
十個 Python 小技巧,涵蓋了90%的資料分析需求!

- 王林轉載
- 2023-04-12 08:04:021144瀏覽
資料分析師日常工作會涉及各種任務,例如資料預處理、資料分析、機器學習模型創建、模型部署。
在本文中,我將分享10個 Python 操作,它們可涵蓋90%的資料分析問題。有所收穫按讚、收藏、關注。
1、閱讀資料集
閱讀資料是資料分析的組成部分,了解如何從不同的檔案格式讀取資料是資料分析師的第一步。以下是如何使用 pandas 讀取包含 Covid-19 資料的 csv 檔案的範例。
import pandas as pd
# reading the countries_data file along with the location within read_csv function.
countries_df = pd.read_csv('C:/Users/anmol/Desktop/Courses/Python for Data Science/Code/countries_data.csv')
# showing the first 5 rows of the dataframe
countries_df.head()
以下是countries_df.head() 的輸出,我們可以使用它來查看資料框的前5 行:
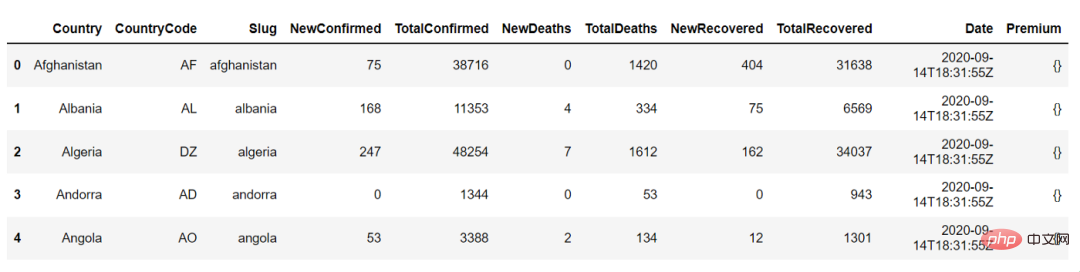
2、總計統計
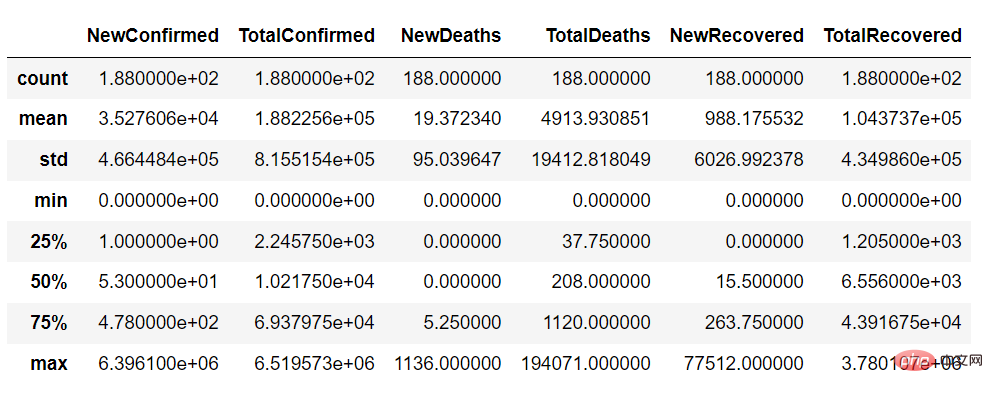
下一步就是透過查看數據匯總來了解數據,例如NewConfirmed、TotalConfirmed 等數字列的計數、平均值、標準偏差、分位數以及國家代碼等分類列的頻率、最高出現值
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">countries_df</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">describe</span>()
使用describe 函數,我們可以得到資料集連續變數的摘要,如下所示:
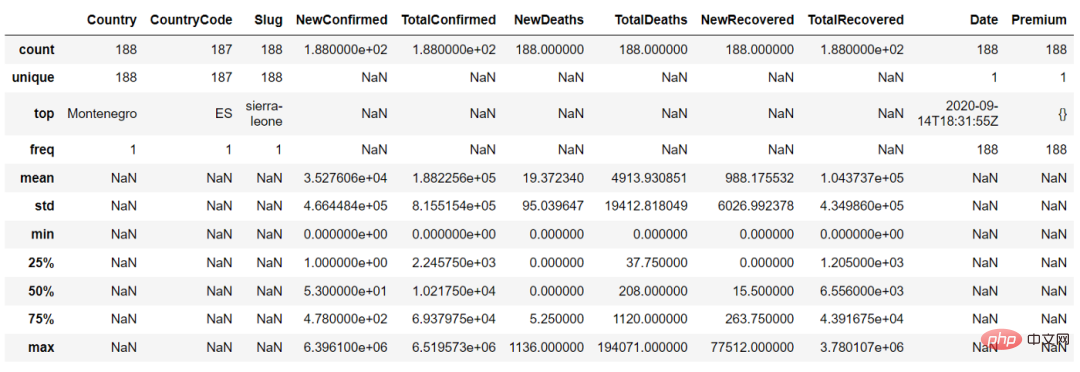
在describe() 函數中,我們可以設定參數"include = ' all'"來取得連續變數和分類變數的摘要
countries_df.describe(include = 'all')
#3、資料選擇和過濾
分析其實不需要資料集的所有行和列,只需要選擇感興趣的列並根據問題過濾一些行。
例如,我們可以使用以下程式碼選擇Country 和NewConfirmed 欄位:
countries_df[['Country','NewConfirmed']]
我們也可以將資料過濾Country,使用loc,我們可以根據一些值過濾列,如下所示:
countries_df.loc[countries_df['Country'] == 'United States of America']

4、聚合
計數、總和、平均值等資料聚合,是資料分析最常執行的任務之一。
我們可以使用聚合來找到各國的 NewConfimed 病例總數。使用 groupby 和 agg 函數執行聚合。
countries_df.groupby(['Country']).agg({'NewConfirmed':'sum'})5、Join
使用 Join 運算將 2 個資料集組合成一個資料集。
例如:一個資料集可能包含不同國家的 Covid-19 病例數,另一個資料集可能包含不同國家的緯度和經度資訊。
現在我們需要結合這兩個訊息,那麼我們可以執行如下所示的連接操作
countries_lat_lon = pd.read_excel('C:/Users/anmol/Desktop/Courses/Python for Data Science/Code/countries_lat_lon.xlsx')
# joining the 2 dataframe : countries_df and countries_lat_lon
# syntax : pd.merge(left_df, right_df, on = 'on_column', how = 'type_of_join')
joined_df = pd.merge(countries_df, countries_lat_lon, on = 'CountryCode', how = 'inner')
joined_df6、內建函數
了解數學內建函數,如min()、max()、mean()、sum() 等,對於執行不同的分析非常有幫助。
我們可以透過呼叫它們直接在資料幀上應用這些函數,這些函數可以在列上或在聚合函數中獨立使用,如下所示:
# finding sum of NewConfirmed cases of all the countries
countries_df['NewConfirmed'].sum()
# Output : 6,631,899
# finding the sum of NewConfirmed cases across different countries
countries_df.groupby(['Country']).agg({'NewConfirmed':'sum'})
# Output
#NewConfirmed
#Country
#Afghanistan75
#Albania 168
#Algeria 247
#Andorra0
#Angola537、使用者自訂函數
我們自己寫的函數是使用者自訂函數。我們可以在需要時透過呼叫該函數來執行這些函數中的程式碼。例如,我們可以建立一個函數來新增2 個數字,如下所示:
# User defined function is created using 'def' keyword, followed by function definition - 'addition()' # and 2 arguments num1 and num2 def addition(num1, num2): return num1+num2 # calling the function using function name and providing the arguments print(addition(1,2)) #output : 3
8、Pivot
Pivot 是將一列行內的唯一值轉換為多個新列,這是很棒的數據處理技術。
在Covid-19 資料集上使用pivot_table() 函數,我們可以將國家名稱轉換為單獨的新列:
# using pivot_table to convert values within the Country column into individual columns and # filling the values corresponding to these columns with numeric variable - NewConfimed pivot_df = pd.pivot_table(countries_df,columns = 'Country', values = 'NewConfirmed') pivot_df
9、遍歷資料框
#很多時候需要遍歷資料框的索引和行,我們可以使用iterrows 函數遍歷資料框:
# iterating over the index and row of a dataframe using iterrows() function
for index, row in countries_df.iterrows():
print('Index is ' + str(index))
print('Country is '+ str(row['Country']))
# Output :
# Index is 0
# Country is Afghanistan
# Index is 1
# Country is Albania
# .......10、字串操作
很多時候我們處理資料集中的字串列,在這種情況下,了解一些基本的字串操作很重要。
例如如何將字串轉換為大寫、小寫以及如何找到字串的長度。
# country column to upper case countries_df['Country_upper'] = countries_df['Country'].str.upper() # country column to lower case countries_df['CountryCode_lower']=countries_df['CountryCode'].str.lower() # finding length of characters in the country column countries_df['len'] = countries_df['Country'].str.len() countries_df.head()
以上是十個 Python 小技巧,涵蓋了90%的資料分析需求!的詳細內容。更多資訊請關注PHP中文網其他相關文章!