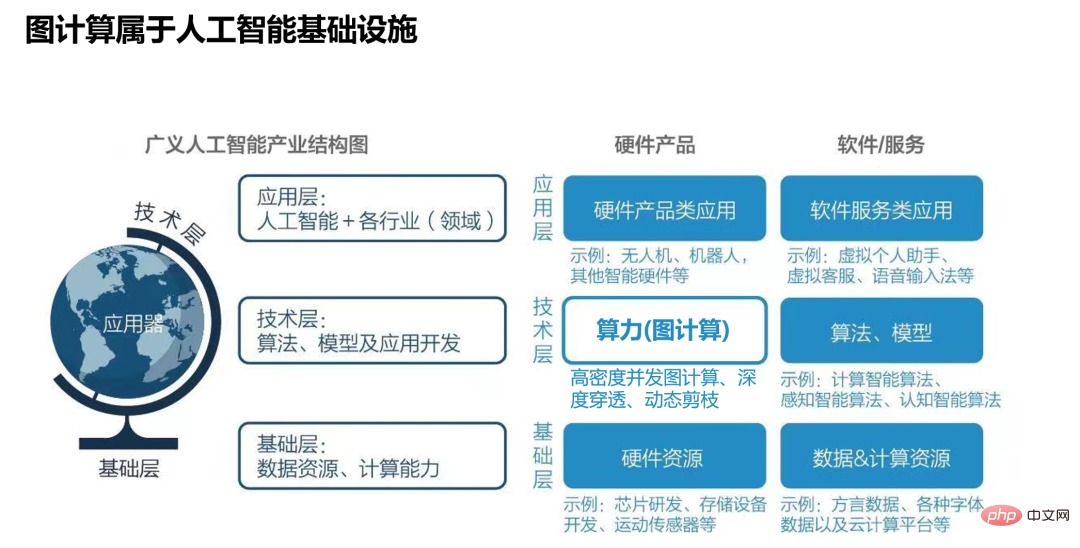
圖15:圖資料庫(圖計算)技術,屬於人工智慧基礎設施
#以上是聊天機器人是如何透過知識圖譜回答問題的?的詳細內容。更多資訊請關注PHP中文網其他相關文章!