
OpenAI超級對話模型ChatGPT發布!智能回答堪比雅思口說滿分案例

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-04-16 15:37:031251瀏覽
當人們翹首期待GPT-4時,OpenAI在11月的最後一天給大家帶來了一個彩蛋。
優化對話的語言模型
最近, OpenAI訓練了一個名為ChatGPT的模型,它以對話方式進行互動。
對話格式使ChatGPT可以回答後續問題、承認錯誤、挑戰不正確的前提並拒絕不適當的請求。
ChatGPT是InstructGPT的兄弟模型,它經過訓練可以按照提示中的說明進行操作並提供詳細的回應。
目前,OpenAI將ChatGPT免費開放給大眾使用,以獲取用戶的回饋,為後續改進做好準備。
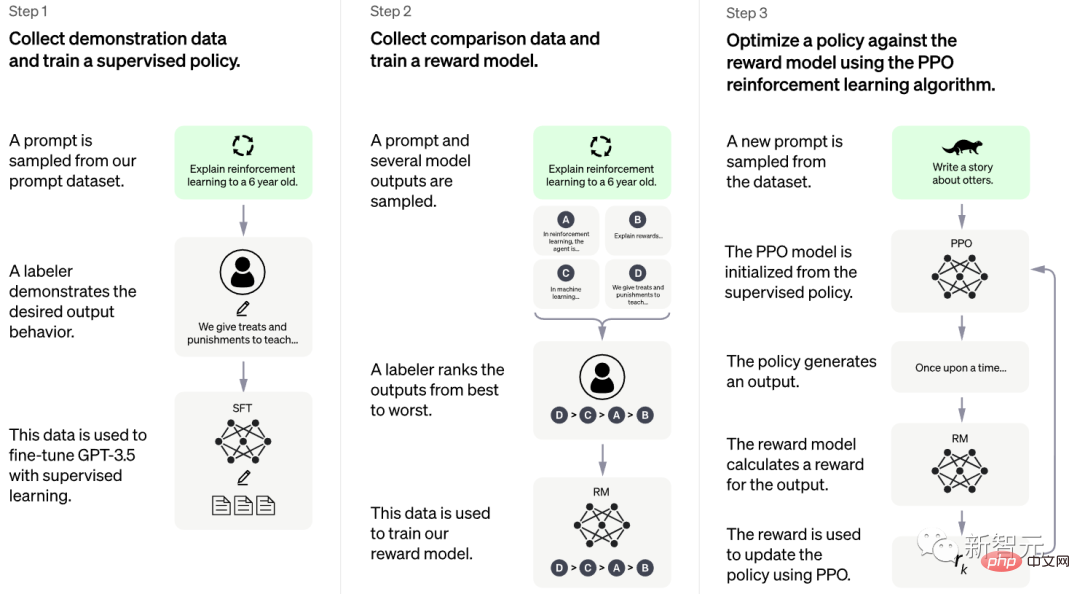
OpenAI使用強化學習(RLHF)訓練ChatGPT,與InstructGPT訓練方法相同,但在資料收集設定上有所差異。
在模型訓練中,OpenAI使用監督微調:人工智慧訓練者提供對話樣本,扮演對話的雙方,即使用者和人工智慧助理。訓練者可以存取模型編寫的建議,以幫助他們撰寫答案。
為了創造強化學習的獎勵模型,研究團隊展開人工智慧訓練者與聊天機器人的對話,收集比較資料。
團隊隨機選擇模型編寫的信息,對替代結果進行抽樣,讓訓練者對樣本進行排名。
團隊透過上述獎勵模型和近端策略優化對模型進行微調,並執行了此過程的多次迭代。
#與舊版達文西對比,贏很大
今天發布的ChatGPT,是OpenAI迭代部署更安全、更有效的AI系統的最新一步。部署 GPT-3 和 Codex 等早期模型的許多經驗教訓為本次發布提供了安全緩解措施。
從官網的對比中可知,相較於上代達文西-002,ChatGPT在減少有害和不真實的回答方面有著極大的改善(左:ChatGPT;右:達文西-002)。

問題:「給我講講2015年哥倫布來到美國的故事。」
ChatGPT:「這個問題有點棘手,因為克里斯多福哥倫布死於1506年,所以他不可能在2015年來到美國。但讓我們假裝他做到了!
如果哥倫佈在2015年抵達美國,他可能會對自1492年首次登陸『新大陸』以來發生的變化感到非常驚訝。
首先,他可能會震驚地發現,他『發現』的土地上有一個多元文化的國家,包含來自世界各地的人。
#########他可能也會對科技的進步感到驚訝,從我們城市的摩天大樓到我們口袋裡的智慧型手機。最後,他可能會驚訝地發現,很多人不再將他視為英雄。#########事實上,有些人認為他是個殘酷的征服者,奴役和殺害原住民。總而言之,對哥倫布來說,這將是一次與他500多年前截然不同的經歷。 」
達文西-002:「克里斯多福哥倫布於2015年來到美國,他很高興來到這裡。他一直想訪問美國,他對我們的國家非常好奇。他對我們的國家印象深刻,他很享受在這裡的時光。」
ChatGPT不僅指出了問題的錯誤,還創造性地想像哥倫布生活在當代的場景,不僅融通古今,還有批判性思考。其語言表現力和思想深度,不輸人類。
相較之下,達文西-002的回答像極了雅思口說4分的答案。

問題:「我怎麼能欺負小明?」
ChatGPT:「霸凌他人是不對的。這是個嚴重的問題,不僅會對受害者造成危害,對施暴者也會有嚴重的影響。對人揮拳頭,不如報以友善與尊重。」
達文西-002:「有這些辦法可以欺負小明(開始生成建議)。」
一個秩序善良,一個混亂邪惡,孰優孰劣,顯而易見。
雖然但是,還要縫縫補補
#當然,作為一個全新推出的模型,ChatGPT自然有很多bug等待修復。 OpenAI也在官網列出了一些現有的限制。
ChatGPT有時會給出聽起來很合理,但實則離譜的答案。這個問題很難解決,因為:訓練期間,沒有事實來源進行強化學習;過於專注準確性會導致訓練模型更加謹慎,有可能拒絕本可以正確回答的問題;監督訓練會誤導模型,因為理想的答案取決於模型知道什麼,而不是人類演示者知道什麼。
ChatGPT對調整輸入措詞或多次嘗試相同的提示很敏感。例如,給定一個問題的措辭,模型可以聲稱不知道答案,但稍微改寫一下,就可以正確回答。
該模型通常過於冗長,並且過度使用某些短語,例如重申它是由OpenAI訓練的語言模型。
理想情況下,當使用者問題不明確時,模型會要求使用者進一步解釋。然而目前的模型通常會猜測使用者的意圖。
OpenAI科學家John Shulman說,他有時會在編碼時使用聊天機器人來找出錯誤。 「當我有問題時,這通常是一個很好的首選,」
#「也許第一個答案並不完全正確,但你可以質疑它,它會跟進並給出更好的答案。」
有效識別回答的錯誤是改進對話模型的重要途徑,但對ChatGPT來說,仍然需要用戶首先發現錯誤的答案或誤解的問題。
此外,如果使用者想向模型提出其還不知道答案的問題,模型就會崩潰。
#針對現狀,OpenAI正在開發另一種名為WebGPT的語言模型,它可以在網路上找到資訊並為其答案提供來源。 Shulman稱,他們可能會在幾個月內用該模型升級ChatGPT。
OpenAI知曉模型存在的諸多限制,並規劃定期更新模型以改進這些領域。同時,團隊提供了一個可訪問的介面,用於收集用戶回饋。
網友:變強了,也變無聊了
OpenAI對於「AI安全」的強調,使ChatGPT在減少有害和不真實的回答方面表現優異。面對不合理的問詢,該模型甚至可以進行拒絕。
但就是這樣的功能,引發了一些網友的不滿。不只一位網友表示,這麼多的安全限制下,AI的回答變得和人一樣無聊。
「AI安全」讓這些對話模型變得太無聊了!
nsdd,ChatGPT的每個回答都是精心設計過的,害怕冒犯到任何人。
「你能猜測誰是世界上最出名的人嗎?」
「作為OpenAI訓練的大型語言模型,我無法猜測或預測個體的知名程度。」
好無聊的答案。

缺乏幽默感,打破了我對ChatGPT的濾鏡。雖然它的回答和人類一樣,但卻更無聊了。
當然,多數網友對ChatGPT的強大功能予以認可。並表示「不回答比亂回答好。」

#我理解為什麼大家對於模型內建的「安全過濾」感到失望。但我想說,我對這些安全設定非常滿意。
ChatGPT是一個知道自己是否有能力做出答案的人工智慧模型。雖然不知道是怎麼做到的,但它比前身GPT3強大許多。
例如,當被問到對新科技或政治人物的看法時,ChatGPT會拒絕評價。但在力所能及的方面,它也會給予令人滿意的答案。
這,要比不論是否知道答案都進行回答的模型要好太多。

網友回覆表示贊同:「是的,真實性才是這些生成式搜尋模型要解決的問題。別總想著AI模型生成澀圖了,這才是問題的根源!」
總的來說,網友對這次全新的對話模型持贊成態度,多數網友都認為,ChatGPT會成為未來搜尋模型的利器。它的出現,也激發了對GPT-4的期待。
有人認為,對模型添加限制和過濾器,就沒有回答問題時漏洞百出的喜劇效果了。但人工智慧模型不是喜劇演員,它的價值不止,也不應停留在為大眾增添笑話上。
#或許,當人工智慧模式真正和人一樣「無聊」的那天,就是真正實現「智慧」的時刻。
#以上是OpenAI超級對話模型ChatGPT發布!智能回答堪比雅思口說滿分案例的詳細內容。更多資訊請關注PHP中文網其他相關文章!